
No code !
Cette application en ligne est l’aboutissement de plusieurs scripts Python conçus pour transformer vos données HTML du site Europresse au format IRaMuTeQ.
Aujourd’hui, je vous présente la version 3.0.1, ne nécessitant aucune manipulation de code Python 😉 .
Vous pouvez suivre la démarche qui a conduit à cette version du script à travers les différents articles : Test sur un article – Vers la V2… – La révolution V2 !!!”
La grande nouveauté ? Plus besoin d’installer de bibliothèques Python ou de manipuler un environnement local : tout se fait directement en ligne.
Accessible via une simple URL, l’application garantit la confidentialité de vos fichiers et permet une utilisation ultra-simple grâce à un simple glisser-déposer de votre fichier HTML.
https://europresse-to-iramuteq.streamlit.app/
Le script est consultable sur Github, en licence GNU v3.
GitHub sert ici de dépôt pour les fichiers app.py (le script principal de l’application) et requirements.txt (pour l’installation des bibliothèques nécessaires). L’application est ensuite hébergée et exécutée via Streamlit Cloud, qui agit comme un serveur en lançant l’application directement à partir de son URL dédiée : https://europresse-to-iramuteq.streamlit.app/
Transparence sur la sécurité et le devenir de vos fichiers
Bien que Streamlit Cloud soit un service gratuit, la vigilance reste de mise lorsqu’il s’agit de données…
Il est légitime de s’interroger sur la sécurité et le traitement des fichiers HTML que vous déposez via l’application, notamment parce qu’elle est hébergée sur un environnement gratuit.

