Le développement de ce script s’inscrit dans une approche exploratoire d’analyse multimodale, visant à combiner deux couches de données : la couche « image » avec la détection des émotions et la couche « texte ».
Ces deux couches sont synchronisées, bien qu’à ce stade, aucune analyse automatique croisée entre elles ne soit proposée. Cependant, des pistes comme le calcul de distances entre vecteurs ou la similarité cosinus pourraient être explorées à l’avenir.
Nous y reviendrons plus tard !
Le script permet donc d’extraire les émotions détectées à partir des images et de synchroniser ces informations avec le texte de l’orateur. (Le script ICI sur Ghitub ! ou en bas de cet article)
L’objectif principal est d’essayer d’identifier des « vecteurs émotionnels » à travers des vidéos.
Ce script a été testé sur deux discours : le premier, celui d’Emmanuel Macron sur le harcèlement, et le second, une intervention du Premier ministre Michel Barnier (résumé).
La deuxième vidéo met rapidement en évidence les limites du modèle pré-entraîné FER2013 (basé sur environ 35 000 images). La différence entre ces deux discours réside notamment dans le positionnement de l’orateur : dans le premier cas, l’orateur est face caméra, tandis que dans le second, il est souvent de profil ou filmé en plongée, ce qui complique la détection des visages.
Ne soyez donc pas surpris si vous rencontrez des cellules « none » dans la dataframe, indiquant que l’algorithme n’a pas réussi à détecter un visage.
Les points à améliorer… ou pas…
Voici quelques questions et remarques importantes à considérer :
Le modèle FER 2013 est-il précis ?
Le script utilise un modèle pré-entraîné FER2013 basé sur 35 000 images. Ce n’est pas le modèle le plus précis, mais il est très flexible et facile à utiliser. Des comparaisons seront effectuées avec d’autres modèles pré-entraînés tels que DeepFace (de Facebook/Méta) et YOLOv8, un modèle populaire pour la reconnaissance faciale et d’objets. Il sera intéressant de tester ces différents modèles sur la même vidéo afin d’observer empiriquement les différences de performance dans la reconnaissance faciale.
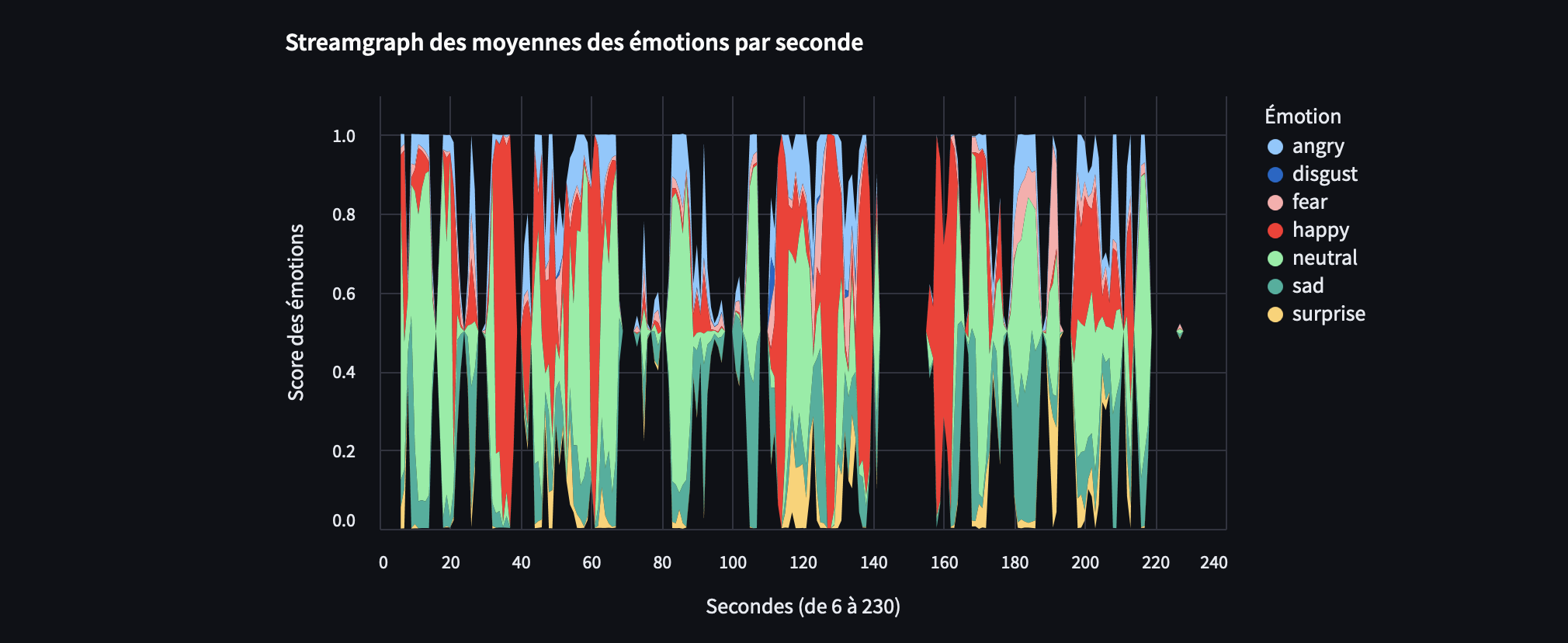
Quelles informations avons-nous sur le jeu de données FER2013 ?
