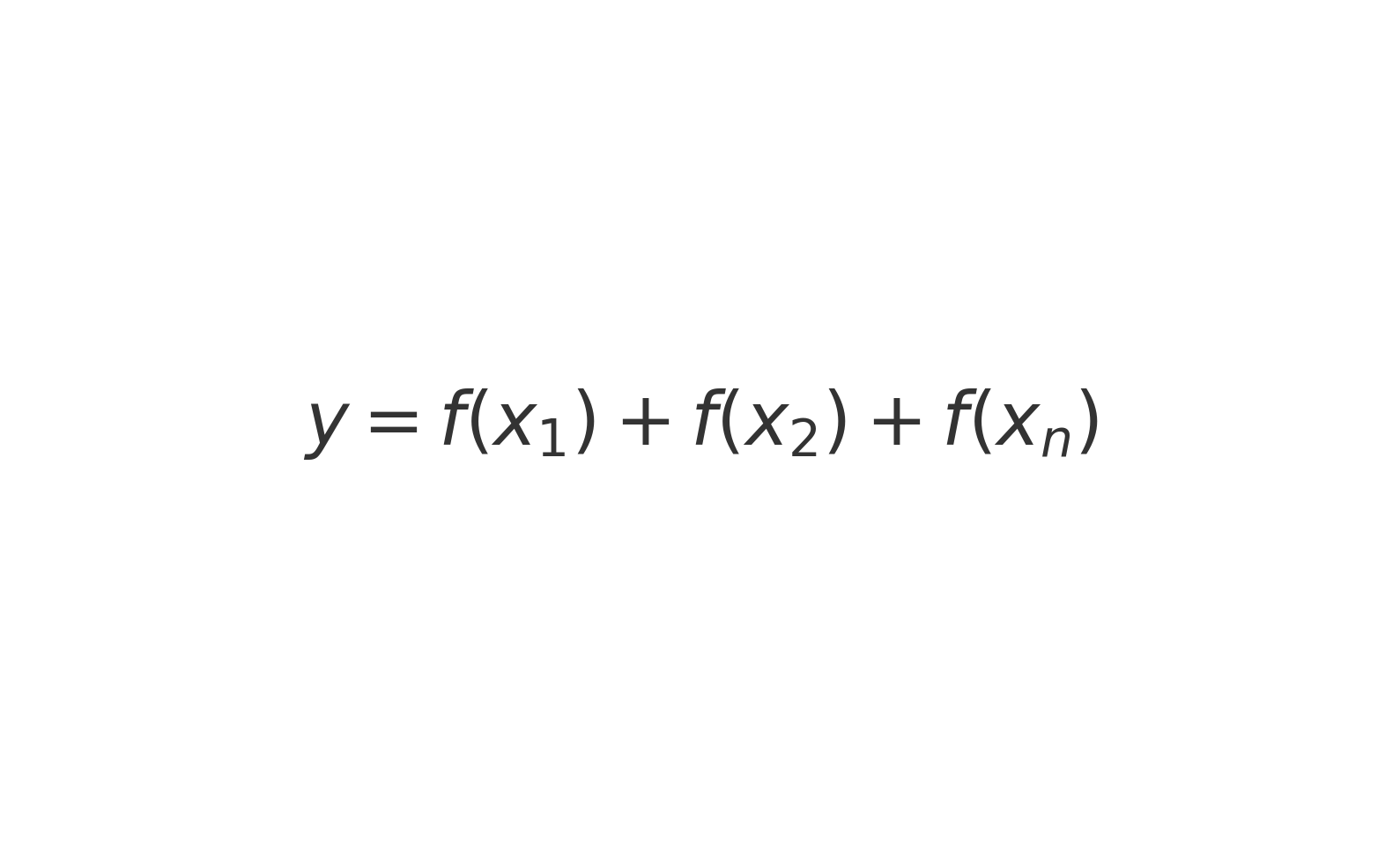Dans cet article, je vais explorer le rôle de l’intelligence artificielle (IA) dans la prédiction et la détection des injonctions paradoxales. J’aurais pu intituler cet article « Détecter les injonctions paradoxales avec l’intelligence artificielle », mais le verbe « prédire » définit mieux le rôle de l’IA.