Ni les fichiers HTML que vous chargez, ni les sorties au format texte (.txt) ou CSV ne sont conservés sur le cloud. Une fois traités et téléchargés, vos fichiers ne laissent aucune trace sur les serveurs.
Streamlit Cloud exécute l’application dans des environnements isolés appelés “sessions”. Les fichiers que vous téléchargez sont conservés uniquement en mémoire (à court terme) pendant la durée de la session active, et ils sont supprimés automatiquement dès qu’elle se termine (par exemple, après un certain temps d’inactivité).

Les fichiers ne sont pas sauvegardés de manière permanente sur les serveurs de Streamlit (aucune base de données).
Les fonctionnalités de l’application
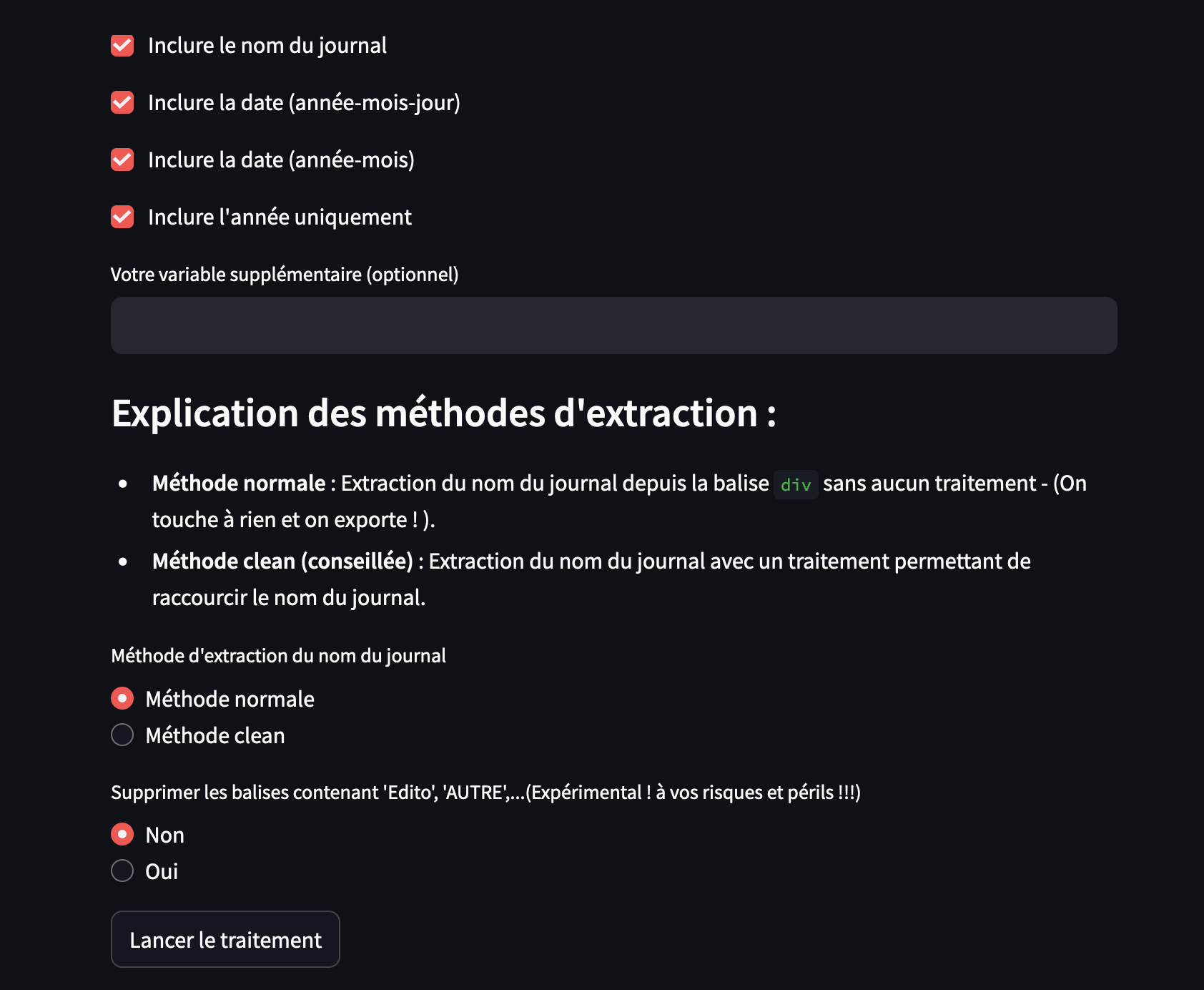
- Traitement des noms de journaux : Reconstruction du nom du journal avec deux formats au choix (version longue ou version abrégée / clean 😉.
- Reformatage des dates : Conversion des dates en français avec trois options (année-mois-jour, année-mois ou année).
- Ajout d’une variable étoilée : Possibilité d’ajouter une variable personnalisée qui sera insérée en première ligne (de tous les articles).
- Nettoyage des articles :
- Suppression des URL dans le texte.
- Élimination des balises (comme celles indiquant le nombre de pages).
- Nettoyage des noms d’auteurs, qui peuvent apparaître de manière anarchiques (parfois en fin d’article, parfois encapsulés dans des balises spécifiques).
- Suppression expérimentale de termes tels que “Édito” à partir d’un dictionnaire.
- Aperçu avant export : Visualisation du fichier avant son téléchargement.
- Export des fichiers : Téléchargement du résultat final au format texte (.txt) et CSV.
