
Rainette est un paquet R développé par Julien Barnier pour effectuer des analyses textuelles, à l’aide d’une Classification Hiérarchique Descendante (CHD). Dans cet article, nous détaillons un script qui permet d’exporter en fichier texte, html, csv les résultats de la CHD. Voici les fonctionnalités principales du script :
- Réalisation de la CHD (cf. article)
- Extraction de statistiques détaillées (chi2 (filtrés par p-value)…)
- Export de segments de texte par classe au format texte
- Création d’un concordancier au format HTML
- Visualisation via nuages de mots et graphes de cooccurrences
- Affichage des résultats dans l’interface graphique “Rainette Explor”
Étant donné que le script est assez long, le code source complet est accessible via Github.

Installation et chargement des bibliothèques
Avant de commencer, il est nécessaire d’installer et de charger les bibliothèques suivantes :
install.packages(c("rainette", "quanteda", "wordcloud", "RColorBrewer", "igraph", "dplyr", "shiny", "htmltools"))
library(rainette)
library(quanteda)
library(wordcloud)
library(RColorBrewer)
library(igraph)
library(dplyr)
library(htmltools)
Préparation du corpus et découpage en segments de textes
Le script commence par importer un corpus textuel formaté selon les exigences d’IRaMuTEQ, puis le découpe en segments.
Ici : l’argument : split_segments() divise chaque document en segments de 40 mots (la ponctuation est prise en compte).
chemin_fichier <- "chemin/vers/votre/fichier/corpus/au/format/texte.txt" corpus <- import_corpus_iramuteq(chemin_fichier) segment_size <- 40 corpus <- split_segments(corpus, segment_size = segment_size)
La taille du segment (nombre de termes/mots) est un paramètre à définir.
Prétraitement et création de la matrice document-termes (DFM)
La fonction dfm_trim permet de réduire la taille du DFM en supprimant les termes peu fréquents ou trop fréquents. En d’autres termes, elle filtre les termes selon des critères min_docfreq = ()
tok <- tokens(corpus, remove_punct = TRUE, remove_numbers = TRUE)
tok <- tokens_split(tok, "'")
tok <- tokens_remove(tok, stopwords("fr"))
tok <- tokens_tolower(tok)
dfm <- dfm(tok)
dfm <- dfm_trim(dfm, min_docfreq = 5)
cat("Dimensions du DFM après trim :", dim(dfm), "\n")
min_docfreq = 5 signifie qu’un terme doit apparaître dans au moins 5 documents pour être conservé dans la matrice.
Cette valeur doit être ajustée selon vos objectifs.
Classification hiérarchique descendante (CHD)
k = 8 : Nombre maximum de classes (valeur à ajuster)
Ce paramètre spécifie le nombre maximum de classes ou groupes thématiques que Rainette va produire à l’issue de la Classification Hiérarchique Descendante (CHD).
Rainette procède par divisions successives pour regrouper les segments textuels en classes. Le paramètre k fixe une limite supérieure au nombre de classes qui seront créées.
res <- rainette(dfm, k = 8, min_segment_size = 10, min_split_members = 10) docvars(corpus)$Classes <- res$group
min_segment_size = 10 : Taille minimale d’un segment pour la classification
Ce paramètre indique la taille minimale (en nombre de termes) qu’un segment doit avoir pour être analysé dans la classification. Si un segment est plus petit que cette taille, il sera automatiquement regroupé avec un autre segment.

Vous devez donc ajuster cette valeur selon votre corpus.
L’argument min_split_members spécifie le nombre minimal de segments qu’une classe doit contenir pour qu’elle puisse être divisée en sous-classes. En d’autres termes, il fixe un seuil minimal pour empêcher l’algorithme de tenter de diviser des groupes (ou classes) contenant moins de segments que cette valeur. La valeur de cet argument est à ajuster.
Extraction des statistiques par classe
Le script calcule des mesures statistiques comme le chi2 et filtre les termes significatifs selon une p-value (≤ 0.05). Ces résultats sont exportés au format CSV.
res_stats_list <- rainette_stats(
dtm = dfm,
groups = docvars(corpus)$Classes,
measure = c("chi2", "lr", "frequency", "docprop"),
max_p = 0.05
)
res_stats_df <- bind_rows(res_stats_list, .id = "ClusterID")
write.csv(res_stats_df, "stats_par_classe.csv", row.names = FALSE)
Dans le tableau renvoyé par rainette_stats, chaque colonne a une signification :
- classe : numéro de la classe
- chi2 : valeur du chi2
- p : la p-value associée à la statistique du chi2
- n_target : le nombre d’occurrences du terme dans la classe en question
- n_reference : le nombre d’occurrences du même terme dans le reste du corpus (hors groupe cible)
- sign : indique si le terme est positivement ou négativement associé à la classe (le plus souvent
"positive"si le terme est surreprésenté,"negative"s’il est sous-représenté) - p_value_filter : p ≤ 0.05 – Dans le fichier csv, seuls les termes ayant une p-value ≤ 0.05 sont présents

L’argument show_negative dans le contexte de Rainette (et de la fonction rainette_stats) détermine si les termes avec une “keyness” négative doivent être inclus dans les résultats.