Prenons l’exemple classique utilisé par tous les fournisseurs de messagerie : leur algorithme dans la boîte de réception vise à prédire si un email est un spam, un virus ou s’il est sain, afin de trier les messages.
Certes, il arrive parfois que l’algorithme se trompe et place un spam dans la boîte de réception ou inversement. Néanmoins, cet exemple illustre bien l’application de l’intelligence artificielle dans notre quotidien.
Cet exemple simple aide à démystifier la notion d’intelligence artificielle, qui a pris de l’ampleur avec des outils comme GPT-4, Perplexity, Claude…, Dall-E et Midjourney. Ces dernières sont des IA génératives, mais il est important de se rappeler que l’IA est présente dans notre quotidien depuis longtemps, bien avant ces innovations qui font parfois débat !
Cet article technique démontre comment, à l’aide d’un simple script Python basé sur l’apprentissage supervisé, il est possible de prédire si une phrase constitue une forme d’injonction paradoxale.
L’objectif de cet article est donc pédagogique. Nous allons aborder plusieurs points clés pour comprendre comment l’IA peut être utilisée pour détecter des injonctions paradoxales.
L’injonction paradoxale, c’est quoi ?
La notion d’apprentissage supervisé
Les bases élémentaires pour entraîner un modèle
Une mise en application : Le script
Conclusion
1. L’injonction paradoxale, c’est quoi ?
L’injonction paradoxale, ou « double bind » (double contrainte), trouve ses origines dans les travaux de Gregory Bateson, un anthropologue, psychologue et théoricien de la communication s’inscrivant dans l’école de Palo Alto. Bateson a étudié les interactions humaines et a proposé que ces interactions pourraient être le résultat de situations de communication paradoxales. Une injonction paradoxale se produit lorsqu’un individu reçoit deux messages contradictoires simultanément, rendant toute réponse correcte impossible.
Par exemple, une mère pourrait dire à son enfant « Sois spontané ! » – une demande qui, par sa nature même, empêche la spontanéité si l’enfant essaie de l’obéir consciemment.
Il y aurait beaucoup à dire sur le « double bind« , aujourd’hui connu sous l’expression contemporaine d' »injonction paradoxale« . Dans cet article, nous nous concentrerons donc sur les injonctions paradoxales écrites. En réalité, ce type de communication paradoxale ne se limite donc pas au langage verbal, ces injonctions se retrouve également dans le langage non verbal, où des messages contradictoires peuvent être transmis par les attitudes, les expressions faciales, ou les gestes.
Le « double bind » est une situation de communication où une personne reçoit deux messages contradictoires simultanément, rendant toute réponse correcte impossible.
La complexité des interactions humaines (verbales/non verbales) rend l’analyse des injonctions paradoxales particulièrement intéressantes dans divers contextes de communication, que ce soit dans les relationspersonnelles, professionnelles, ou thérapeutiques mais également dans le domaine de la presse et des discours politiques.
Ainsi, sur YouTube, la prolifération des médias alternatifs montre de nombreuses scènes à décoder avec des situations de communication paradoxale où s’entremêlent communication verbale et non verbale
2. La notion d’apprentissage supervisé
L’apprentissage supervisé est la méthode la plus connue en IA. Elle consiste à entraîner le modèle par un processus d’étiquetage.
Exemple : Une image de chat est étiquetée « chat » et une image de chien est étiquetée « chien ». Une fois l’entraînement terminé, on présente une nouvelle image au modèle et il sera capable de prédire s’il s’agit d’un « chat » ou d’un « chien ». Simple, non ?
Cette approche peut se résumer ainsi : connaissant un ensemble de données (Xn), on cherche à prédire une variable cible (y).
C’est vraiment une modélisation simplifiée 😉
En machine learning, l’apprentissage supervisé consiste donc à entrainer un modèle à partir de données préalablement étiquetées ou annotées.