Points de vigilance
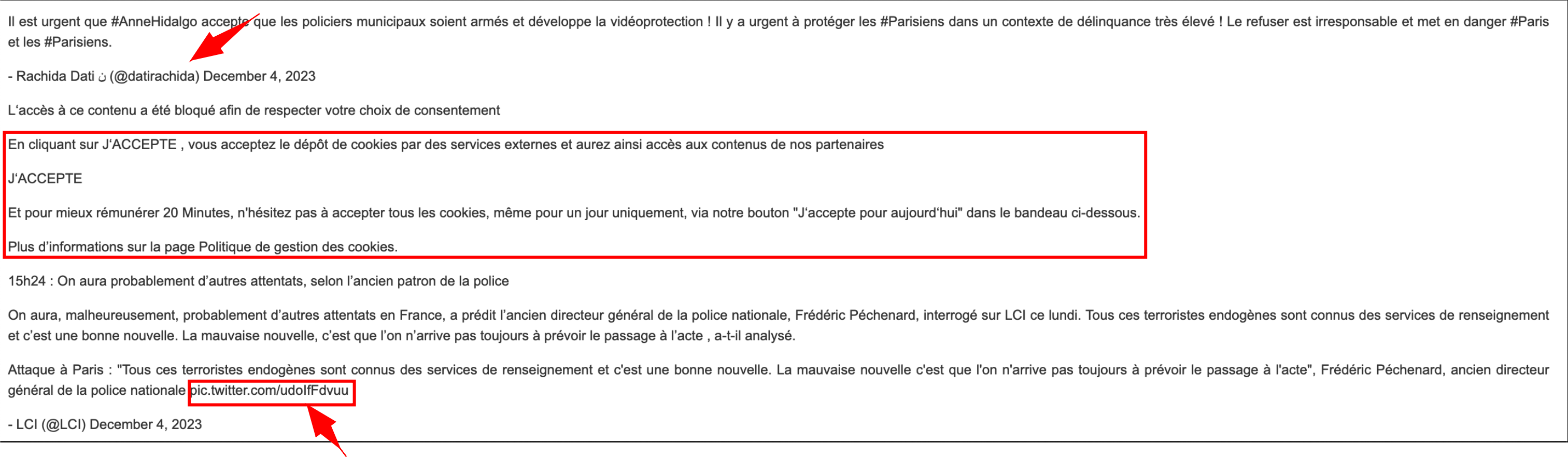
L’exportation des articles depuis Europresse au format HTML peut parfois générer des bugs inattendus, dont certains restent difficiles, voire impossibles à résoudre. Par exemple, comme vous pouvez le voir dans l’image ci-dessous (un amas de tweets), l’exportation d’un article provenant d’un site web de journal peut s’avérer particulièrement problématique. De façon générale, retenez que tous les articles provenant des éditions numériques ou web posent un problème d’optimisation du traitement.
Heureusement, pour la presse nationale “classique/print” (celle que j’ai testée le plus fréquemment), les articles obtenus sont exploitables.
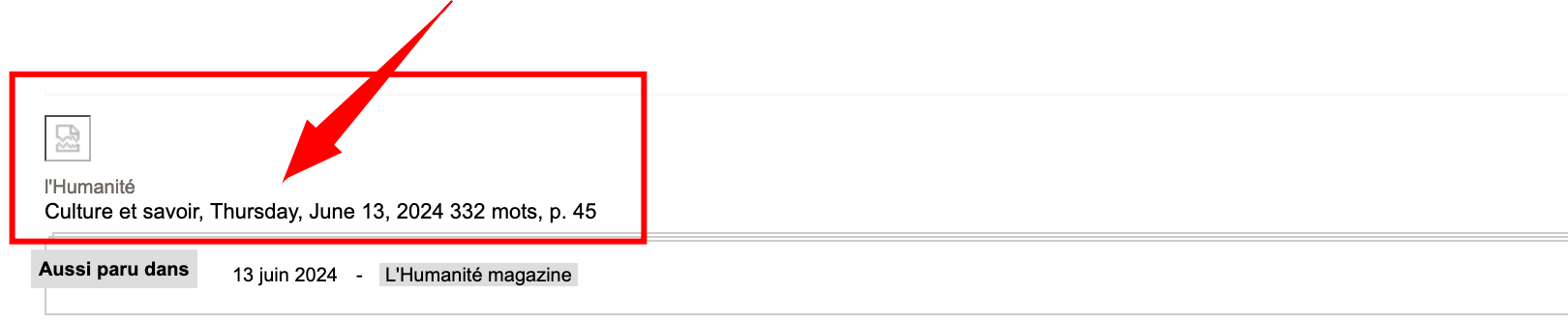
Pour des articles dont l’exportation présente une forme “normale”, j’ai toutefois rencontré un problème récurrent : la césure inappropriée de certains termes au sein de l’article dans le fichier généré par le script (au format txt), dans l’exemple ci-dessous le mot : “métho-dologie”.

