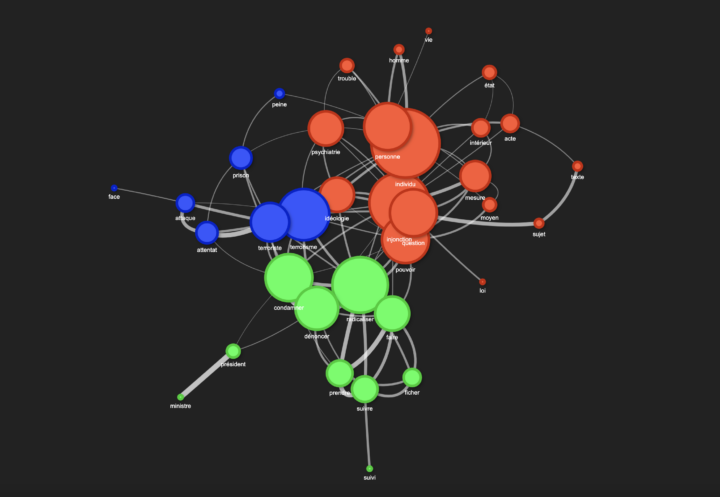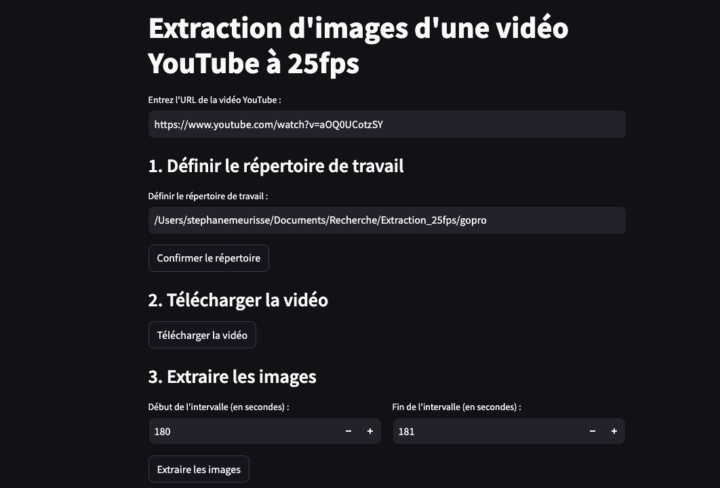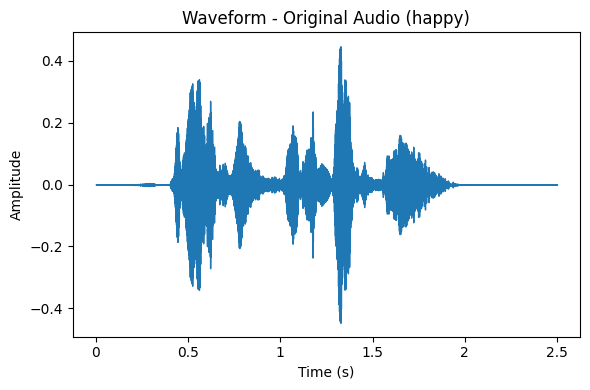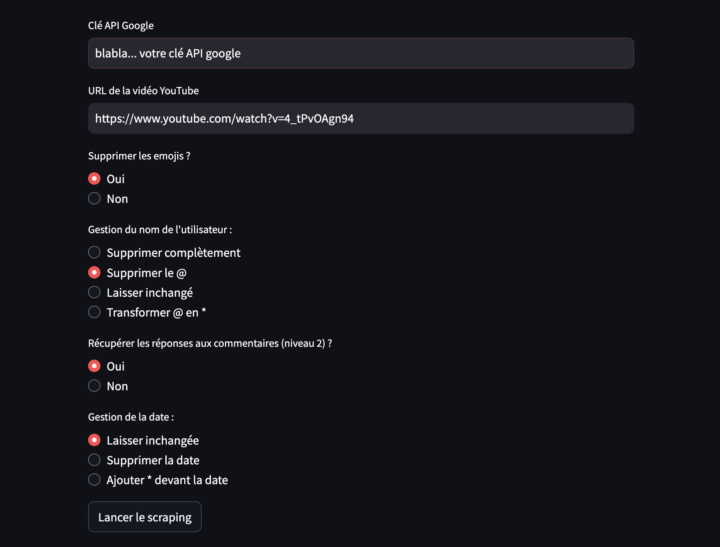
X est devenu le repaire de la désinformation… Alors que Facebook ou Linkedin imposent une API payante pour récupérer leurs posts, il nous reste donc une source – certes également sujette à la désinformation, mais où l’expression demeure spontanée et authentique – celle des commentaires YouTube. Il faut bien l’avouer : certaines vidéos suscitent une avalanche de réactions ! Merci...