







Le script
La bibliothèque from spacy.training import Example est utilisée pour créer des exemples d’entraînement pour spaCy. Dans le contexte de l’enrichissement d’un modèle avec de nouvelles annotations, elle permet de créer des exemples à partir des documents annotés pour l’entraînement du modèle.
# pip install spacy
# python -m spacy download fr_core_news_lg -> large modèle
# pip install streamlit spacy
# pip install streamlit spacy spacy-streamlit
# pip install watchdog
import streamlit as st
import spacy
import spacy_streamlit
from spacy.tokens import DocBin
from spacy.training import Example
import os
def log(message):
st.write(f"LOG: {message}")
@st.cache_resource
def load_model():
log("Chargement du modèle SpaCy large")
return spacy.load('fr_core_news_lg')
def save_annotations(doc, path):
log(f"Sauvegarde des annotations dans le fichier : {path}")
doc_bin = DocBin()
doc_bin.add(doc)
if not os.path.exists(os.path.dirname(path)):
os.makedirs(os.path.dirname(path))
doc_bin.to_disk(path)
def load_annotations(path, nlp):
if os.path.exists(path):
log(f"Chargement des annotations depuis le fichier : {path}")
doc_bin = DocBin().from_disk(path)
return list(doc_bin.get_docs(nlp.vocab))[0]
return None
def display_entities(doc):
entity_text = ""
last_end = 0
for ent in doc.ents:
entity_text += doc.text[last_end:ent.start_char]
entity_text += f"**[{ent.text}]({ent.label_})**"
last_end = ent.end_char
entity_text += doc.text[last_end:]
st.markdown(entity_text)
def load_enriched_model(nlp, annotations_path):
if os.path.exists(annotations_path):
doc_bin = DocBin().from_disk(annotations_path)
docs = list(doc_bin.get_docs(nlp.vocab))
for doc in docs:
for ent in doc.ents:
nlp.get_pipe('ner').add_label(ent.label_)
optimizer = nlp.resume_training()
for _ in range(10): # Vous pouvez ajuster le nombre d'itérations
losses = {}
for doc in docs:
example = Example.from_dict(doc, {
"entities": [(ent.start_char, ent.end_char, ent.label_) for ent in doc.ents]})
nlp.update([example], sgd=optimizer, losses=losses)
return nlp
LABELS = {
"PERSON": "Personne",
"NORP": "Groupes nationaux, politiques, religieux, etc.",
"FAC": "Bâtiments, aéroports, routes, ponts, etc.",
"ORG": "Organisations (entreprises, agences, institutions, etc.)",
"GPE": "Entités géopolitiques (pays, villes, états)",
"LOC": "Emplacements autres que les GPE (montagnes, planètes, etc.)",
"PRODUCT": "Objets, véhicules, aliments, etc. (pas de services)",
"EVENT": "Événements (guerres, compétitions sportives, etc.)",
"WORK_OF_ART": "Titres d'oeuvres d'art, livres, etc.",
"LAW": "Documents nommés comme lois, traités, etc.",
"LANGUAGE": "Langues",
"DATE": "Dates ou périodes",
"TIME": "Heures spécifiques dans la journée",
"PERCENT": "Pourcentages (incluant les signes %)",
"MONEY": "Montants monétaires",
"QUANTITY": "Mesures (poids, distance, etc.)",
"ORDINAL": "Adjoints ordinaux (premier, deuxième, etc.)",
"CARDINAL": "Numéros de base (mais pas des nombres comme 'deuxième')",
"MISC": "Divers"
}
def main():
"""Application NLP avec Spacy-Streamlit"""
col1, col2 = st.columns([3, 1])
with col1:
st.title("Application NLP Recherche / Création / Suppression de NER avec Spacy")
with col2:
st.write("Version 1.0")
st.write("Date: 2023-07-23")
st.markdown("[www.codeandcortex.fr](https://www.codeandcortex.fr)")
st.markdown("---")
menu = ["Analyse des Entités", "Création d'Entité", "Suppression des Entités", "Test du Modèle enrichi"]
choice = st.sidebar.selectbox("Menu", menu)
nlp = load_model()
annotations_path = st.text_input("Nom du fichier d'annotations des NER", "./annotations.spacy")
if choice == "Analyse des Entités":
st.subheader("Analyse des Entités de votre texte")
raw_text = st.text_area("Entrez votre texte ici", "Entrez le texte ici")
if st.button("Analyser", key="analyze_text"):
if raw_text:
doc = nlp(raw_text)
saved_doc = load_annotations(annotations_path, nlp)
if saved_doc:
doc.ents = saved_doc.ents
st.subheader("Entités détectées:")
display_entities(doc)
st.subheader("Visualisation des entités:")
spacy_streamlit.visualize_ner(doc, labels=nlp.get_pipe('ner').labels, key="ner_analysis")
elif choice == "Création d'Entité (NER)":
st.subheader("Création d'Entité")
raw_text = st.text_area("Entrez votre texte ici", "Entrez le texte ici...")
