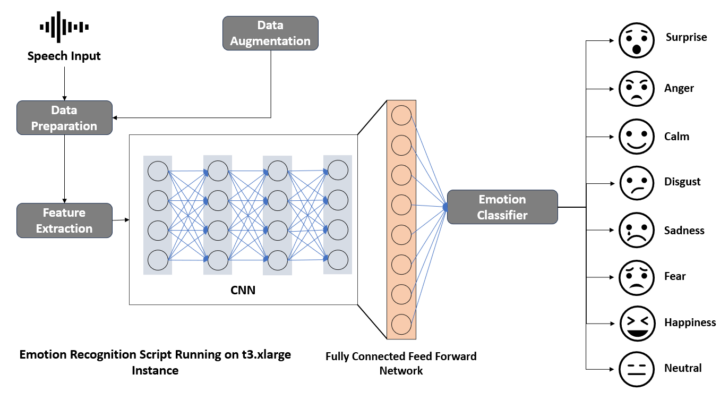
L’objectif de cet article est de construire un modèle pour réaliser une détection des émotions à partir de la voix (SER – Speech Emotion Recognition) afin d’analyser des segments audio spécifiques, comme par exemple un discours politique de Donald Trump.
La première étape consiste à concevoir et entraîner un modèle pour réaliser cette analyse émotionnelle.
Cette article constitue (aussi) une exploration au sein d’un projet plus vaste intégrant une approche multimodale (Étude conjointe/synchronisée des indices vocaux, textuels et visuels) en sciences humaines et sociales (SHS).
L’intégralité du script se trouve ICI.
Pour ce faire, j’utiliserai le dataset RAVDESS.
Bien que des alternatives telles que IEMOCAP soient souvent considérées comme mieux structurées, l’accès à ce jeu de données nécessite un mail “universitaire” pour recevoir le DataSet.
Une autre option, le dataset TESS, est également intéressant mais limité à des dialogues prononcés exclusivement par des femmes, ce qui le rend moins généraliste.
Le choix du dataset RAVDESS, bien qu’imparfait, répond au besoin pédagogique de l’article, de plus, de nombreux scripts exploitent déjà ce dataset (Scripts qui m’ont servi de source d’inspiration).
Le script est conçu pour être exécuté à partir de Google Colab.
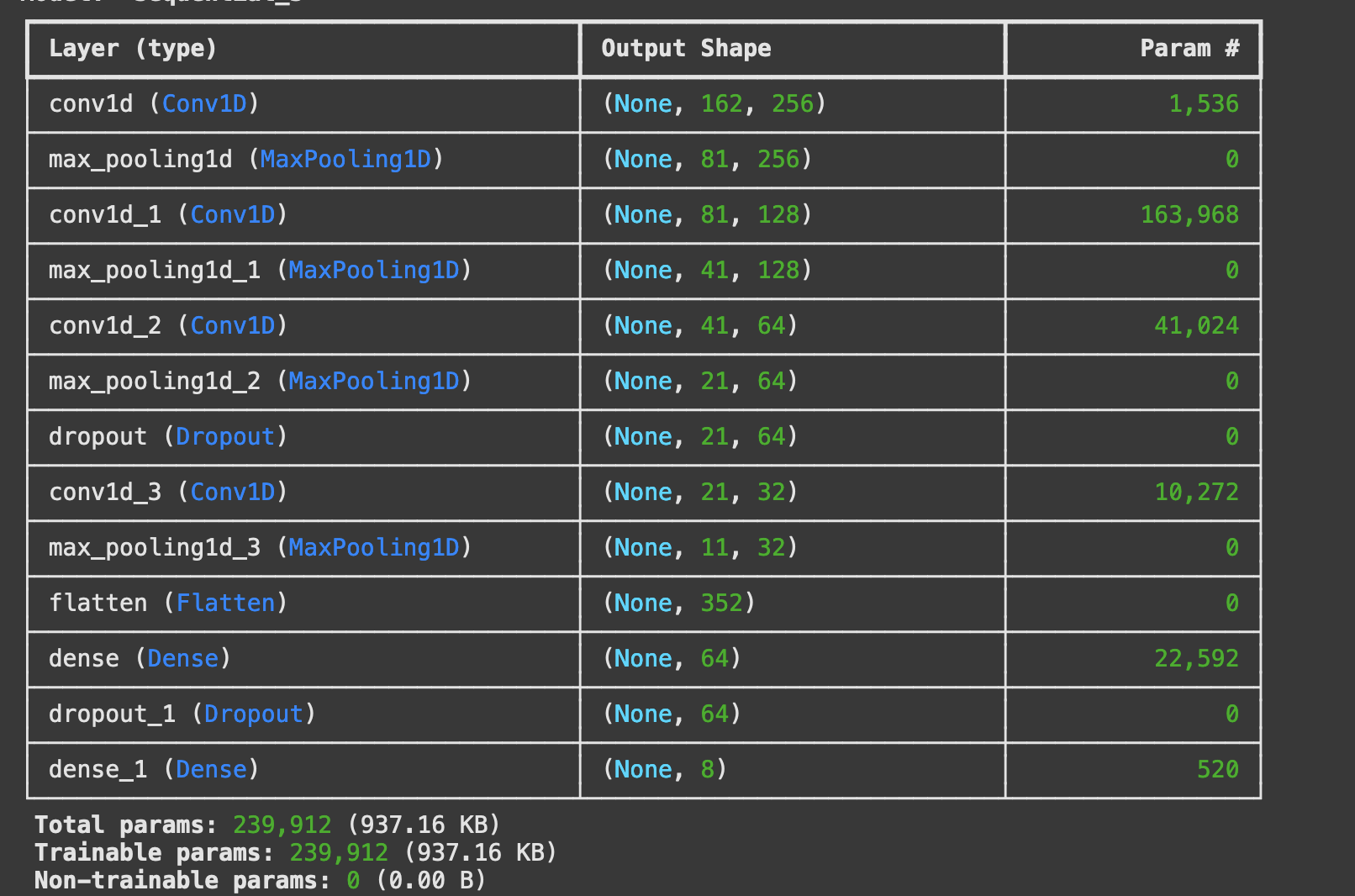
