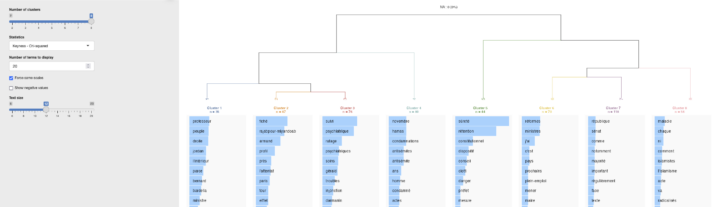
Puisque nous nous situons dans le champ des sciences humaines et sociales (SHS), voici une brève description du corpus utilisé : il est composé de 23 articles de presse portant sur la déclaration de Gérald Darmanin dénonçant « un ratage » dans le suivi psychiatrique d’un suspect. Ce corpus a été formaté pour répondre aux exigences du logiciel IRaMuTEQ, car il me sert également de test dans le...