
Puisque nous nous situons dans le champ des sciences humaines et sociales (SHS), voici une brève description du corpus utilisé : il est composé de 23 articles de presse portant sur la déclaration de Gérald Darmanin dénonçant « un ratage » dans le suivi psychiatrique d’un suspect.
Ce corpus a été formaté pour répondre aux exigences du logiciel IRaMuTEQ, car il me sert également de test dans le cadre de l’élaboration d’autres outils. Par ailleurs, bien que la première ligne contienne des variables étoilées, cela n’impacte ni le fonctionnement ni la logique du script.
Ces articles de presse laissent entrevoir, en filigrane, les liens entre politique, psychiatrie et surveillance, des thématiques explorées dans l’ouvrage de Michel Foucault Le Pouvoir psychiatrique : Cours au Collège de France (1973-1974).
Cependant, cette mise en relation n’est pas l’objectif principal ici. L’article présente un script Python qui vise avant tout à effectuer une extraction automatique des entités nommées (NER) à partir du corpus et à offrir la possibilité de corriger ces entités.
L’objectif n’est donc pas d’interpréter ou d’analyser ce corpus, mais simplement d’illustrer une application technique : l’extraction des entités nommées avec Python.
Dans ce projet, j’utilise le modèle “fr_core_news_sm” de SpaCy, qui est le plus léger des modèles (sm => small). Il offre une reconnaissance rapide des entités nommées (NER, ou Named Entity Recognition), permettant d’identifier et de labelliser dans un texte les noms de personnes (PER), des organisations (ORG), les lieux (LOC) et … un label fourre tout “divers” (MISC) .
Limitations du modèle SpaCy pour l’extraction des entités NER
Il faut bien se l’avouer la fonction NER de Spacy sur des textes en Français manque cruellement de précision !
Pour améliorer cela vous pouvez entrainer un modèle NER spécifique avec une solution comme Prodigy mais cela peut rapidement devenir chronophage et si votre corpus est relativement “petit”. De plus le service est payant !
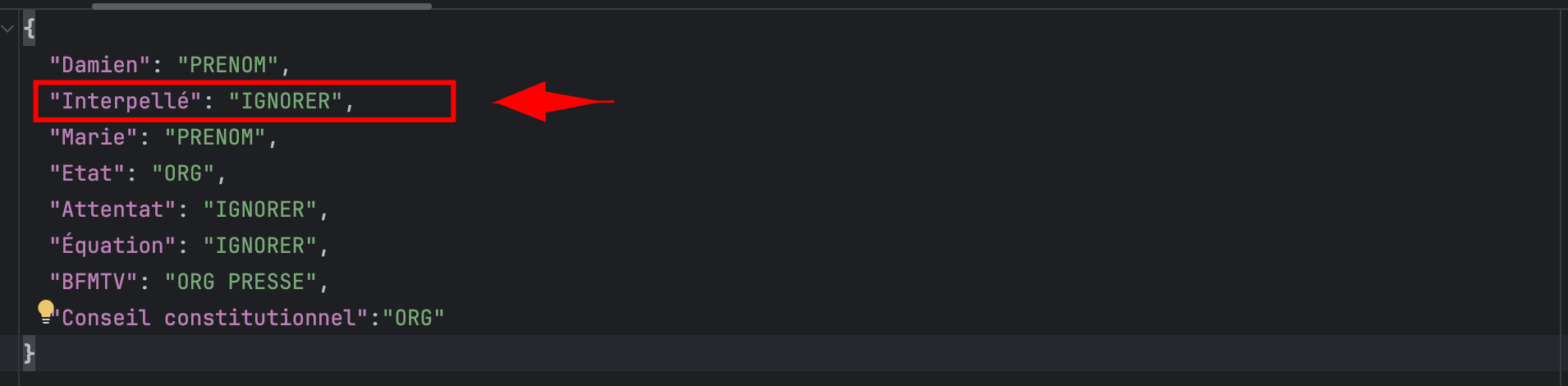
Une approche alternative, consiste à utiliser un fichier JSON contenant les NER corrigés et ajoutés manuellement. Le script Python utilisera ce fichier pour analyser les NER présents dans votre corpus.
Le modèle Spacy en français est décevant car il propose uniquement 4 labels contrairement au modèle Anglais qui en contient bien plus.