Très peu d’informations sont disponibles. Le dataset FER2013 contient 35 887 images de petite taille (48×48 pixels), destinées à l’apprentissage supervisé. Les images sont étiquetées manuellement selon sept émotions : bonheur, tristesse, colère, surprise, dégoût, peur et neutralité. Bien que ces labels soient courants, ils sont assez généraux. Il est légitime de se demander s’ils sont adaptés à l’analyse de discours politiques, par exemple. En effet, une approche empirique de l’analyse des émotions dans les discours politiques (Marion Ballet, 2014) se concentre sur des émotions spécifiques comme la peur, l’indignation, l’espoir et la compassion, qui diffèrent des catégories utilisées dans FER2013.
Existe-t-il d’autres jeux de données ?
Oui, en explorant le web, on peut trouver des datasets susceptibles de mieux correspondre à notre problématique de reconnaissance des émotions. Toutefois, l’utilisation de jeux de données pré-entraînés ne garantit pas l’absence de biais méthodologiques, liés par exemple à la constitution de la base de données (population, origine des données,…).
L’idéal serait de créer son propre jeu de données, mais comme vous pouvez l’imaginer, l’apprentissage supervisé implique un travail conséquent, notamment pour l’étiquetage manuel des images.
Fonctionnalités du script
La première version du script était une version préparatoire, conçue pour être opérationnelle dans l’extraction d’une seule image.
Les fonctionnalités ont depuis été enrichies pour traiter des vidéos plus longues.
Voici les principales fonctionnalités du script :
- Extraction de vidéos longues de plusieurs minutes
- Génération de dataframes des scores d’émotions, calculés par image (fps) et par seconde
- Production de distributions de fréquence des frames, ainsi que des moyennes des probabilités des émotions sur une seconde
- Graphiques des distributions en fréquences et de la variance
- Comparaison des moyennes des émotions avec leurs variances pour observer les écarts
- Exploration d’un concordancier alignant les transcriptions de l’orateur (issues de Google) avec les frames et les scores des émotions (fichiers csv et xls)
- A titre exploratoire : clusters d’émotions via l’ACP (Analyse en Composantes Principales) et le test K-means
- Courbe de silhouette pour déterminer automatiquement le nombre « k »
- Tableau détaillant la variance expliquée par chaque composante principale
- Moyennes des émotions par clusters pour une analyse exploratoire
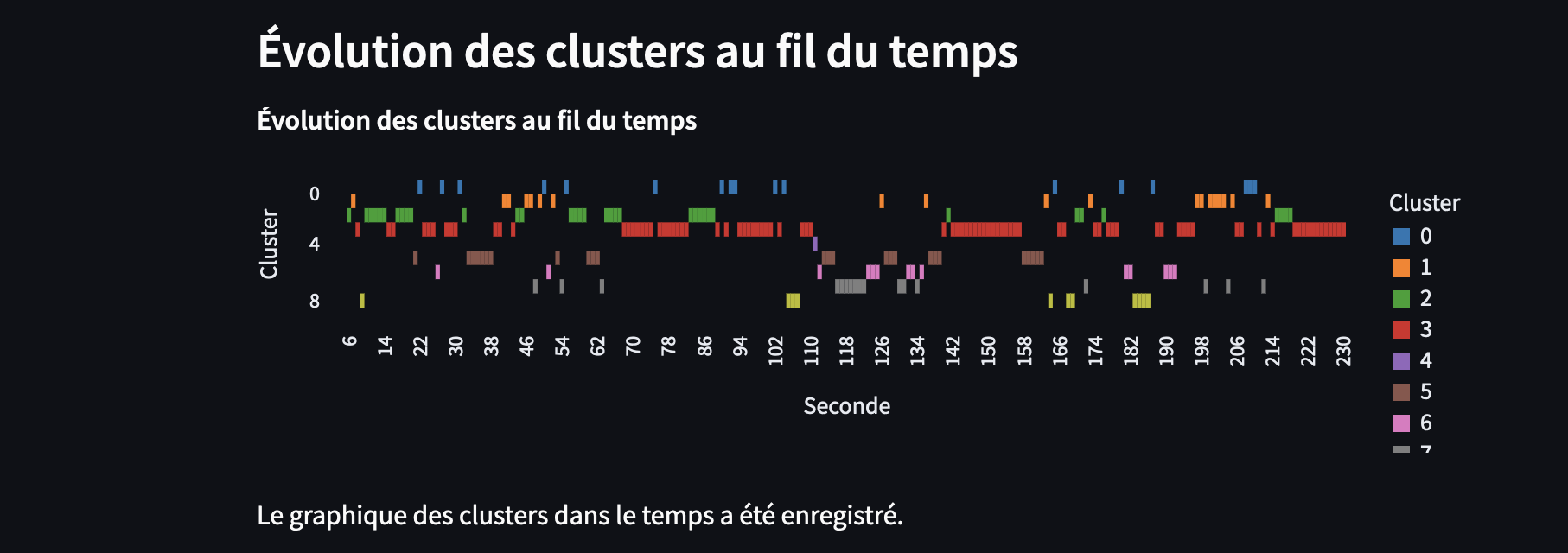
- Évolution des clusters dans le temps
- Calcul exploratoire de la similarité cosinus entre les différents clusters d’émotions
Calcul et réduction de l’information : choix de la granularité
Dans le script, j’ai choisi de conserver la seconde comme unité de temps. Ainsi, les émotions des 25 images par seconde (fps) sont moyennées, ce qui permet de simplifier les calculs pour l’ACP (PCA) et K-means.