if st.button("Analyser le texte", key="analyze_creation"):
doc = nlp(raw_text)
saved_doc = load_annotations(annotations_path, nlp)
if saved_doc:
doc.ents = saved_doc.ents
st.session_state.doc = doc
st.subheader("Entités détectées:")
display_entities(doc)
st.subheader("Visualisation des entités:")
spacy_streamlit.visualize_ner(doc, labels=nlp.get_pipe('ner').labels, key="ner_analysis_creation")
st.session_state.word_positions = [(token.text, i) for i, token in enumerate(doc)]
if 'doc' in st.session_state:
doc = st.session_state.doc
st.subheader("Ajouter des Entités Nommées")
if 'word_positions' in st.session_state:
st.subheader("Texte avec indices")
st.write(", ".join([f"{text} ({i})" for text, i in st.session_state.word_positions]))
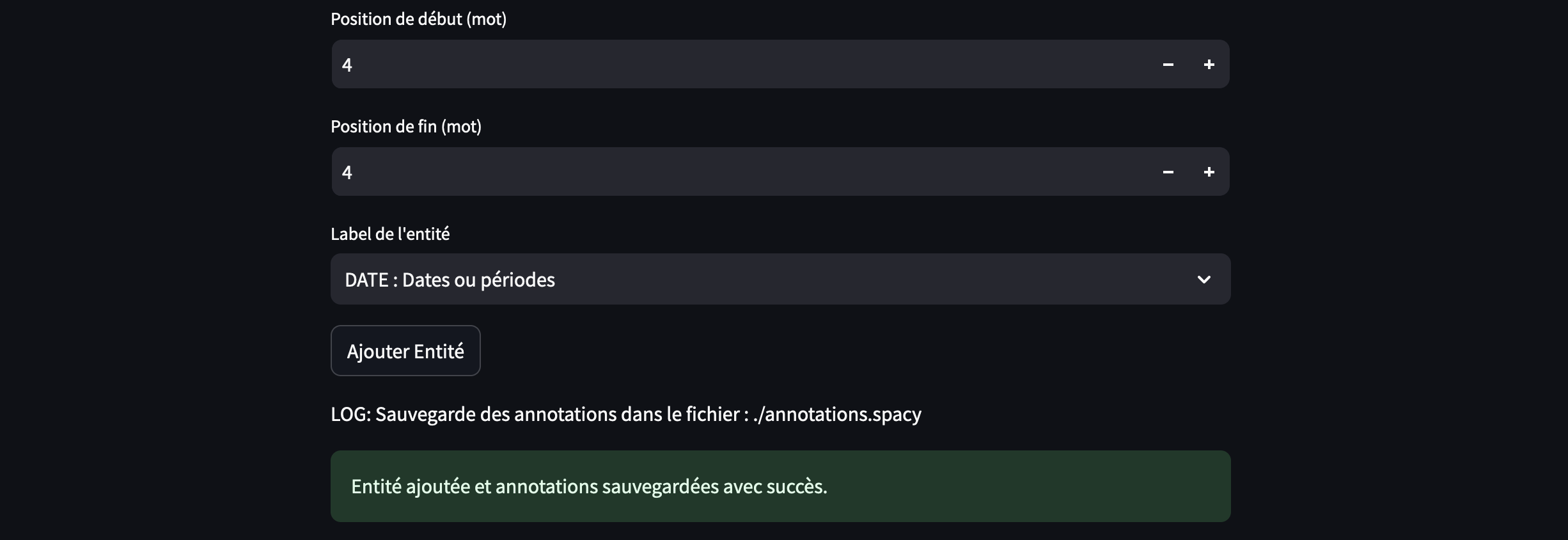
word_start = st.number_input("Position de début (mot)", min_value=0, max_value=len(doc) - 1, step=1,
key="start_word_creation")
word_end = st.number_input("Position de fin (mot)", min_value=0, max_value=len(doc) - 1, step=1,
key="end_word_creation")
label = st.selectbox("Label de l'entité", list(LABELS.keys()), format_func=lambda x: f"{x} : {LABELS[x]}",
key="entity_label_creation")
if st.button("Ajouter Entité", key="add_entity_creation"):
if word_start <= word_end < len(doc):
char_start = doc[word_start].idx
char_end = doc[word_end].idx + len(doc[word_end].text)
span = doc.char_span(char_start, char_end, label=label)
if span:
conflicts = [ent for ent in doc.ents if not (span.end <= ent.start or span.start >= ent.end)]
if not conflicts:
new_ents = list(doc.ents) + [span]
doc.ents = new_ents
st.session_state.doc = doc
save_annotations(doc, annotations_path)
st.success("Entité ajoutée et annotations sauvegardées avec succès.")