# Charger le modèle français de spaCy
nlp = spacy.load("fr_core_news_sm")
print(nlp.get_pipe("ner").labels)

# ici la syntaxe de votre fichier JSON, simple comme "bonjour" !
{
"Damien": "PRENOM",
"Interpellé": "IGNORER",
"Marie": "PRENOM",
"Etat": "ORG",
"Attentat": "IGNORER",
"Équation": "IGNORER",
"BFMTV": "ORG PRESSE"
}
Cette redéfinition des labels, bien que faisable, doit être abordée avec prudence, car elle peut rapidement devenir fastidieuse, surtout sur des corpus de grande taille. Gardez à l’esprit que ce processus peut être chronophage, mais il reste une option viable si vous avez besoin d’une catégorisation plus fine et spécifique.

L’idée principale du script est d’exécuter une première analyse pour observer les entités nommées (NER) identifiées par SpaCy dans votre corpus.
Pour cela, le script affiche dans le terminal les 30 premiers NER détectés (vous pouvez redéfinir ce paramètre). En complément, il génère un fichier csv ainsi qu’un graphique représentant le top 30 des NER les plus fréquents dans le corpus.
Ces outils vous offrent un aperçu global des entités présentes et mettent également en évidence les incohérences ou erreurs à corriger.
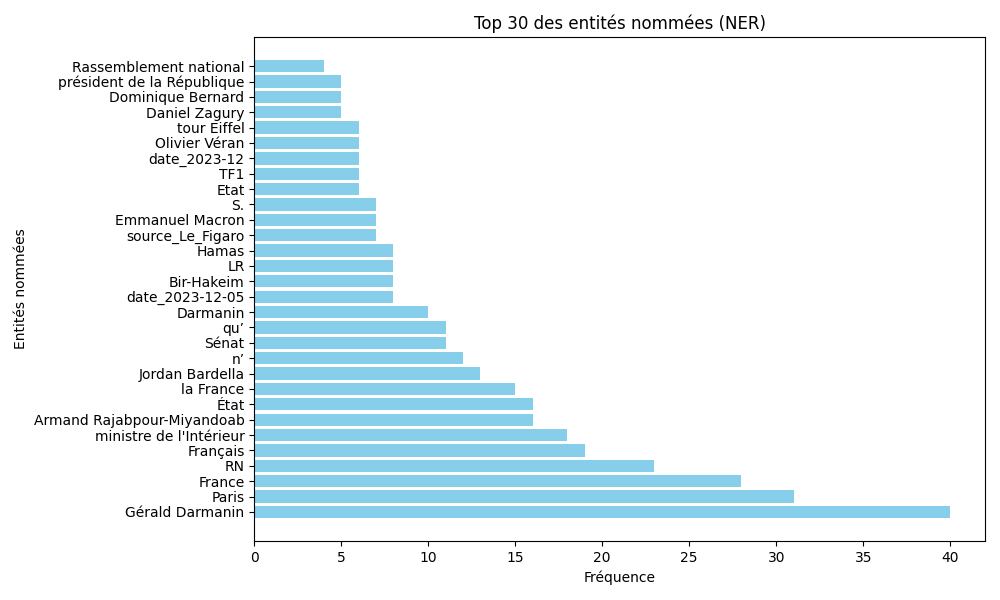
Dans mon exemple, l’export du top 30 des NER en fréquence montre clairement que les résultats ne sont pas toujours “précis”… Cela souligne l’importance d’une étape de correction, notamment en redéfinissant ou ajustant les NER dans le fichier JSON.
Code source
Voici le code source plutôt simple à mettre en œuvre. Il est indispensable d’installer les librairies à partir de votre terminal.
pip install spacy matplotlib pandas python -m spacy download fr_core_news_sm
Vous pouvez changer de modèle SpaCy et spécifier un modèle comme small (sm), medium (md) ou large (lg) dans votre code. Cependant, même si je n’ai pas testé personnellement, je doute que cela améliore significativement la détection des NER.
Pour faire fonctionner le script, vous devez également créer un fichier JSON nommé labels_corrections.json.
# Charger le mapping des corrections d'étiquettes depuis le fichier JSON
with open('labels_corrections.json', 'r', encoding='utf-8') as f:
labels_corrections = json.load(f)
Si, en exécutant le script dans votre terminal, vous repérez des NER incorrects, vous pouvez les corriger dans votre fichier JSON en précisant qu’ils doivent être ignorés.
