Cet article vise à « reproduire » la démarche statistique (simplifiée) expliquée par Julien Barnier autour de la CHD. Je reprends donc l’exemple et la démarche lors de son excellente intervention sur l’excellente chaîne YouTube Tuto Mate-SHS.
L’objectif est de (re)construire un script R (sans utiliser le package « rainette ») qui, à partir des 5 phrases de l’exemple de Julien Barnier, permette de comprendre le « comment » et le « pourquoi » de la répartition des documents et des termes en deux classes.
L’article a donc une « vertu pédagogique » et, si vous lancez une CHD à partir du package rainette de Julien Barnier ou bien depuis IRaMuTeQ développé par Pierre Ratinaud, vous vous épargnerez les calculs, bien entendu !
Le principe de la CHD est de diviser le corpus en 2 classes, c’est pour cela qu’on parle de classification hiérarchique DESCENDANTE. Ensuite, l’algorithme continue sa classification en l’appliquant toujours à la classe la plus grande, pour poursuivre la division du corpus, et cela jusqu’à obtenir le nombre de classes défini par l’utilisateur.
À ce sujet, il n’y a pas de règle particulière ; c’est un travail par itération, « tâtonnement expérimental » qui demande au chercheur de vérifier si le découpage du corpus et les classes qui en découlent font sens.
Note : Le principe statistique du χ² dans la méthode Reinert repose sur la mesure de la « distance » entre deux groupes combinant plusieurs documents (segments de textes) en fonction de la distribution de leurs termes. Plus précisément, la méthode Reinert propose de scinder un corpus en deux classes en calculant la matrice termes-documents-regroupée.
Ainsi dans la méthode Reinert, on utilise la formule du test du χ², mais pas pour faire un test statistique au sens strict.
Ici, le χ² sert surtout à mesurer à quel point deux groupes de documents sont différents dans la façon dont les mots y sont répartis. Plus la valeur est grande, plus les groupes sont distincts. On ne cherche pas à savoir si la différence est « significative » statistiquement, mais simplement à trouver le meilleur découpage possible du corpus. C’est donc un outil pour aider à classer les documents, même quand on a très peu de données ou des fréquences faibles.
Cette valeur du χ² indique donc le degré de différence entre les distributions de termes dans les deux groupes.
Le script R qui va décrire les étapes est sur Ghitub
Étape 1 : Nettoyage du corpus
Dans notre exemple, chaque phrase représente un document. Cela pourrait être des commentaires YouTube, des tweets…
Les phrases dans cet exemple sont relativement courtes et ont des sens assez divergents. La première étape consiste à réaliser un nettoyage « classique » des documents : suppression des stopwords, mise en minuscules, etc…

Étape 2 : Construction de la matrice termes-documents
Cette matrice recense la fréquence d’apparition de chaque terme dans chaque document (dans notre exemple, 5 documents).
À ce stade, aucun test statistique n’est encore effectué : il s’agit uniquement d’observer la répartition des termes selon leur fréquence au sein des documents.

Étape 3 : la matrice termes-documents-regroupée
La CHD vise à répartir l’ensemble des documents en deux groupes/classes. Il faut donc au préalable calculer toutes les combinaisons possibles d’affectation des documents au groupe 1 (classe 1) et au groupe 2 (classe 2).
Matrice termes-documents-regroupée : matrice obtenue en faisant la somme de chaque matrice termes-documents, pour chacun des deux groupes de documents. Elle résume ainsi la fréquence des termes dans chaque groupe.
Exemple : Dans le groupe/classe 1, nous pouvons avoir les documents : doc 1 + doc 2 + doc 3, et dans le groupe/classe 2, les documents : doc 4 + doc 5.
Avec 5 documents, le nombre total de combinaisons possibles s’élève à 15.
Vous imaginez la complexité d’une telle tâche avec un grand corpus composé de segments de texte (documents) délimités par la ponctuation.

Dans notre exemple de 5 docs/phrases Il y a donc 15 (ré)partitions possibles en 2 groupes/classes distincts.

Ainsi pour chaque regroupement de document on va réaliser un test de χ² servant de mesure de distance entre les groupe.

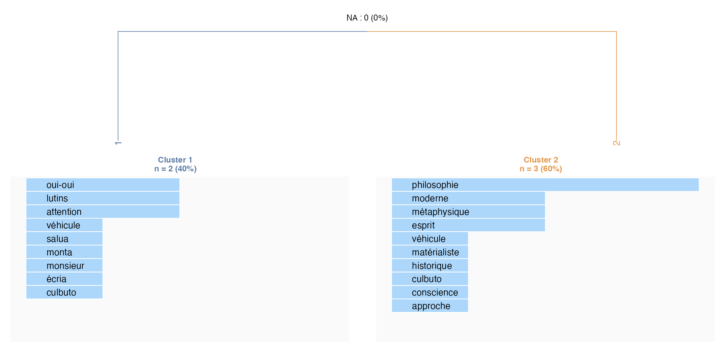
Illustration de la « meilleure » (χ² = 23,9) matrice des termes-documents-regroupée.


