
Les émotion “universelles” de Paul Ekman
Paul Ekman a défini six émotions dites “universelles” : la joie, la tristesse, la colère, la peur, la surprise et le dégoût.
Chacune de ces émotions peut être associée à une gamme d’émotions synonymes ou proches, qui reflètent des nuances contextuelles ou culturelles.
Pour la joie, des émotions comme le bonheur, la satisfaction, l’euphorie, la plénitude, la sérénité en sont des expressions ou variantes.
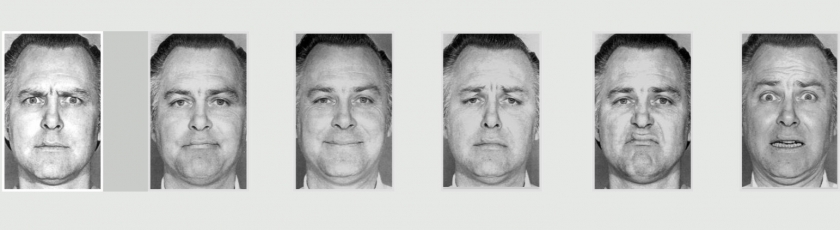
La tristesse inclut des nuances telles que la mélancolie, le désespoir, la déception, le chagrin, la lamentation, la peine…
La colère s’étend à des émotions comme la frustration, l’irritation, l’exaspération, l’indignation, la fureur, le mécontentement…
En ce qui concerne la peur, elle englobe des états émotionnels tels que l’anxiété, la terreur, l’inquiétude, l’effroi, l’angoisse, la crainte, la panique et l’horreur…
La surprise, peut se décliner en stupeur, étonnement, sidération, émerveillement…
Enfin, le dégoût regroupe des émotions proches comme la répulsion, l’aversion, le rejet, l’antipathie...
Mais ce sont ici des extrapolations… et les principaux modèles de Deep Learning qui analysent les émotions (que ce soit dans le cadre de l’image ou de l’audio) sont construits et entraînés à partir d’un jeu de données labellisé/étiqueté avec des catégories d’émotions provenant du modèle d’Ekman.
Cette catégorisation des données (les 6 émotions de Paul Ekman), qui sert souvent de base pour apprendre à “coder” et “entraîner” les modèles d’IA, n’a qu’un intérêt limité pour la recherche en Sciences Humaines et Sociales, car elle repose sur des émotions qui néglige leur contextualisation et leur construction sociale.

On pourra toutefois citer plusieurs datasets de qualité reposant sur l’entraînement de la reconnaissance des émotions à partir des catégories de Paul Ekman (FER2013 – DeepFace, RAVDESS, IOMECAP…).
Toutefois, les émotions universelles d’Ekman ont été critiquées pour leur simplification des dynamiques émotionnelles humaines et ne sont pas les plus appropriées à des contextes tels que les discours politiques, qui mobilisent des émotions complexes et parfois stratégiquement construites. De plus, les modèles SER pré-entraînés sur des bases de données (ex. : IEMOCAP, RAVDESS) s’appuient sur des scénarios artificiels (des acteurs lisant des phrases), souvent éloignés des interactions réelles, bien qu’ils s’appuient sur une méthodologie précise, incluant par exemple une répartition homme/femme.
Ces données ne tiennent pas complètement compte de la richesse des registres émotionnels utilisés dans des discours tels que ceux des discours politiques.
Apports de la typologie de Marion Ballet

Réflexion “épistémologique”
Les datasets fondés sur les émotions universelles de Paul Ekman constituent un point de départ utile pour tester les modèles de deep learning. Toutefois, il est essentiel d’adapter cette approche au contexte spécifique de la recherche. Dans le cadre d’une approche multimodale en Sciences Humaines et Sociales (SHS), visant à synchroniser l’image, le texte et l’audio pour explorer comment ces différentes couches contribuent à une analyse fine, les modèles d’IA basés sur la reconnaissance des émotions offrent des possibilités intéressantes
Cependant, bien que cette approche systématique facilite l’automatisation et la standardisation de l’analyse, elle risque également de réduire la richesse interprétative en imposant des catégories émotionnelles préexistantes et souvent trop génériques. Cela constitue en quelque sorte une forme de régression dans l’analyse, où le chercheur devient dépendant de la machine, elle-même entraînée sur des données peu adaptées à ses hypothèses.
La synchronisation de ces trois couches – image, texte et audio – pourrait être plus pertinente si elle n’était pas contrainte par la catégorisation d’Ekman dans le cadre de la reconnaissance des émotions. Une solution serait de construire un jeu de données spécifiquement adapté à la prédiction des émotions dans un contexte donné. Bien que cette option soit envisageable, elle présente l’inconvénient d’être un processus long et laborieux.
Une autre approche, complémentaire, consisterait à extraire uniquement les données brutes et multidimensionnelles, laissant au chercheur la possibilité d’interpréter les résultats et d’identifier les dynamiques émotionnelles complexes qui échappent souvent aux cadres prédéfinis.
Cette démarche permettrait de replacer le scientifique au centre de l’analyse et de privilégier une exploration contextuelle et nuancée.
Par analogie, une telle méthodologie pourrait s’inspirer des travaux de Gregory Bateson. À travers sa méthode d’observation participante et l’utilisation de la (chrono)photographie, Bateson a révélé le concept de “double bind” en privilégiant une approche contextuelle et holistique.
De la même manière, en permettant une observation fine des données sans imposer des catégories rigides, il devient possible d’ouvrir de nouvelles perspectives dans l’analyse des émotions, en capturant leur complexité et leur variabilité contextuelle.

Ainsi, en combinant la puissance des outils d’intelligence artificielle pour collecter, traiter et synchroniser des données ET avec l’intuition et la réflexion critique du scientifique, il devient possible de dépasser les limitations inhérentes aux systèmes standardisés.
[…] des analyses comme la détection des émotions faciales, (cf. article 1 – article 2 – article 3). Bon, c’est un petit retour en arrière, mais j’avais besoin d’un script qui se […]
[…] une voie vers une lecture plus fine de ces « entre-deux » cognitifs. Toutefois, le recours à des modèles d’émotions fondés sur des catégories dites « universelles » (Paul Ekmann) pose l…, notamment face à la complexité des contextes socio-discursifs […]
[…] J’ai appliqué la méthode à l’interview de Marine Le Pen diffusée sur TF1 (YouTube – 31/03/2025), réalisée dans la foulée de sa condamnation pour inéligibilité. L’intérêt réside dans la mise en regard des résultats de l’analyse audio et du fil réel de l’entretien, rendue possible par la précision des timsestamps. Cette synchronisation (multimodale), permet de croiser amplitude, pauses, débit,…, avec la vi…. […]
[…] de détection des émotions. Plutôt que de s’appuyer sur les émotions « universelles » de Paul Ekman, souvent peu discriminantes et fréquemment classées comme « neutres » par les modèles, on […]