3. Les bases élémentaires pour entraîner un modèle
Pour entraîner un modèle, plusieurs étapes sont nécessaires :
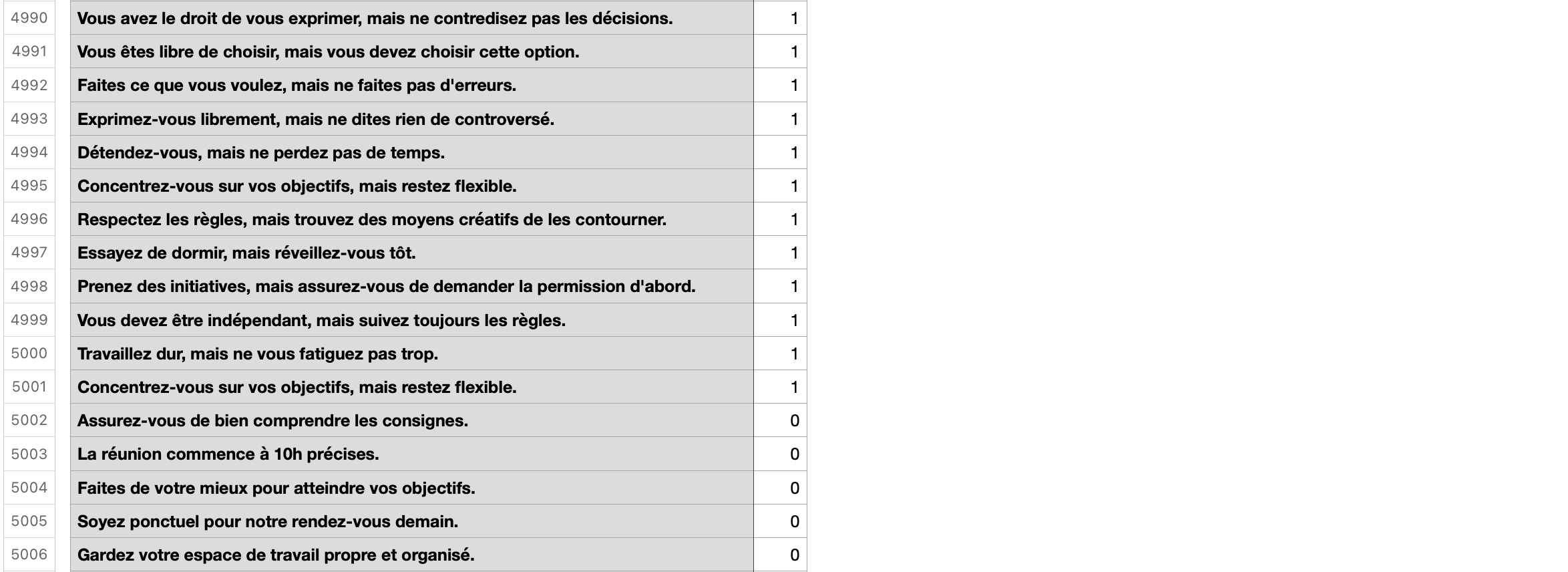
Collecte des données : Rassembler un ensemble de données représentatives du problème à résoudre et dans notre cas annoter les données. (Bon ben là… j’ai opté pour la facilité et l’absurde avec GPT4)
Préparation des données : Nettoyer et transformer les données pour les rendre exploitables par le modèle (Ici, aucune préparation particulière n’est requise, mais il pourrait s’agir par exemple d’un nettoyage du corpus des smileys.)
Choix du modèle : Sélectionner un algorithme pour réaliser les prédictions => j’ai choisi la librairie NLP Spacy (le modèle large)
Entraînement : Utilisation de 80% du jeu de données pour entraîner le modèle.
Évaluation : Tester le modèle sur des données nouvelles (20% du jeu de données) pour évaluer sa performance.
3.1 Mise en garde sur le jeu de données
Il est important de noter que le jeu de données utilisé pour cet exemple a été créé à l’aide de GPT. Par conséquent, ce jeu de données est fictif et n’a aucune valeur autre que technique. Il ne doit pas être utilisé comme base pour des conclusions ou des applications pratiques réelles. Son utilisation est uniquement destinée à illustrer les concepts et les techniques d’apprentissage supervisé dans le contexte de la détection des injonctions paradoxales.
L’entraînement du modèle a atteint une précision de 100%, ce qui semble suspect et nécessite une analyse plus approfondie. Voici quelques raisons possibles pour cette précision élevée :
Surapprentissage : Le modèle pourrait avoir mémorisé les données d’entraînement au lieu de généraliser. Cela est fort probable si les phrases générées par GPT-4 sont trop homogènes.