Utilisation du package rainette
Testons maintenant la même opération, mais cette fois en utilisant le package rainette sur le même corpus.
Voici le script R qui utilise le package Rainette avec le même corpus.
# Chargement des extensions
library(tidyverse)
library(quanteda)
library(rainette)
# Création du corpus avec 5 phrases
corpus_raw <- c(
"La philosophie de l'esprit est une approche moderne de la métaphysique.",
"Dans la philosophie moderne, l'esprit n'est plus le véhicule de la conscience.",
"Oui-oui salua les lutins et monta dans son véhicule.",
"« Attention aux lutins, Oui-oui, attention ! » s'écria Monsieur Culbuto.",
"Il y a un culbuto historique entre philosophie métaphysique et philosophie matérialiste."
)
corp <- corpus(corpus_raw)
# Tokenisation : suppression de la ponctuation, passage en minuscules, découpage sur l'apostrophe (ASCII ou typographique)
tok <- tokens(corp, remove_punct = TRUE) %>%
tokens_tolower() %>%
tokens_split("'")
# Suppression des stopwords en français et des termes additionnels "plus", "a", "entre"
stop_fr <- c(stopwords("fr"), "plus", "a", "entre")
tok_clean <- tokens_remove(tok, stop_fr)
# Création de la matrice document-termes (DTM)
dtm <- dfm(tok_clean)
# Classification en 2 classes avec rainette
res <- rainette(dtm, k = 2, min_segment_size = 1)
# Exploration et affichage des résultats
rainette_explor(res, dtm, corp)
rainette_plot(res, dtm, k = 2)
Et là… miracle !… on retrouve bien entendu la même répartitions.
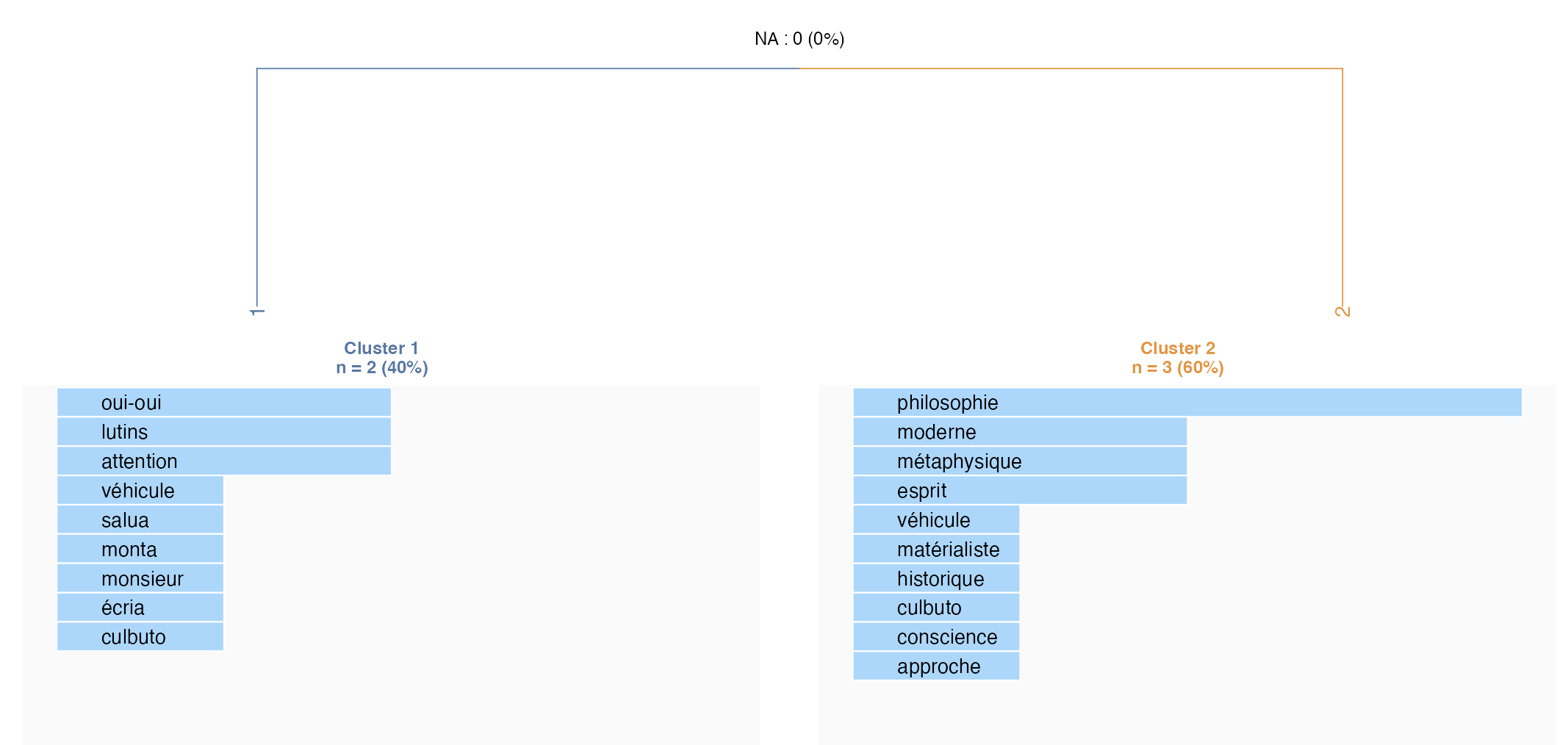
On retrouve une classification « logique » et identique à notre script, avec les segments de texte (documents) répartis ainsi :
La classe 1

La classe 2

Conclusion
Ce tutoriel avait pour objectif de mieux comprendre le principe de la CHD et le rôle joué par la statistique du χ² dans le processus de classification.
À travers un exemple simple, nous avons vu comment les documents peuvent être regroupés en deux classes en fonction de la distribution des mots, et comment le χ² permet de mesurer la différence entre ces groupes.
Bien que le package rainette automatise ces calculs, il reste important de comprendre ce qu’il se passe « sous le capot » !
Cependant, calculer le χ² pour tous les regroupements possibles devient rapidement impossible en raison d’une explosion combinatoire du nombre de possibilités.
Pour résoudre cette difficulté, Max Reinert propose une méthode plus élaborée, consistant à ordonner les documents selon leur position sur le premier axe d’une analyse des correspondances.