L’intégration avec Google Drive permet à l’utilisateur de sauvegarder le modèle entraîné pour une utilisation ultérieure (à développer dans un prochain article). Pour gérer efficacement le grand nombre de paramètres (239 912 paramètres), l’utilisation du service payant (10 € / 100 unités) de Google Colab avec un GPU (T4 par exemple) est recommandée.
L’entraînement du modèle sur le jeu de données aboutit à une précision de 64,55 %, ce qui, après avoir consulté divers scripts/articles sur Kaggle, semble être un résultat “standard” pour ce DataSet, d’autant plus que j’utilise une version incomplète des données.
Il est important de noter que certains scripts sur Kaggle affichent des précisions irréalistes allant jusqu’à 98 %, ce qui suscite des doutes sur leur crédibilité (sur-entrainement).
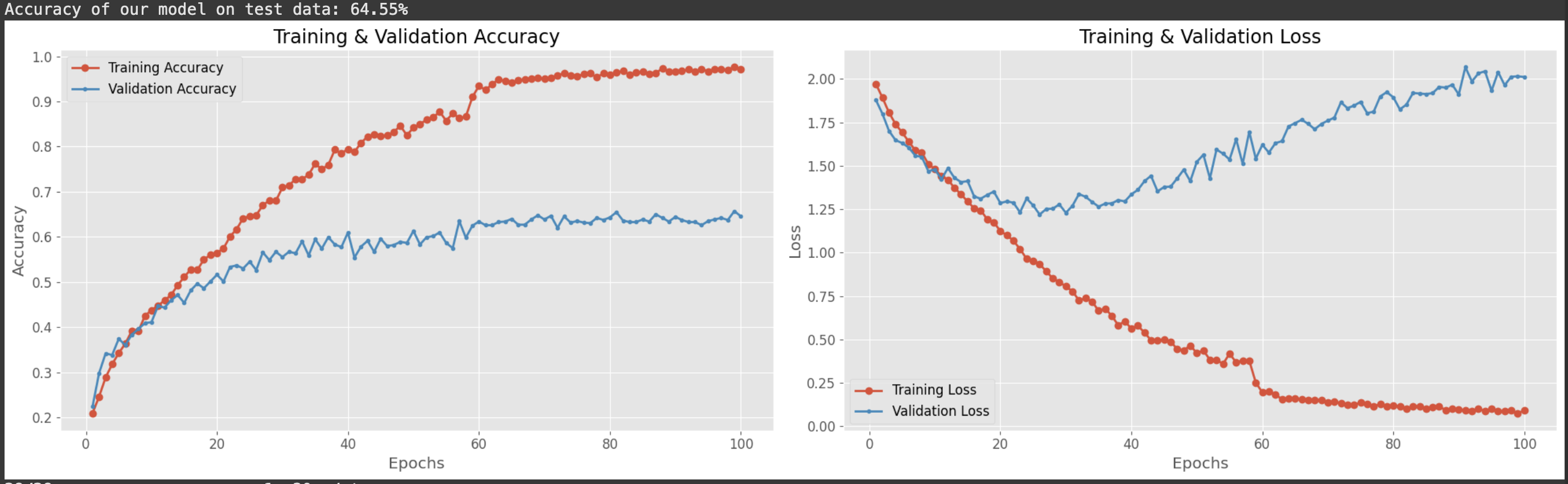
Un tel résultat, bien qu’insuffisant pour des applications concrètes, met en lumière les limites du modèle testé.
Cette performance (mauvaise/moyenne (?)) a été validée avec un exemple pratique : un test sur un court discours de Donald Trump.
Ce travail, bien que perfectible, s’inscrit dans une démarche pédagogique visant à explorer les hyper-paramètres d’un réseau neuronal convolutionnel (CNN) et à se familiariser avec les étapes incontournables de l’état de l’art dans la création d’un modèle.
Comprendre le fonctionnement des CNN