En examinant le fichier HTML (celui issu de l’export)… ouf ! On retrouve exactement la même coquille !..

On voit donc que dans ce cas… il va être difficile de corriger ce problème par un traitement automatisé.
Donc dans votre fichier texte laissez le temps à votre éditeur de texte de surligner les terme incohérents vous pourrez ainsi les repérer rapidement (surligné en rouge) pour les corriger.
Le format des dates
Gérer le format des dates s’est avéré délicat à plusieurs niveaux.
- Streamlit Cloud utilise uniquement une locale anglaise (la “locale” désigne les paramètres définissant le format des dates, heures, chiffres,…). Il n’a donc pas été possible d’utiliser directement les fonctions de gestion des dates en français.
- Adaptation des formats : Le script convertit les dates du format français en anglais pour qu’elles soient lisibles et exploitables par l’application, avant de les réécrire en français dans le fichier texte final.
- Incohérences dans les articles : Certains articles html en français (version web) contenaient des dates rédigées en anglais… L’application convertit ces dates au format final en français.
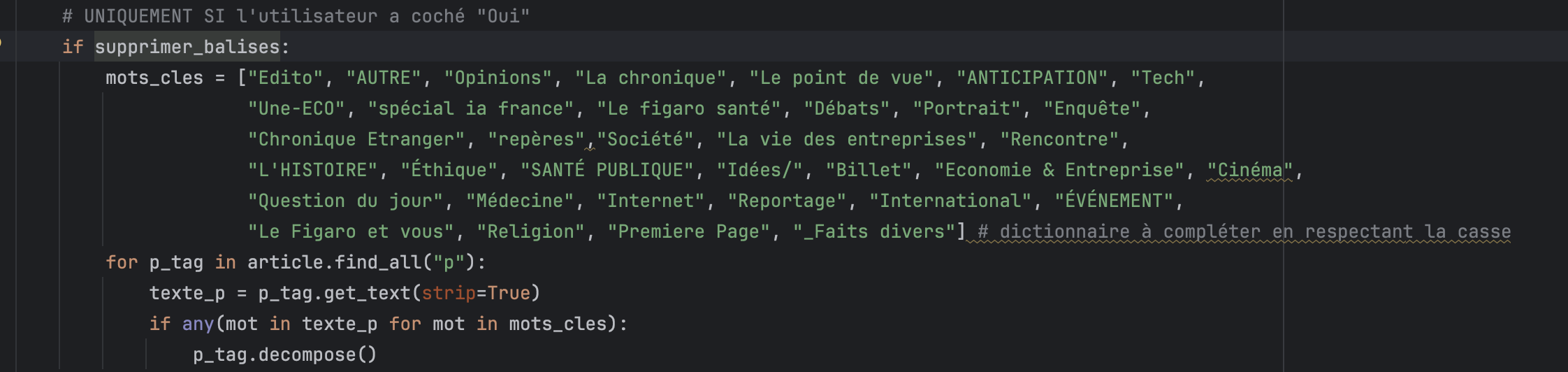
Suppression par dictionnaire de termes spécifiques
Certains termes spécifiques à des rubriques de journaux, comme “Édito” ou “Question du jour”…, ne sont pas extraits et peuvent être supprimés si vous activez l’option correspondante.

Cette fonctionnalité est encore expérimentale et loin d’être optimisée, car elle repose sur l’enrichissement progressif d’un dictionnaire. Vous pouvez contribuer à enrichir le dictionnaire en me contactant par e-mail ou, plus simplement, en laissant un commentaire sous l’article.
Le nom du journal
Vous avez la possibilité d’opter pour la version telle quelle provenant de la balise du fichier html ou la version raccourci (clean). Pour des raison de traitement dans des logiciels statistiques (chaine de caractères) il est largement conseillé d’opter pour la version raccourci (clean).
