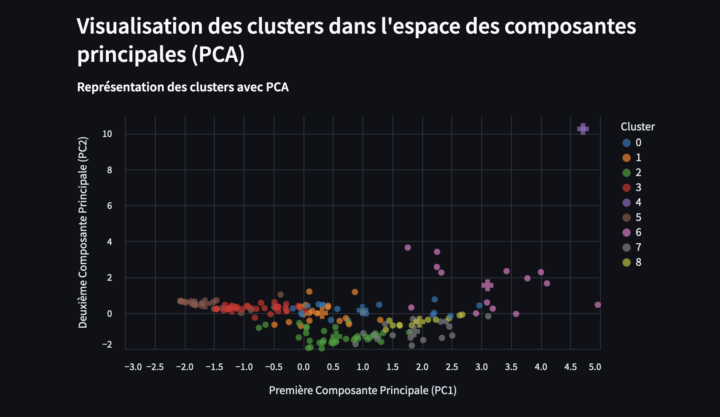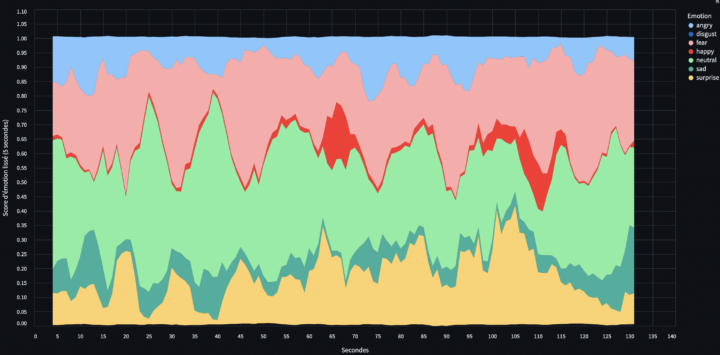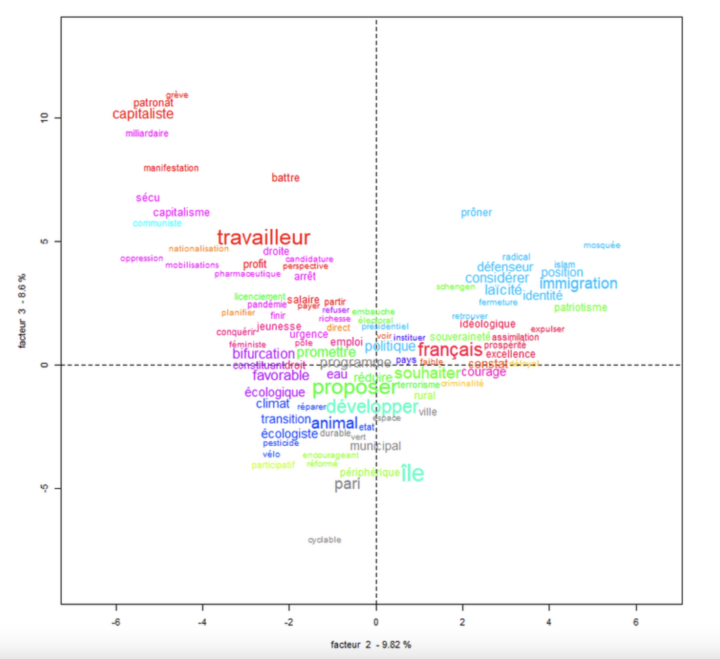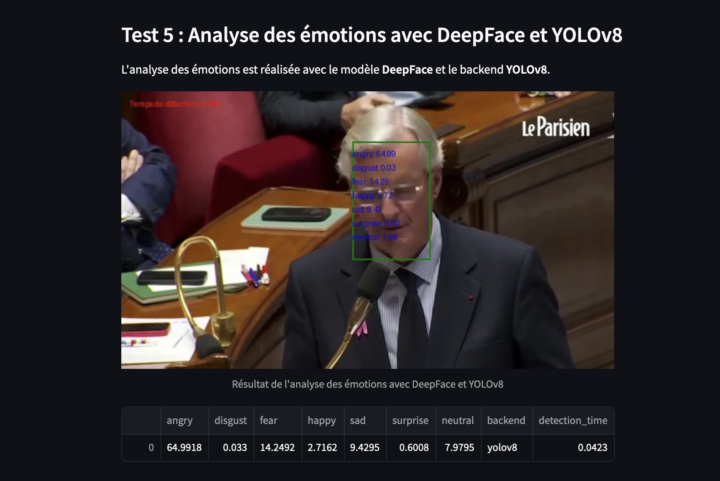
1. La genèse de DeepFace et ses applications courantes DeepFace est un outil de reconnaissance faciale développé par Facebook en 2014, dont l’objectif initial était d’améliorer la précision de la reconnaissance faciale en ligne, en permettant aux utilisateurs de taguer des visages dans les photos afin d’encourager l’identification dans les photos. À l’époque de son...