Pour chaque observation, l’émotion présentant la moyenne la plus élevée est conservée. Cette approche permet de réduire la complexité des données tout en anticipant d’éventuels problèmes liés à la charge de calcul ou à la surchauffe de votre machine.
moyenne_emotions, _ = emotion_dominante_par_moyenne(emotions_25fps_list)
emotion_dominante_moyenne_results.append({'Seconde': seconde, **moyenne_emotions})
df_emotions = pd.DataFrame(results_25fps)
df_emotion_dominante_moyenne = pd.DataFrame(emotion_dominante_moyenne_results)
En moyennant les émotions sur une seconde plutôt qu’en prenant chaque frame indépendamment, on réduit l’information, mais cela peut être avantageux pour notamment pour réduire la complexité des calculs. Au lieu de traiter 25 frames par seconde, vous condensez les données en une seule observation par seconde, ce qui allège la taille des données et diminue les calculs. De plus, en moyennant sur une seconde, les petites fluctuations (comme les micro-expressions) sont lissées, ce qui permet de se concentrer sur les tendances émotionnelles plus globales dans la vidéo.
Exploration avec PCA et Kmeans :
La démarche de réduction d’information par « moyennage », PCA, et KMeans s’inscrivent dans une logique d’optimisation des calculs tout en maximisant la variance utile pour une analyse cohérente des émotions.
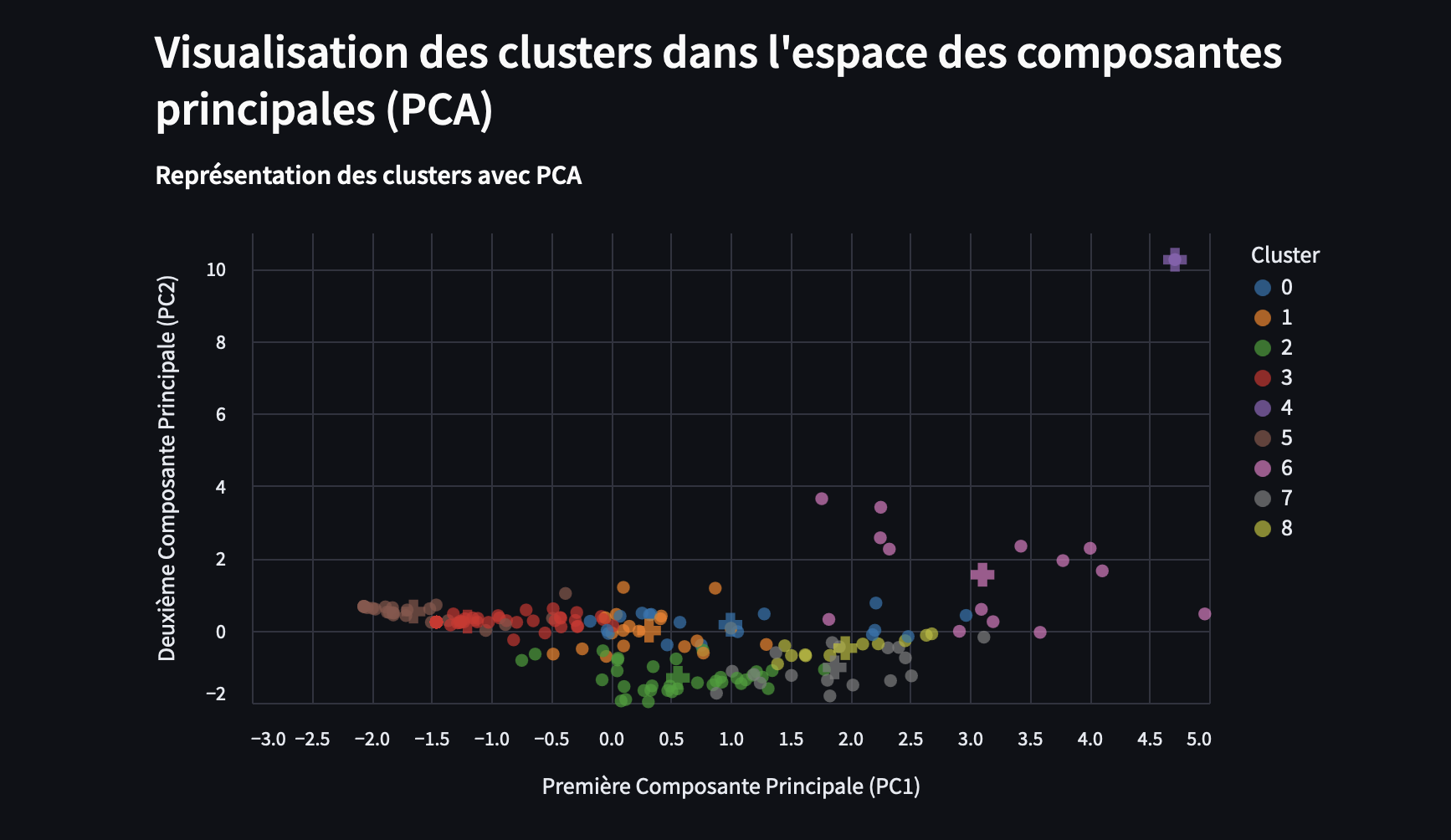
L’approche PCA et K-means utilisée dans ce script a donc été conçue pour traiter des vidéos longues. Lorsqu’on analyse des vidéos de plusieurs minutes, il est crucial de réduire la quantité de données tout en conservant l’essentiel.
En moyennant les émotions par seconde, puis en appliquant une réduction de dimension par PCA, on simplifie la structure des données tout en maximisant la variance expliquée.