Dans un souci de transparence l’application exporte la version normale mais dont le nom est totalement indigeste notamment lorsqu’il s’agit de la presse régionale.
Même avec la version “clean” parfois le nom reste trop long…
Ajouter une variable supplémentaire : Une fonctionnalité adaptée aux exports thématiques (?)
À première vue, l’option permettant d’ajouter une variable supplémentaire peut sembler superflue, voire inutile. Cette fonctionnalité peut être particulièrement utile si vous réalisez des exports thématiques. Dans ce cas, le thème peut être intégré comme une “variable étoilée”.
Il vous suffit ensuite de concaténer vos exports dans un seul fichier en utilisant un simple copier-coller de vos corpus.
Pour renseigner cette cellule, saisissez simplement votre mot clé (sans étoile)
L’auteur de l’article
Le script, en raison des variations dans la structure des fichiers, n’extrait pas le nom des journalistes. En effet :
- Parfois, le nom est indiqué à la fin de l’article, directement dans le corps du texte.
- D’autres fois, il est encadré dans une balise spécifique.
- Et parfois, aucun nom de journaliste n’est mentionné…
Contrôle de votre fichier exporté
Je vous recommande d’adopter une méthode structurée (inspiré du process industriel) avant de peaufiner votre fichier. Il est important de vérifier le premier et le dernier article afin de vous assurer que tout le corpus a été correctement traité et exporté.
Ensuite, sélectionnez un article pour chaque source ou journal et vérifiez l’intégrité des articles.
Enfin, choisissez 2 ou 3 articles au hasard dans votre corpus pour compléter le contrôle.
[…] J’ai développé une interface en Python qui simplifie ce processus, permettant une gestion rapide et efficace des articles en double ou trop courts avant leur importation dans IRaMuTeQ. Il est important de noter que ce script est conçu pour être utilisé avec un corpus Europresse pré-traité pour IRaMuTeQ. Cela signifie que chaque première ligne de chaque article doit être composée de variables étoilées. Le script utilise les « **** » de chaque première ligne pour identifier l’article et scanner le texte à partir de la seconde ligne. Le pré-traitement de votre fichier au format IRaMuTeQ est donc un prérequis pour que le script fonctionne correctement. Ce prétraitement peut être réalisé manuellement ou à l’aide de ce script (article 1 – article 2– l’application en ligne – v3). […]
[…] MAJ du 31/12/2024 – Application en ligne Europresse to IRaMuTeQ […]
[…] script commence par importer un corpus textuel formaté selon les exigences d’IRaMuTEQ, puis le découpe en segments. Ici : l’argument : split_segments() divise chaque document en […]
[…] script ci-dessous a été conçu avec un corpus test, issu d’articles récupérés via Europresse et formaté pour être compatible avec le logiciel IRaMuTEQ. Par conséquent, il inclut une série de prétraitements spécifiques, […]
[…] Comme d’habitude dans mes scripts, je commence par un fichier texte encodé au format IRAMUTEQ. Ce format, largement utilisé pour l’analyse de données textuelles, permet une inter-perméabilité des données. Pour tester cette approche, vous pouvez utiliser mon interface Streamlit, qui offre la possibilité de formater un export Europresse au form… […]
[…] corpus doit être enregistré au format .txt et structuré selon les exigences d’IRaMuTEQ, avec en première ligne de chaque article une ligne étoilées (****) pour séparer les […]
[…] MAJ – 01-01-2025 – Europresse to IRaMuTEQ – Application en ligne (No code!) avec S… […]
[…] texte contenant, en tête, des lignes de variables étoilées, comme ceux prévus pour IRaMuTeQ. Le corpus html provenant du site Europresse a été préalablement traité à l’aide de ce script,…, pour le transformer au format texte. Il faut simplement réactiver le serveur (ce qui prend […]