Le modèle des réseaux de neurones convolutifs (CNN) a été introduit par Yann LeCun dans un article révolutionnaire de 1998 (“Gradient-based learning applied to document recognition“. Selon Google Scholar, cet article a été cité plus de 71 000 fois), où il a démontré l’efficacité pour la reconnaissance des chiffres manuscrits avec le dataset MNIST.
Ce travail a posé les bases des avancées modernes en vision par ordinateur, en établissant les principes fondamentaux de la convolution, du pooling et des réseaux multicouches.
Un réseau de neurones convolutif (CNN) est une architecture utilisée principalement pour l’analyse d’images et de données structurées en 1D, 2D ou 3D.
Dans le contexte de l’analyse des émotions à partir de la voix, nous utilisons les CNN pour traiter des spectrogrammes audio. Un spectrogramme est une représentation des signaux sonores, convertissant les caractéristiques temporelles et fréquentielles en données intelligible par un modèle.
Dans notre problème, l’utilisation de CNN, et plus précisément la convolution permet de capturer des motifs présents dans les données, tels que des contours dans une image ou des variations de fréquence dans un spectrogramme.
Imaginez une image (ou un spectrogramme audio) comme une grande grille de nombres représentant les intensités des pixels ou des amplitudes sonores.
La convolution consiste à appliquer un filtre (aussi appelé noyau ou kernel), qui est une matrice de petite taille (par exemple, 3×3 ou 5×5), sur cette grille pour détecter des motifs spécifiques, comme des lignes ou des textures.