Cela permet ensuite à K-means de créer des clusters émotionnels, révélant des tendances globales sans être noyé dans les détails.
Pour des vidéos courtes (comme celle de mon exemple, 3 minutes), cette approche est moins pertinente car elle risque de perdre des micro-variations émotionnelles intéressantes.
Cependant, j’ai conservé cette méthode dans le script à titre exploratoire, car elle pourrait encore fournir des insights utiles lors de l’analyse de longues vidéos.
La PCA permet ici de maximiser l’information tout en réduisant la complexité des calculs, facilitant ainsi le clustering par K-means dans des espaces à plus faible dimension.
C’est une méthode classique pour traiter de grandes quantités de données, bien que son efficacité puisse varier en fonction de la longueur des vidéos analysées.
Conclusion : Réflexions sur un second script basé sur l’analyse de chaque frame
Dans la continuité de ce travail, il serait intéressant d’explorer l’analyse de chaque frame individuellement, inversant ainsi la logique de réduction d’information. Cela permettrait de capturer toutes les variations fines des émotions, sans les lisser par des moyennes, offrant ainsi une granularité plus détaillée. A explorer !
Cependant, cette approche augmentera la complexité des calculs, car le nombre d’observations à traiter dans les analyses par PCA et K-means serait considérablement plus élevé.
Néanmoins, une telle approche permettrait de mieux appréhender les dynamiques émotionnelles, en révélant des émotions subtiles qui pourraient être masqués par un lissage à la seconde. A suivre …
Le code source
##########################################
# Projet : Vecteur Emotionnel - v1 - FER - Moyenne - PCA - Kmeans
# Version : 1.0
# Auteur : Stéphane Meurisse
# Contact : stephane.meurisse@example.com
# Site Web : https://www.codeandcortex.fr
# LinkedIn : https://www.linkedin.com/in/st%C3%A9phane-meurisse-27339055/
# Date : 22 octobre 2024
##########################################
# Bibliothèques nécessaires pour l'analyse des émotions, clustering et visualisations
# Commandes d'installation :
# pip install opencv-python-headless fer pandas matplotlib altair xlsxwriter scikit-learn numpy streamlit tensorflow
# yt_dlp seaborn
# pip install altair_saver
# pip install streamlit
# pip install youtube_transcript_api
# pip install tensorflow-metal -> pour Mac M1 et +
# pip install vl-convert-python
# FFmpeg -> Utilisation de Homebrew pour installation sous Mac
import streamlit as st
import subprocess
import os
import numpy as np
from fer import FER
import cv2
from yt_dlp import YoutubeDL
import altair as alt
# import altair_saver
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics import silhouette_score
import pandas as pd
import shutil # Pour suppression du répertoire
from youtube_transcript_api import YouTubeTranscriptApi
##########################################
# Fonctions pour la gestion des fichiers et des répertoires
##########################################
def vider_cache():
st.cache_resource.clear()
st.write("Cache vidé systématiquement au lancement du script")
def definir_repertoire_travail():
repertoire = st.text_input("Définir le répertoire de travail", "", key="repertoire_travail")
if not repertoire:
st.write("Veuillez spécifier un chemin valide.")
return ""
repertoire = os.path.abspath(repertoire.strip())
images_25fps = os.path.join(repertoire, "images_25fps")
if os.path.exists(images_25fps):
shutil.rmtree(images_25fps)
st.write(f"Le répertoire {images_25fps} et son contenu ont été supprimés.")
if not os.path.exists(repertoire):
os.makedirs(repertoire)
st.write(f"Le répertoire a été créé : {repertoire}")
return repertoire
##########################################
# Fonctions pour le téléchargement de la vidéo
##########################################
def telecharger_video(url, repertoire):
video_path = os.path.join(repertoire, 'video.mp4')
if os.path.exists(video_path):
st.write(f"La vidéo est déjà présente : {video_path}")
return video_path
st.write(f"Téléchargement de la vidéo depuis {url}...")
ydl_opts = {'outtmpl': video_path, 'format': 'best'}
with YoutubeDL(ydl_opts) as ydl:
ydl.download([url])
st.write(f"Téléchargement terminé : {video_path}")
return video_path
##########################################
# Fonctions pour le traitement d'images et extraction à 25fps
##########################################
def extraire_images_25fps_ffmpeg(video_path, repertoire, seconde):
images_extraites = []
for frame in range(25):
image_path = os.path.join(repertoire, f"image_25fps_{seconde}_{frame}.jpg")
if os.path.exists(image_path):
images_extraites.append(image_path)
continue
time = seconde + frame * (1 / 25)
cmd = ['ffmpeg', '-ss', str(time), '-i', video_path, '-frames:v', '1', '-q:v', '2', image_path]
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if result.returncode != 0:
st.write(f"Erreur FFmpeg à {time} seconde : {result.stderr.decode('utf-8')}")
break
images_extraites.append(image_path)
return images_extraites
##########################################
# Traitement des émotions avec FER et calcul des moyennes
##########################################
def analyser_image(image_path, detector):
