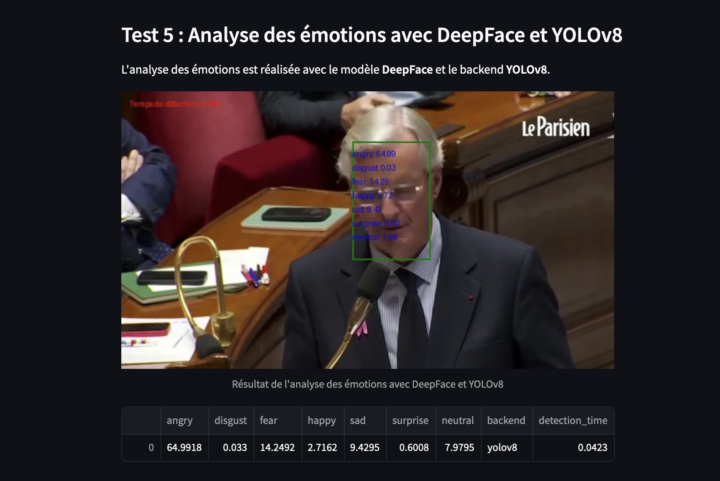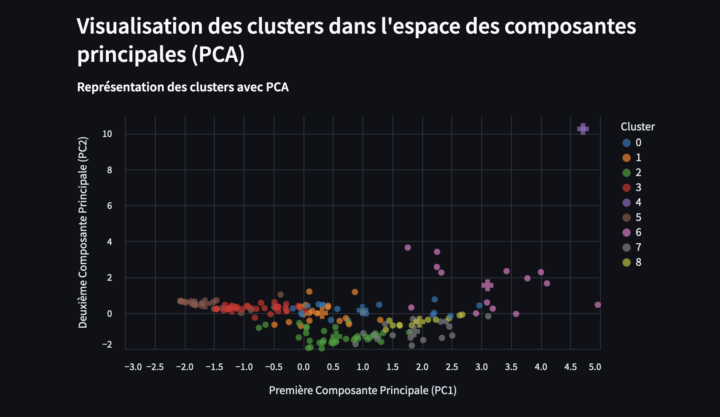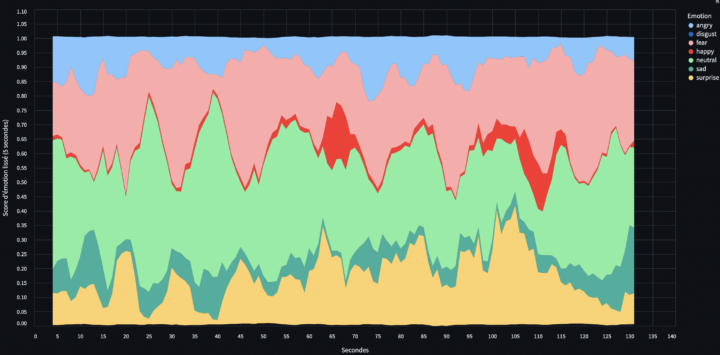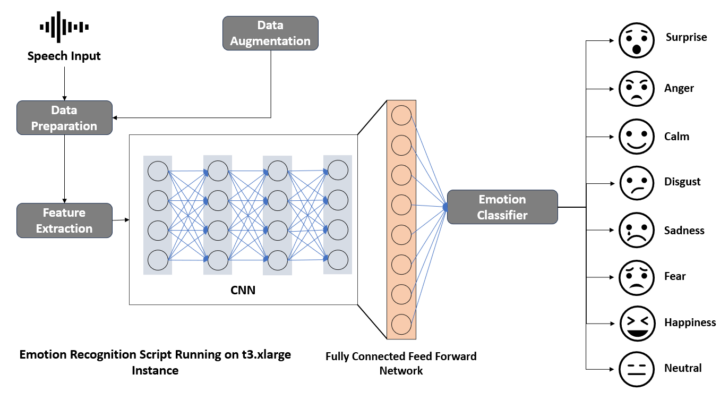
L’objectif de cet article est de construire un modèle pour réaliser une détection des émotions à partir de la voix (SER – Speech Emotion Recognition) afin d’analyser des segments audio spécifiques, comme par exemple un discours politique de Donald Trump. La première étape consiste à concevoir et entraîner un modèle pour réaliser cette analyse émotionnelle. Cette article...