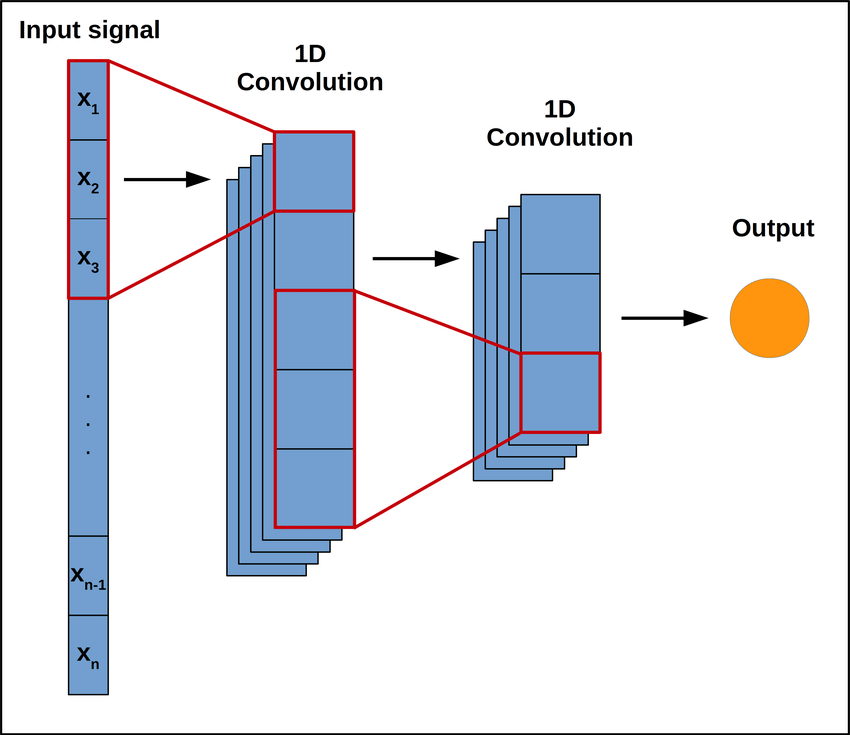
Le filtre “glisse” sur toute la grille (l’image ou le spectrogramme), en effectuant une multiplication élément par élément entre les valeurs du filtre et les valeurs de la grille à cet emplacement, puis en additionnant les résultats.
Le résultat est une nouvelle grille, appelée carte de caractéristiques (feature map), qui contient des informations sur les motifs détectés.
Le DataSet “RAVDESS”
Préparation des données et chargement du dataset
### 2. Preparation des données
# Définir le chemin des données
RAV = "/content/drive/MyDrive/DataSet/Ravdess/data/audio_speech_actors_01-24/" # Modifiez avec votre chemin
# Vérifiez que le répertoire existe
if not os.path.exists(RAV):
raise FileNotFoundError(f"Le répertoire {RAV} n'existe pas. Vérifiez le chemin.")
Le script commence par définir le chemin du dataset et charge les fichiers audio en extrayant les métadonnées utiles comme le genre de l’orateur et l’émotion exprimée.
# Créer un DataFrame
RAV_df = pd.DataFrame({
'emotion': emotion,
'gender': gender,
'path': path
})
# Mapper les émotions
emotion_map = {
1: 'neutral', 2: 'calm', 3: 'happy', 4: 'sad',
5: 'angry', 6: 'fear', 7: 'disgust', 8: 'surprise'
}
RAV_df['emotion'] = RAV_df['emotion'].map(emotion_map)
# Ajouter des colonnes supplémentaires
RAV_df['labels'] = RAV_df['gender'] + '_' + RAV_df['emotion']
RAV_df['source'] = 'RAVDESS'
# Afficher les résultats
print("Données chargées :")
display(RAV_df.head())
display(RAV_df.describe())
print("Répartition des labels :")
print(RAV_df.labels.value_counts())
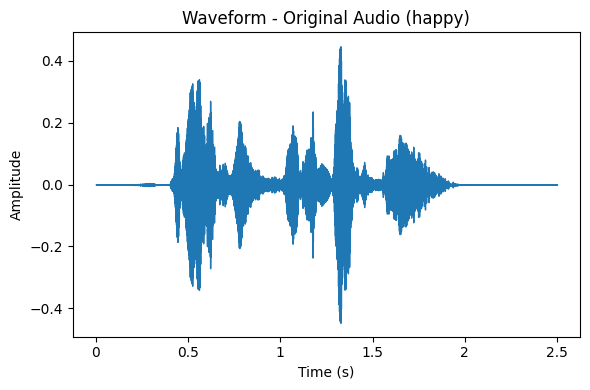
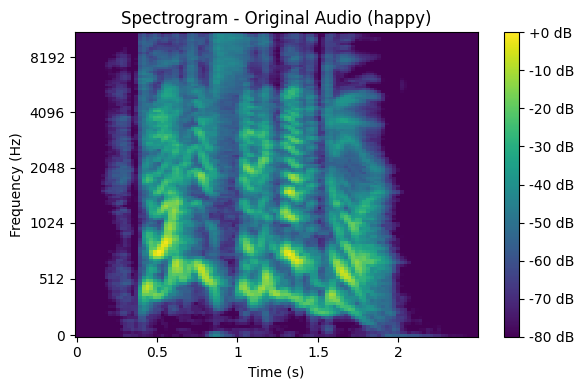
Représentation des données à partir d’un exemple
Pour chaque émotion vous aurez un exemple de représentation des données avec la “waveform” et le “spectrogram”.