### Analyse une image avec FER pour détecter les émotions. Ajoute un cadre vert autour du visage
### détecté et affiche les scores des émotions sur l'image.
image = cv2.imread(image_path)
if image is None:
return {}
# Utiliser le détecteur FER pour analyser l'image
resultats = detector.detect_emotions(image)
if resultats:
for result in resultats:
# Récupérer la boîte englobante (rectangle) du visage détecté
(x, y, w, h) = result["box"]
# Dessiner le rectangle vert autour du visage
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Ajouter le score des émotions sous le rectangle
emotions = result['emotions']
for idx, (emotion, score) in enumerate(emotions.items()):
text = f"{emotion}: {score:.4f}"
cv2.putText(image, text, (x, y + h + 20 + (idx * 20)), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
# Sauvegarder l'image avec les annotations (rectangle et score) à la place de l'originale
cv2.imwrite(image_path, image)
return resultats[0]['emotions'] # Retourner les émotions détectées
return {}
##########################################
# Calcul de l'émotion dominante par moyenne
##########################################
def emotion_dominante_par_moyenne(emotions_list):
# Liste des émotions suivies
emotions = ['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']
# Calcul de la moyenne pour chaque émotion
moyenne_emotions = {emotion: np.mean([emo.get(emotion, 0) for emo in emotions_list]) for emotion in emotions}
# Identification de l'émotion dominante
emotion_dominante = max(moyenne_emotions, key=moyenne_emotions.get)
return moyenne_emotions, emotion_dominante
##########################################
# Fonction pour récupérer les sous-titres d'une vidéo YouTube
##########################################
def obtenir_sous_titres_youtube(video_url):
try:
# Extraire l'ID de la vidéo YouTube à partir de l'URL
video_id = video_url.split("v=")[1]
# Essayer de récupérer les sous-titres en anglais d'abord
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=['fr'])
except Exception:
# Si les sous-titres en anglais ne sont pas disponibles, récupérer ceux en français
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=['en'])
# Organiser les sous-titres par seconde
sous_titres_par_seconde = {}
for entry in transcript:
start_time = int(entry['start'])
text = entry['text']
sous_titres_par_seconde[start_time] = text
return sous_titres_par_seconde
except Exception as e:
st.write(f"Erreur lors de la récupération des sous-titres: {str(e)}")
return {}
##########################################
# Fonction pour créer le Concordancier
##########################################
def creer_concordancier(images_data, emotions_data, sous_titres_df, repertoire, start_time, end_time):
### Crée un concordancier associant les images extraites, les émotions moyennes et les sous-titres
### pour chaque seconde de la vidéo.
data_concordancier = {
'Seconde': [],
'Images': [],
'Moyenne_Emotions': [], # Colonne pour stocker les émotions moyennes
'Sous_Titres': []
}
# Associer les sous-titres à chaque seconde analysée
for seconde in range(start_time, end_time + 1):
images = images_data[seconde - start_time] # Ajuster pour utiliser le bon index
moyenne_emotions = emotions_data[seconde - start_time]
# Chercher le sous-titre correspondant dans le dataframe
texte_sous_titre = sous_titres_df.get(seconde, "Aucun sous-titre disponible")
data_concordancier['Seconde'].append(seconde)
data_concordancier['Images'].append([os.path.basename(img) for img in images])
data_concordancier['Moyenne_Emotions'].append(moyenne_emotions) # Ajouter les émotions moyennes
data_concordancier['Sous_Titres'].append(texte_sous_titre)
# Convertir le dictionnaire en DataFrame
df_concordancier = pd.DataFrame(data_concordancier)
# Exporter le concordancier en fichier Excel
df_concordancier.to_excel(os.path.join(repertoire, "concordancier_emotions.xlsx"), index=False)
# Exporter le concordancier en fichier CSV
df_concordancier.to_csv(os.path.join(repertoire, "concordancier_emotions.csv"), index=False)
st.write("Concordancier généré et exporté dans 'concordancier_emotions.xlsx' et 'concordancier_emotions.csv'")
##########################################
# Affichage : DataFrames et Streamgraphs
##########################################
def afficher_dataframe_et_streamgraph(df_emotions, df_emotion_dominante_moyenne, start_time, end_time):
st.subheader("Scores des émotions par frame (25 fps)")
st.dataframe(df_emotions)
df_emotions['Frame_Index'] = df_emotions.apply(lambda x: x['Seconde'] * 25 + int(x['Frame'].split('_')[1]), axis=1)
df_streamgraph_frames = df_emotions.melt(id_vars=['Frame_Index', 'Seconde'],
value_vars=['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral'],
var_name='Emotion', value_name='Score')
streamgraph_frames = alt.Chart(df_streamgraph_frames).mark_area().encode(
x=alt.X('Frame_Index:Q', title='Frame Index'),
y=alt.Y('Score:Q', title='Score des émotions', stack='center'),
color=alt.Color('Emotion:N', title='Émotion'),
tooltip=['Frame_Index', 'Emotion', 'Score']
).properties(
title='Streamgraph des émotions par frame (25 fps)',
width=800,
height=400
)
st.altair_chart(streamgraph_frames, use_container_width=True)
streamgraph_frames.save(os.path.join(repertoire_travail, "streamgraph_frames.png"))
st.write("Moyenne des émotions par seconde")
st.dataframe(df_emotion_dominante_moyenne)
df_streamgraph_seconds = df_emotion_dominante_moyenne.melt(
id_vars=['Seconde'],
value_vars=['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral'],
var_name='Emotion', value_name='Score')
streamgraph_seconds = alt.Chart(df_streamgraph_seconds).mark_area().encode(
x=alt.X('Seconde:Q', title=f'Secondes (de {start_time} à {end_time})'),
y=alt.Y('Score:Q', title='Score des émotions', stack='center'),
color=alt.Color('Emotion:N', title='Émotion'),
tooltip=['Seconde', 'Emotion', 'Score']
).properties(
title='Streamgraph des moyennes des émotions par seconde',
width=800,
height=400
)
st.altair_chart(streamgraph_seconds, use_container_width=True)
streamgraph_frames.save(os.path.join(repertoire_travail, "streamgraph_secondes.png"))
##########################################
# Fonction d'optimisation du nombre de clusters via le score de silhouette
##########################################
def optimiser_clusters(X_pca):
scores = []
range_n_clusters = list(range(2, min(10, X_pca.shape[0])))
if len(range_n_clusters) < 2:
st.write(f"Impossible de calculer le nombre optimal de clusters : seulement {X_pca.shape[0]} échantillons.")