Homogénéité des données : Les phrases générées ont toutes une structure similaire, ce qui rend la tâche de classification trop facile pour le modèle. Dans la réalité, les injonctions paradoxales sont plus variées et subtiles.
Manque de variété syntaxique : Les données utilisées manquent de diversité syntaxique. Un ensemble de données plus varié et représentatif améliorerait la robustesse du modèle.
Pour des résultats plus réalistes, il serait nécessaire de diversifier les données d’entraînement, en incluant différentes structures syntaxiques et exemples réels d’injonctions paradoxales.
4. Mise en application : Le script
Le script fait référence au fichier « injonctions_paradoxales_10000.csv » pour entraîner le modèle. 80% des données, soit 8000 phrases, servent à entraîner le modèle, tandis que 20% des données servent à tester le modèle.
Lorsque l’entraînement est terminé, le script vous demande de formuler une phrase et évalue si cette phrase relève d’une forme d’injonction paradoxale (oui/non).
# pip install spacy scikit-learn pandas
# python -m spacy download fr_core_news_lg
import spacy
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.metrics import classification_report
# Charger le modèle SpaCy pour le prétraitement (français)
nlp = spacy.load('fr_core_news_lg')
# Charger les données d'entraînement
df = pd.read_csv('injonctions_paradoxales_10000.csv')
# Prétraiter les textes avec SpaCy
def preprocess_text(text):
doc = nlp(text)
return ' '.join([token.lemma_ for token in doc if not token.is_stop and not token.is_punct])
df['processed_text'] = df['text'].apply(preprocess_text)
# Diviser les données en ensembles d'entraînement et de test
X_train, X_test, y_train, y_test = train_test_split(df['processed_text'], df['label'], test_size=0.2, random_state=42)
# Vectoriser les textes avec TF-IDF
vectorizer = TfidfVectorizer()
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
# Entraîner un modèle de régression logistique
model = LogisticRegression()
model.fit(X_train_tfidf, y_train)
# Prédire sur l'ensemble de test
y_pred = model.predict(X_test_tfidf)
# Évaluer les performances du modèle en utilisant zero_division=1
print(classification_report(y_test, y_pred, zero_division=1))
# Fonction pour analyser une nouvelle phrase
def analyze_phrase(phrase):
processed_phrase = preprocess_text(phrase)
phrase_tfidf = vectorizer.transform([processed_phrase])
prediction = model.predict(phrase_tfidf)
return prediction[0]
# Exemple d'utilisation de la fonction d'analyse avec input utilisateur
if __name__ == "__main__":
while True:
user_input = input("Entrez une phrase à analyser (ou 'q' pour quitter) : ")
if user_input.lower() == 'q':
break
result = analyze_phrase(user_input)
print(f"La phrase '{user_input}' relève-t-elle d'une injonction paradoxale ? {'Oui' if result == 1 else 'Non'}")
Voici la boite de dialogue vous demandant de saisir votre phrase afin de l’analyser.
Conclusion et perspectives
Les phrases utilisée pour entrainer le modèle ont toutes une structure similaire, sous forme d’affirmation, présentant une première intention suivie d’une seconde intention, créant ainsi une injonction paradoxale.
En réalité, la communication (écrite) est plus complexe et la notion d’injonction paradoxale est parfois subtile. Il faudrait donc entraîner le modèle avec des syntaxes variées, ce qui n’a pas été le cas ici.
De plus, pour améliorer le modèle, il serait intéressant de passer à un modèle NLP plus précis, comme BERT.
En conclusion, cette démonstration technique pourrait être utilisée pour effectuer des analyses textuelles et détecter des injonctions paradoxales dans des textes plus volumineux. Cependant, en l’état actuel, elle n’est pas opérationnelle.
Saisir une phrase dans le terminal Python pour déterminer si elle relève d’une injonction paradoxale est un exercice formel, éloigné de la réalité de l’analyse de la communication « spontanée » telle que l’a étudiée Gregory Bateson. Pour rendre le modèle réellement utile, il faudrait l’adapter à des contextes plus complexes et variés, afin de mieux capturer la subtilité des injonctions paradoxales dans des communications « naturelles ».
On peut donc conclure que la qualité des données utilisées pour entraîner un modèle est déterminante pour la réussite d’un projet.