Prétraitement et augmentation des données
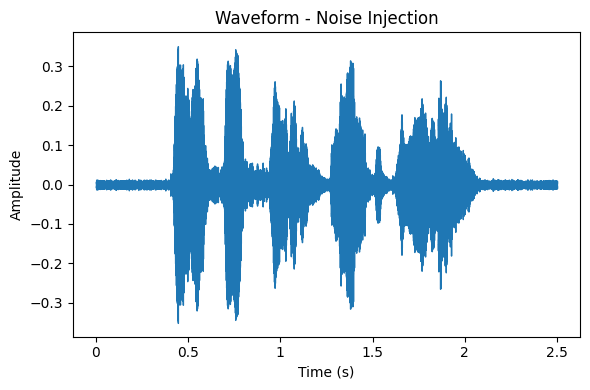
Les données audio brutes sont transformées pour inclure des versions augmentées.
Par exemple, le Noise Injection ajoute du bruit pour rendre le modèle tolérant aux environnements sonores complexes.
Le “Time Shifting” décale le signal temporellement, entraînant le modèle à se concentrer sur des caractéristiques clés indépendantes de leur position.
# Fonctions d'augmentation des données
def noise(data):
noise_amp = 0.035 * np.random.uniform() * np.amax(data)
return data + noise_amp * np.random.normal(size=data.shape[0])
def stretch(data, rate=0.8):
return librosa.effects.time_stretch(data, rate=rate)
def shift(data):
shift_range = int(np.random.uniform(low=-5, high=5) * 1000)
return np.roll(data, shift_range)
def pitch(data, sampling_rate, pitch_factor=0.7):
return librosa.effects.pitch_shift(data, sr=sampling_rate, n_steps=pitch_factor)
Extraction des caractéristiques
Pour entrainer le modèle CNN avec les données audio, il faut (avant l’entrainement) extraire des caractéristiques représentatives. Ces caractéristiques décrivent les propriétés du signal sonore.
# Fonction pour extraire des caractéristiques spécifiques
def extract_features(data, sample_rate):
result = np.array([])
# ZCR
zcr = np.mean(librosa.feature.zero_crossing_rate(y=data).T, axis=0)
result = np.hstack((result, zcr))
# Chroma STFT
stft = np.abs(librosa.stft(data))
chroma_stft = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T, axis=0)
result = np.hstack((result, chroma_stft))
# MFCC
mfcc = np.mean(librosa.feature.mfcc(y=data, sr=sample_rate).T, axis=0)
result = np.hstack((result, mfcc))
# RMS
rms = np.mean(librosa.feature.rms(y=data).T, axis=0)
result = np.hstack((result, rms))
# Mel Spectrogram
mel = np.mean(librosa.feature.melspectrogram(y=data, sr=sample_rate).T, axis=0)
result = np.hstack((result, mel))
return result
- ZCR (Zero Crossing Rate) : Mesure la fréquence des changements de signe dans le signal, utile pour détecter des sons agités liés à des émotions comme la colère ou la peur.
- Chroma STFT : Analyse les composantes tonales du signal pour capturer les variations harmoniques liées à l’émotion.
- MFCC : Représente les caractéristiques spectrales perçues par l’humain, pour différencier les timbres associés aux émotions.
- RMS (Root Mean Square) : Évalue l’énergie ou l’intensité du signal, reflétant la force d’une émotion comme la colère ou la surprise.
- Mel Spectrogram : Offre une représentation temps-fréquence alignée avec la perception auditive humaine, mettant en évidence les variations distinctives des émotions dans le spectre sonore.
