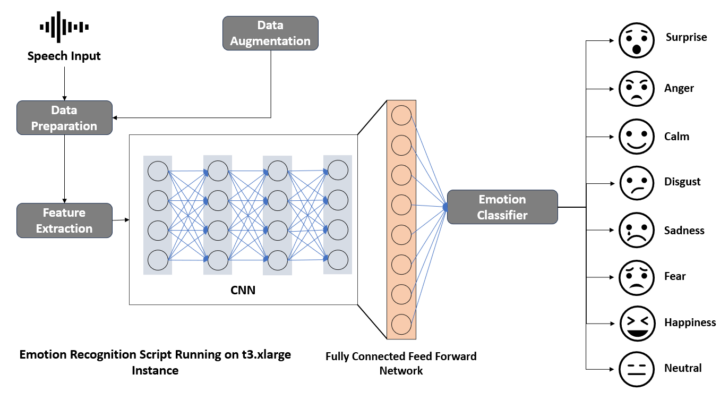
En développant un modèle de reconnaissance des émotions par la voix (SER, pour Speech Emotion Recognition), je n’ai pas choisi la voie la plus simple pour me familiariser avec les modèles de deep learning et l’intégration de la couche de traitement « audio » dans une approche multimodale. Pourquoi ? Parce que, comparée à des domaines comme la reconnaissance faciale, la précision des modèles basés...