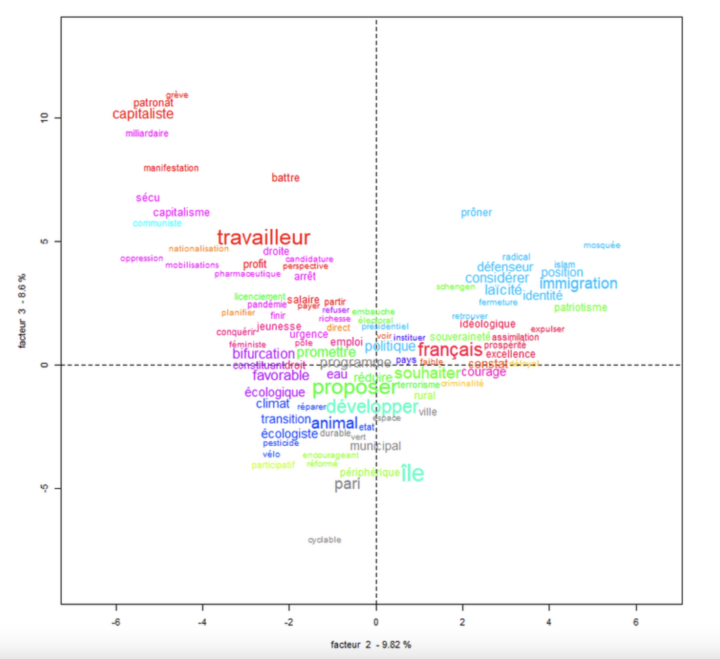
L’Analayse Factorielle des Correspondance (AFC), développée dans les années 1960 par le statisticien français Jean-Paul Benzécri, est une méthode statistique qui permet de réduire la dimensionnalité des données tout en mettant en évidence les relations entre les variables d’un tableau de contingence. À titre d’exemple, on peut citer le travail de Pascal Marchand (LERASS...