À ce stade du projet, je choisis de ne pas m’attarder sur une explication approfondie des caractéristiques extraites des données audio. Je tiens toutefois à préciser que je me suis basé sur ces cinq caractéristiques largement reconnues et souvent utilisées dans les modèles CNN pour entraîner des systèmes de reconnaissance des émotions à partir de la voix (SER).
J’admets que cette approche repose sur une confiance implicite envers les travaux des développeurs précédents, ce qui n’est pas idéal sur le plan méthodologique…
Construction et entrainement du modèle
Le modèle est entraîné avec Conv1D car le signal audio est une donnée temporelle unidimensionnelle, composée d’une série de points représentant l’amplitude du son au fil du temps. Conv1D (keras.layers.Conv1D(filters=128, kernel_size=5, strides=1, activation=’relu’)) analyse ce type de données en faisant glisser des filtres (filters=128) le long de l’axe temporel avec une taille définie (kernel_size=5) et un pas spécifique (strides=1).
Le modèle est défini comme une séquence (Sequential) où les couches sont ajoutées linéairement.
### 5. Construction du Modèle # construction model = Sequential()
Chaque couche convolutive Conv1D utilise un filtre pour extraire des motifs temporels dans les données d’entrée.
Le kernel_size détermine la taille de ces filtres, tandis que les strides définissent leur déplacement (le pas).
model.add(Conv1D(256, kernel_size=5, strides=1, padding='same', activation='relu', input_shape=(x_train.shape[1], 1))) model.add(Conv1D(128, kernel_size=5, strides=1, padding='same', activation='relu'))
Les couches MaxPooling1D réduisent la dimensionnalité en conservant les informations importantes, tout en limitant le surapprentissage.
model.add(MaxPooling1D(pool_size=5, strides=2, padding='same'))
La couche Flatten transforme les sorties multidimensionnelles en un vecteur unidimensionnel pour permettre leur traitement par des couches denses.
model.add(Flatten())
La couche dense Dense(64) combine les caractéristiques extraites et la couche finale Dense(units=y_train.shape[1]) génère les probabilités des classes avec softmax.
model.add(Dense(units=64, activation='relu')) model.add(Dense(units=y_train.shape[1], activation='softmax'))
Enfin, le modèle est compilé avec l’optimiseur adam, la fonction de perte categorical_crossentropy, et l’évaluation basée sur accuracy.
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Je ne maîtrise pas encore tous les paramètres nécessaires à la configuration d’un modèle, et pour avancer, je me suis appuyé sur des exemples de code trouvés sur Kaggle ainsi que sur les enseignements de l’ouvrage d’Aurélien Géron, Deep Learning avec Keras et TensorFlow – Mise en oeuvre et cas concrets (3ème édition), Eidtion O’Reilly.
J’avoue que, pour l’instant, je subis un peu les complexités de ce domaine en plein apprentissage 😉
Hyper-paramètres et optimisation du modèle
Les hyperparamètres jouent un rôle important dans l’entraînement du modèle.
Par exemple, le nombre d’épochs (ici : epochs=100) correspond au nombre de fois où le modèle parcourt l’ensemble des données d’entraînement.
Un nombre élevé peut améliorer l’apprentissage mais augmenter le risque de sur-apprentissage.
Fonction pour arrêter l’apprentissage automatiquement
Dans ce script, une fonction pourrait être implémentée en ajoutant le callback EarlyStopping, qui arrête l’entraînement lorsque le modèle n’améliore plus sa performance
from tensorflow.keras.callbacks import EarlyStopping
# Callback EarlyStopping
early_stopping = EarlyStopping(
monitor='val_loss', # Surveille la perte de validation
patience=10, # Nombre d'époques sans amélioration avant arrêt
restore_best_weights=True # Restaure les poids du meilleur modèle
)
# Entraînement avec EarlyStopping
history = model.fit(
x_train,
y_train,
batch_size=32,
epochs=100,
validation_data=(x_test, y_test),
callbacks=[rlrp, early_stopping] # Ajout du callback EarlyStopping
)
Résultats et analyse des performances
Avec un taux de précision de 64,55 %, on remarque le modèle ne progresse plus après 58 épochs.