return None
for n_clusters in range_n_clusters:
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
kmeans.fit(X_pca)
score = silhouette_score(X_pca, kmeans.labels_)
scores.append(score)
df_silhouette = pd.DataFrame({'Nombre de clusters': range_n_clusters, 'Score de silhouette': scores})
silhouette_chart = alt.Chart(df_silhouette).mark_line(point=True).encode(
x=alt.X('Nombre de clusters:Q', title='Nombre de clusters'),
y=alt.Y('Score de silhouette:Q', title='Score de silhouette'),
tooltip=['Nombre de clusters', 'Score de silhouette']
).properties(
title="Score de silhouette en fonction du nombre de clusters",
width=600,
height=400
)
st.markdown("""
### Interprétation de la courbe de silhouette
- Dans le cadre de Kmeans, il est obligatoire de déterminer en amont du test le nombre de clusters.
- La courbe de silhouette est donc un pré-test de kmeans (évitant une approche itérative) pour déterminer le nombre "k".
""")
st.altair_chart(silhouette_chart, use_container_width=True)
st.write(f"Le nombre optimal de clusters déterminé par la méthode de silhouette est : {n_clusters}")
return range_n_clusters[scores.index(max(scores))]
##########################################
# Visualisation des clusters après PCA et KMeans
##########################################
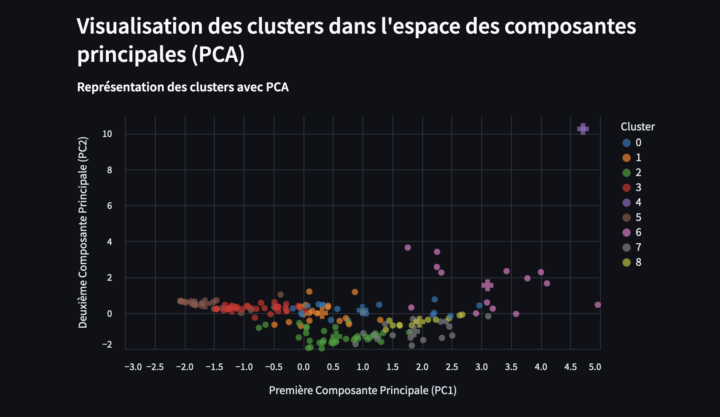
def visualiser_pca_kmeans(X_pca, df_emotion_dominante_moyenne, kmeans, n_clusters):
st.subheader("Visualisation des clusters dans l'espace des composantes principales (PCA)")
df_emotion_dominante_moyenne['PC1'] = X_pca[:, 0]
df_emotion_dominante_moyenne['PC2'] = X_pca[:, 1]
cluster_chart = alt.Chart(df_emotion_dominante_moyenne).mark_circle(size=60).encode(
x=alt.X('PC1:Q', title='Première Composante Principale (PC1)'),
y=alt.Y('PC2:Q', title='Deuxième Composante Principale (PC2)'),
color=alt.Color('Cluster:N', scale=alt.Scale(scheme='category10')),
tooltip=['Seconde', 'Cluster', 'angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']
).properties(
title='Représentation des clusters avec PCA',
width=600,
height=400
)
centroids = kmeans.cluster_centers_
df_centroids = pd.DataFrame(centroids[:, :2], columns=['PC1', 'PC2'])
df_centroids['Cluster'] = range(n_clusters)
centroid_chart = alt.Chart(df_centroids).mark_point(size=200, shape='cross', filled=True).encode(
x='PC1:Q', y='PC2:Q', color=alt.Color('Cluster:N', scale=alt.Scale(scheme='category10'))
)
clustering_plot = cluster_chart + centroid_chart
st.altair_chart(clustering_plot, use_container_width=True)
cluster_chart.save(os.path.join(repertoire_travail, "clusters.png"))
##########################################
# Similarité cosinus
##########################################
# Calcul de la similarité cosinus entre les clusters
st.subheader("Analyse de similarité cosinus entre clusters")
# Calcul de la similarité cosinus entre les centroïdes des clusters
similarites = cosine_similarity(kmeans.cluster_centers_)
df_similarite_cosinus = pd.DataFrame(similarites, columns=[f'Cluster {i}' for i in range(n_clusters)],
index=[f'Cluster {i}' for i in range(n_clusters)])
# Afficher le tableau des similarités
st.dataframe(df_similarite_cosinus)
# Visualisation de la similarité cosinus entre les clusters avec une carte chaude (heatmap)
st.subheader("Heatmap de la similarité cosinus entre les clusters")
similarities = cosine_similarity(kmeans.cluster_centers_)
df_similarite_cosinus = pd.DataFrame(similarities,
columns=[f'Cluster {i}' for i in range(n_clusters)],
index=[f'Cluster {i}' for i in range(n_clusters)])
# Générer la heatmap avec les annotations (valeurs dans les cellules)
fig, ax = plt.subplots()
sns.heatmap(df_similarite_cosinus, annot=True, cmap="coolwarm", ax=ax, fmt=".2f")
st.pyplot(fig)
# Ajout d'une explication sous le graphique
st.markdown("""
### Interprétation des résultats de similarité cosinus
- **Similarité cosinus entre les centroïdes des clusters** :
- Cette mesure vous permet de comprendre à quel point les clusters sont proches les uns des autres dans l'espace des composantes principales (PCA).