# Si la correction est "IGNORER", on saute cette entité
if correction == "IGNORER":
continue
# Si une correction spécifique existe, on applique la nouvelle étiquette
nouvelle_etiquette = correction if correction else ent.label_
entites_corrigees.append((texte_entite, nouvelle_etiquette))
Le code source complet
Voici l’intégralité du code source utilisé pour ce projet.
import spacy
import matplotlib.pyplot as plt
from collections import Counter
import pandas as pd
import os, json
import re
# Charger le modèle français de spaCy
nlp = spacy.load("fr_core_news_sm") # version "sm" => small
print(nlp.get_pipe("ner").labels)
# Charger votre fichier texte
chemin_fichier = 'Le_chemin_de_votre_fichier_texte.txt'
with open(chemin_fichier, 'r', encoding='utf-8') as file:
texte = file.read()
base_dir = "Le_chemin_de_votre_repertoire" # le chemin du répertoire d'enregistrement
repertoire_ner = os.path.join(base_dir, "NER") # le nom du répertoire d'enregistrement
# Nettoyer le texte : supprimer chiffres et caractères spéciaux indésirables
texte_nettoye = re.sub(r'[\d\W_]+', ' ', texte)
doc = nlp(texte)
print(texte)
# Charger le mapping des corrections d'étiquettes depuis le fichier JSON
with open('labels_corrections.json', 'r', encoding='utf-8') as f: # le nom du fichier de vos correction
labels_corrections = json.load(f)
entites_corrigees = []
for ent in doc.ents:
texte_entite = ent.text.strip()
# Vérifier si une correction ou instruction existe pour cette entité
correction = labels_corrections.get(texte_entite)
# Si la correction est "IGNORER", on ignore cette entité
if correction == "IGNORER":
continue
# Si une correction spécifique existe, on applique la nouvelle étiquette
nouvelle_etiquette = correction if correction else ent.label_
entites_corrigees.append((texte_entite, nouvelle_etiquette))
# Créer un DataFrame pour visualiser les entités corrigées
df_entites = pd.DataFrame(entites_corrigees, columns=['Entité', 'Étiquette'])
print("Aperçu des entités corrigées :")
print(df_entites.head(50)) # on affiche 50 NER dans le terminal Python
# Construire le compteur à partir des entités corrigées
ner_counter = Counter([ent[0] for ent in entites_corrigees if len(ent[0].strip()) > 1 and any(char.isalpha() for char in ent[0].strip())])
def sauvegarder_resultats_ner(df_entites, ner_counter, repertoire="NER"):
os.makedirs(repertoire, exist_ok=True)
# Sauvegarder le DataFrame des entités en CSV
chemin_csv = os.path.join(repertoire, "entites_ner.csv")
df_entites.to_csv(chemin_csv, index=False, encoding='utf-8')
print(f"Tableau CSV sauvegardé dans : {chemin_csv}")
# Sauvegarder le graphique des top 30 NER
top_ner = ner_counter.most_common(30) # On extrait les 30 NER les plus fréquentes
if top_ner:
entities, frequencies = zip(*top_ner)
plt.figure(figsize=(10, 6))
plt.barh(entities, frequencies, color='skyblue')
plt.title('Top 30 des entités nommées (NER)')
plt.xlabel('Fréquence')
plt.ylabel('Entités nommées')
plt.tight_layout()
chemin_image = os.path.join(repertoire, "top20_ner.png")
plt.savefig(chemin_image)
plt.close()
print(f"Graphique NER sauvegardé dans : {chemin_image}")
else:
print("Aucune entité nommée trouvée pour générer le graphique.")
# Appel de la fonction de sauvegarde avec le répertoire spécifié
sauvegarder_resultats_ner(df_entites, ner_counter, repertoire=repertoire_ner)
Conclusion
L’exploitation des NER dans le cadre des SHS laisse une impression mitigée. Si cette approche permet de faire ressortir des mots-clés ciblés et organisés par des labels définis par SpaCy (ou personnalisés via un examen manuel du corpus), elle reste limitée dans son application. Le script présenté ici offre une vue d’ensemble intéressante : il identifie les principales entités et fournit une distribution en fréquences, ce qui peut constituer une base pour une première exploration d’un corpus. Cependant, en l’état, cela reste une analyse descriptive et superficielle.
Pour aller au-delà et affiner l’extraction et l’analyse des entités, il pourrait être pertinent d’explorer des alternatives comme la fonction “match patterns” dans SpaCy.
Cette méthode, que nous aborderons dans un prochain article, offre une plus grande flexibilité en permettant de définir des règles précises adaptées aux spécificités de votre corpus. Ainsi, elle pourrait s’avérer plus adaptée aux besoins des SHS, où les relations contextuelles et les subtilités sémantiques jouent un rôle essentiel.