st.subheader("Entités mises à jour:")
display_entities(doc)
st.subheader("Visualisation des entités mises à jour:")
spacy_streamlit.visualize_ner(doc, labels=nlp.get_pipe('ner').labels,
key="ner_after_add_creation")
else:
st.error("Les nouvelles entités ne doivent pas chevaucher les entités existantes.")
else:
st.error("Impossible de créer une entité avec ces indices.")
else:
st.error("Les positions de début et de fin sont invalides.")
elif choice == "Suppression des Entités":
st.subheader("Suppression des Entités")
if st.button("Charger les annotations", key="load_model_suppression"):
doc = load_annotations(annotations_path, nlp)
if doc:
st.session_state.doc = doc
st.subheader("Entités détectées:")
display_entities(doc)
st.subheader("Visualisation des entités:")
spacy_streamlit.visualize_ner(doc, labels=nlp.get_pipe('ner').labels, key="ner_analysis_suppression")
else:
st.error("Aucune annotation trouvée.")
if 'doc' in st.session_state:
doc = st.session_state.doc
st.subheader("Supprimer des Entités Nommées")
ents = [(ent.text, ent.start, ent.end, ent.label_) for ent in doc.ents]
ents_to_remove = st.multiselect("Choisissez des entités à supprimer", ents,
key="remove_entities_suppression")
if st.button("Supprimer les Entités Sélectionnées", key="delete_entities_suppression"):
if ents_to_remove:
new_ents = [ent for ent in doc.ents if
(ent.text, ent.start, ent.end, ent.label_) not in ents_to_remove]
doc.ents = new_ents
st.session_state.doc = doc
save_annotations(doc, annotations_path)
st.success("Entités supprimées et annotations sauvegardées avec succès.")
st.subheader("Entités mises à jour:")
display_entities(doc)
st.subheader("Visualisation des entités mises à jour:")
spacy_streamlit.visualize_ner(doc, labels=nlp.get_pipe('ner').labels,
key="ner_after_delete_suppression")
elif choice == "Test du Modèle Enrichi":
st.subheader("Test du Modèle Enrichi avec les Annotations")
# Charger le modèle enrichi
enriched_nlp = load_enriched_model(nlp, annotations_path)
# Zone de texte pour entrer un nouveau texte à tester
test_text = st.text_area("Entrez un nouveau texte à tester", "Entrez le texte ici")
if st.button("Tester le Modèle Enrichi"):
if test_text:
doc = enriched_nlp(test_text)
st.subheader("Entités détectées par le modèle enrichi:")
display_entities(doc)
st.subheader("Visualisation des entités:")
spacy_streamlit.visualize_ner(doc, labels=enriched_nlp.get_pipe('ner').labels, key="ner_enriched_model")
else:
st.error("Veuillez entrer un texte à tester.")
if __name__ == '__main__':
main()
Conclusion
L’approche décrite dans ce script est particulièrement utile pour des applications telles que les chatbots, où une compréhension précise du langage de l’utilisateur est cruciale.
Par exemple, dans le domaine du tourisme, un utilisateur demandant des informations sur le « lac de Bethmale » nécessite que le mot « Bethmale » soit reconnu comme une entité nommée (lieu). Cela permet au processus de traitement du langage de reconnaître cette entité spécifique et d’optimiser les réponses fournies à l’utilisateur.
De même, dans le secteur marchand, si un utilisateur pose une question sur un modèle de chaussure de trail de la marque Salomon, il est essentiel que « Salomon » soit reconnu comme une entité nommée (marque).
En affinant le modèle NLP avec des entités spécifiques, on améliore la précision et la pertinence des réponses du chatbot. Cette approche montre donc l’intérêt et l’importance de créer et de modifier des entités nommées pour différents secteurs, tels que le tourisme et le commerce, afin de mieux répondre aux besoins des utilisateurs.