- Une valeur proche de 1 indique que deux clusters sont très similaires dans cet espace. Cela peut signifier que ces clusters capturent des combinaisons émotionnelles proches dans l'analyse.
""")
##########################################
# Visualisation des clusters dans le temps
##########################################
# Calcul de l'émotion dominante pour chaque seconde en fonction des scores d'émotions
emotions_columns = ['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']
# Pour chaque ligne, on identifie l'émotion avec le score le plus élevé
df_emotion_dominante_moyenne['Emotion_Dominante'] = df_emotion_dominante_moyenne[emotions_columns].idxmax(axis=1)
# Ajouter une colonne représentant le nom du cluster pour plus de clarté
df_emotion_dominante_moyenne['Cluster_Label'] = 'Cluster ' + df_emotion_dominante_moyenne['Cluster'].astype(str)
# Visualisation des clusters dans le temps
st.subheader("Évolution des clusters au fil du temps")
# Visualiser les clusters dans le temps (par seconde)
df_cluster_time = df_emotion_dominante_moyenne[['Seconde', 'Cluster']]
cluster_time_chart = alt.Chart(df_cluster_time).mark_rect().encode(
x=alt.X('Seconde:O', title='Seconde'),
y=alt.Y('Cluster:O', title='Cluster'),
color=alt.Color('Cluster:N', scale=alt.Scale(scheme='category10')),
tooltip=['Seconde', 'Cluster']
).properties(
title="Évolution des clusters au fil du temps",
width=600,
height=200
)
st.altair_chart(cluster_time_chart, use_container_width=True)
# Enregistrer le graphique en PNG (Altair ne gère pas directement l'enregistrement en PNG)
cluster_time_chart.save(os.path.join(repertoire_travail, "clusters_temps.png")) # Sauvegarde PNG
st.write("Le graphique des clusters dans le temps a été enregistré.")
##########################################
# Moyenne des émotions par cluster
##########################################
st.subheader("Moyenne des émotions par cluster")
# Calculer la moyenne des émotions pour chaque cluster
emotions = ['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']
for cluster in range(n_clusters):
st.write(f"#### Moyenne des émotions pour le Cluster {cluster}")
# Filtrer les données pour le cluster courant
df_cluster = df_emotion_dominante_moyenne[df_emotion_dominante_moyenne['Cluster'] == cluster]
# Calculer la moyenne des émotions pour ce cluster
df_cluster_mean = df_cluster[emotions].mean().reset_index()
df_cluster_mean.columns = ['Émotion', 'Moyenne']
# Afficher le tableau des moyennes pour ce cluster
st.dataframe(df_cluster_mean)
##########################################
# Fonction principale d'analyse de la vidéo
##########################################
def analyser_video(video_url, start_time, end_time, repertoire_travail):
st.write(f"Analyse de la vidéo entre {start_time} et {end_time} seconde(s)")
repertoire_25fps = os.path.join(repertoire_travail, "images_25fps")
os.makedirs(repertoire_25fps, exist_ok=True)
video_path = telecharger_video(video_url, repertoire_travail)
detector = FER()
results_25fps = []
emotion_dominante_moyenne_results = []
images_data = []
sous_titres = obtenir_sous_titres_youtube(video_url)
for seconde in range(start_time, end_time + 1):
images_25fps = extraire_images_25fps_ffmpeg(video_path, repertoire_25fps, seconde)
images_data.append(images_25fps)
emotions_25fps_list = [analyser_image(image_path, detector) for image_path in images_25fps]
results_25fps.extend([{'Seconde': seconde, 'Frame': f'25fps_{seconde * 25 + idx}', **emotions}
for idx, emotions in enumerate(emotions_25fps_list)])
moyenne_emotions, _ = emotion_dominante_par_moyenne(emotions_25fps_list)
emotion_dominante_moyenne_results.append({'Seconde': seconde, **moyenne_emotions})
df_emotions = pd.DataFrame(results_25fps)
df_emotion_dominante_moyenne = pd.DataFrame(emotion_dominante_moyenne_results)
afficher_dataframe_et_streamgraph(df_emotions, df_emotion_dominante_moyenne, start_time, end_time)
# Création du concordancier après l'analyse des images et des émotions
creer_concordancier(images_data, emotion_dominante_moyenne_results, sous_titres, repertoire_travail, start_time,
end_time)
##########################################
# Affichage des moyennes et variances
##########################################
def moyenne_et_variance_par_emotion(emotions_list):