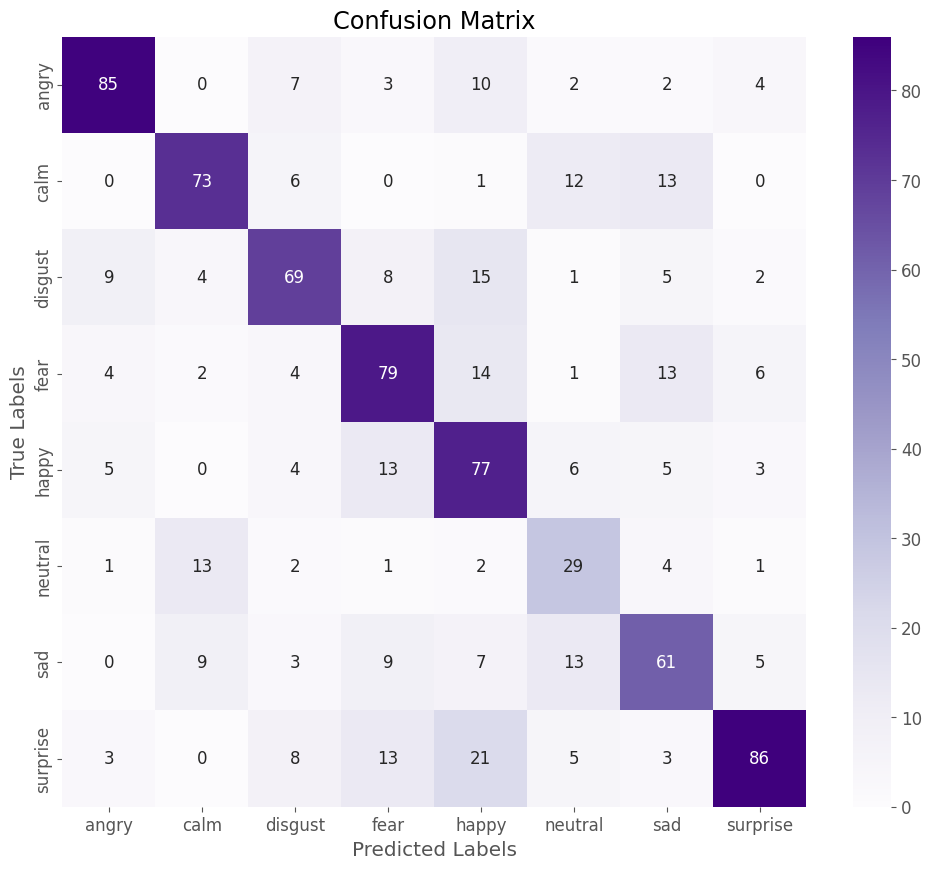
Matrice de confusion
Cette matrice de confusion compare les prédictions du modèle (colonnes) aux véritables étiquettes émotionnelles (lignes).
Chaque cellule indique combien de fois une émotion “vraie” a été classée comme une autre émotion.
Par exemple, pour l’émotion “angry”, 85 prédictions sont correctes (diagonale, colonne “angry”), mais 10 cas ont été incorrectement classés comme “happy”.
Une autre confusion notable apparaît pour “neutral”, où 13 exemples ont été mal prévus et attribué à “calm”. Cela peut indiquer que le modèle confond ces deux émotions en raison de caractéristiques acoustiques proches.
Il faudrait tester l’entrainement d’un nouveau modèle en mappant/regroupant ces deux émotions : “neutre” et “calm”.
Le script sur GoogleColab
Nous arrivons au terme de cet article dense et technique, où chaque étape de la construction et de l’entraînement du modèle a été détaillée. Une fois le modèle entraîné, il sera sauvegardé dans votre Google Drive, prêt à être utilisé pour des analyses concrètes.
C’est à ce moment que l’essentiel commence : mettre ce modèle à l’épreuve des faits en l’appliquant à des segments audio réels, pour en évaluer les performances avec des cas pratiques.
L’intégralité du script se trouve ICI.
L’apprentissage théorique laisse ainsi place à l’expérience terrain !
[…] même, vous devez spécifier le chemin vers votre modèle. Cela fait naturellement référence à l’article sur la construction du modèle. Cependant, si vous préférez éviter une « prise de neurones » 😉 lors de la création […]