Si un terme a une keyness positive, cela signifie qu’il est sur-représenté dans la classe par rapport aux autres classes du corpus. En d’autres termes, ce terme est “typique” ou “distinctif” pour cette classe. Une keyness négative signifie qu’il est sous-représenté dans la classe par rapport aux autres classes.
Ces informations peuvent être utiles pour comprendre ce qui distingue une classe des autres (l’absence d’un certain vocabulaire).
Génération d’un concordancier interactif
Le concordancier est exporté au format HTML avec surlignage des termes significatifs propres à chaque classe, recontextualisés au sein des segments de texte correspondants. Cette approche permet de passer d’une analyse lexicale à une analyse sémantique, en restituant le contexte et le sens des termes caractéristiques qui structurent les classes grâce au concordancier.

Nuages de mots
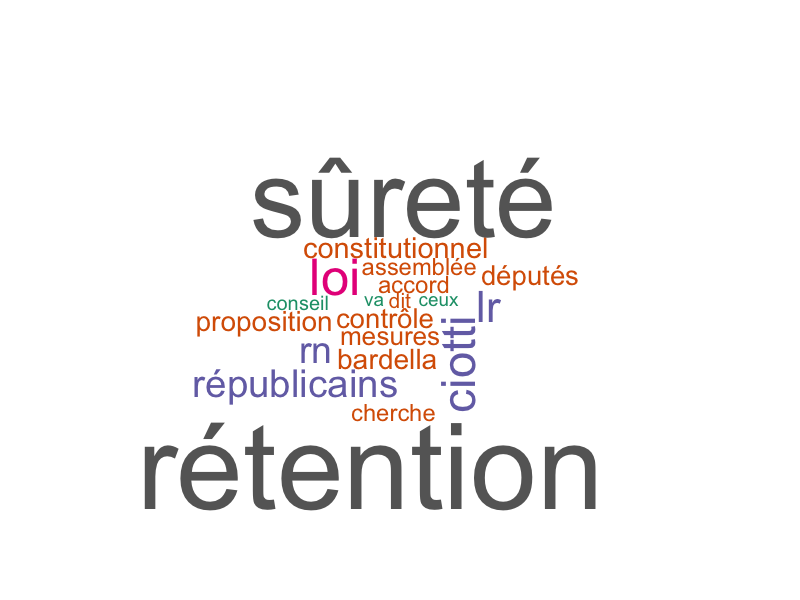 Les nuages de mots sont générés pour chaque classe à partir des termes significatifs.
Les nuages de mots sont générés pour chaque classe à partir des termes significatifs.
Graphes de cooccurrences
Les graphes de cooccurrences représentent les relations entre les termes qui apparaissent fréquemment ensemble dans le texte. Ces relations sont basées sur une “fenêtre contextuelle”. Les cooccurrences sont donc calculées par classe (un graphe par classe).
La cooccurrence est calculée sur une fenêtre glissante définie par le paramètre window dans la fonction fcm de quanteda. Dans ton script, la fenêtre est fixée à 5 termes (paramètre window = 5), cette fenêtre représente le nombre de mots pris en compte autour d’un mot donné. Par exemple, si la fenêtre est de 5, chaque mot est mis en relation avec les 5 mots qui le précèdent et les 5 mots qui le suivent dans le texte.
Cette section du script devra être améliorée.
Affichage de la CHD avec rainette_explor
Rien de nouveau à ce niveau en fin de script, on lance rainette_explor(res, dfm, filtered_corpus) pour afficher la CHD dans le terminal et dans le navigateur. Ici vous retrouverez le script de base pour uniquement afficher ce graphe.

Perspective : AFC
Le projet suivant intégrera l’Analyse Factorielle des Correspondances (AFC) pour représenter graphiquement les relations entre les classes et leurs termes caractéristiques, explorer les proximités lexicales entre les classes et identifier les axes principaux structurant les données textuelles.