### Calcule la moyenne et la variance des émotions pour une liste de scores émotionnels par seconde.
### Renvoie un dictionnaire avec la moyenne et la variance pour chaque émotion.
emotions = ['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']
resultats = {}
for emotion in emotions:
emotion_scores = [emotion_dict.get(emotion, 0) for emotion_dict in emotions_list]
moyenne = np.mean(emotion_scores)
variance = np.var(emotion_scores)
resultats[emotion] = {'moyenne': moyenne, 'variance': variance}
return resultats
# Calcul des moyennes et variances
stats_par_seconde = moyenne_et_variance_par_emotion(emotion_dominante_moyenne_results)
if stats_par_seconde:
# Conversion des résultats en DataFrame
df_stats_seconde = pd.DataFrame(stats_par_seconde).T.reset_index()
df_stats_seconde.columns = ['Emotion', 'Moyenne', 'Variance']
st.write("#### Tableau des moyennes et variances des émotions par seconde")
st.dataframe(df_stats_seconde)
# Graphique combiné des moyennes et variances des émotions
moyenne_bar_seconde = alt.Chart(df_stats_seconde).mark_bar().encode(
x=alt.X('Emotion:N', title='Émotion'),
y=alt.Y('Moyenne:Q', title='Moyenne des probabilités'),
color=alt.Color('Emotion:N', legend=None)
)
variance_point_seconde = alt.Chart(df_stats_seconde).mark_circle(size=100, color='red').encode(
x=alt.X('Emotion:N', title='Émotion'),
y=alt.Y('Variance:Q', title='Variance des probabilités'),
tooltip=['Emotion', 'Variance']
)
graphique_combine_seconde = alt.layer(moyenne_bar_seconde, variance_point_seconde).resolve_scale(
y='independent').properties(width=600, height=400)
st.altair_chart(graphique_combine_seconde, use_container_width=True)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df_emotion_dominante_moyenne[['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']].values)
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# Extraction de la variance expliquée par chaque composante principale
explained_variance_ratio = pca.explained_variance_ratio_
# Créer un DataFrame avec la variance expliquée pour chaque composante principale
df_variance_expliquee = pd.DataFrame({
'Composante Principale': [f'PC{i + 1}' for i in range(len(explained_variance_ratio))],
'Variance expliquée (%)': explained_variance_ratio * 100
})
st.markdown("""
### Analyse avec PCA et Kmeans
""")
# Markdown explicatif pour le graphique d'inertie
st.markdown("""
Inertie (Variance expliquée) pour chaque axe de la PCA
- Une composante avec une forte variance explique une part importante de la variabilité des données.
""")
# Afficher le tableau de la variance expliquée par chaque composante
st.write("#### Tableau de la variance expliquée par chaque composante principale")
st.dataframe(df_variance_expliquee)
# Visualisation en graphique à barres de la variance expliquée
variance_chart = alt.Chart(df_variance_expliquee).mark_bar().encode(
x=alt.X('Composante Principale', sort=None),
y=alt.Y('Variance expliquée (%)'),
tooltip=['Composante Principale', 'Variance expliquée (%)']
).properties(
title="Variance expliquée par chaque composante principale",
width=600,
height=400
)
st.altair_chart(variance_chart, use_container_width=True)
n_clusters = optimiser_clusters(X_pca)
if n_clusters is not None and n_clusters >= 2 and n_clusters <= X_pca.shape[0]:
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
df_emotion_dominante_moyenne['Cluster'] = kmeans.fit_predict(X_pca)
visualiser_pca_kmeans(X_pca, df_emotion_dominante_moyenne, kmeans, n_clusters)
else:
st.write(f"Le nombre de clusters {n_clusters} est invalide pour {X_pca.shape[0]} échantillons.")
# Lancer la création du concordancier après les analyses
creer_concordancier(images_data, emotion_dominante_moyenne_results, sous_titres, repertoire_travail, start_time,
end_time)
##########################################
# Interface utilisateur avec Streamlit
##########################################
st.title("Recherche d'un vecteur émotionnel : Analyse des émotions dans une vidéo")
st.markdown("<h6 style='text-align: left;'>www.codeandcortex.fr</h6>", unsafe_allow_html=True)
st.markdown("Version 1.0")
vider_cache()
repertoire_travail = definir_repertoire_travail()
video_url = st.text_input("URL de la vidéo à analyser", "", key="video_url")
start_time = st.number_input("Temps de départ de l'analyse (en secondes)", min_value=0, value=0, key="start_time")
end_time = st.number_input("Temps d'arrivée de l'analyse (en secondes)", min_value=start_time, value=start_time + 1,
key="end_time")
if st.button("Lancer l'analyse"):
if video_url and repertoire_travail:
analyser_video(video_url, start_time, end_time, repertoire_travail)
else:
st.write("Veuillez définir le répertoire de travail et l'URL de la vidéo.")
[…] dans la continuité de mes travaux sur l’analyse des émotions, initialement explorés avec le modèle FER. À ma grande surprise, j’ai découvert les paramètres de DeepFace, qui laissent entrevoir une […]
[…] l’entraînement de la reconnaissance des émotions à partir des catégories de Paul Ekman (FER2013 – DeepFace, RAVDESS, […]
[…] article constitue (aussi) une exploration au sein d’un projet plus vaste intégrant une approche multimodale (Étude conjointe/synchronisée des indices vocaux, textuels et visuels) en sciences humaines et […]
[…] synchronisation précise entre l’image, le discours et l’émotion prédite est essentielle. Cependant, un autre point mérite réflexion : dans les segments où l’orateur ne parle pas, des i… – une sorte de « métacognition » (même si ce terme n’est peut-être pas adapté). Ces […]
[…] par exemple pour des analyses comme la détection des émotions faciales, (cf. article 1 – article 2 – article 3). Bon, c’est un petit retour en arrière, mais j’avais besoin […]
[…] C’est dans cette perspective que j’ai expérimenté l’analyse des émotions à l’aide d’un… Cette approche reste exploratoire, mais elle ouvre une voie vers une lecture plus fine de ces « entre-deux » cognitifs. Toutefois, le recours à des modèles d’émotions fondés sur des catégories dites « universelles » (Paul Ekmann) pose la question de leur réductivité, notamment face à la complexité des contextes socio-discursifs réels. […]