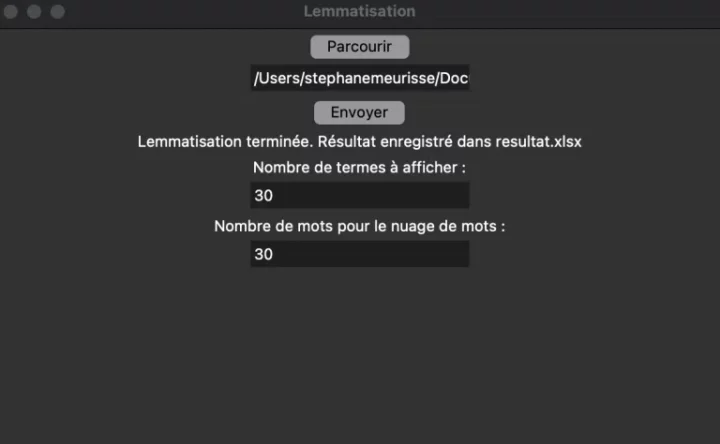
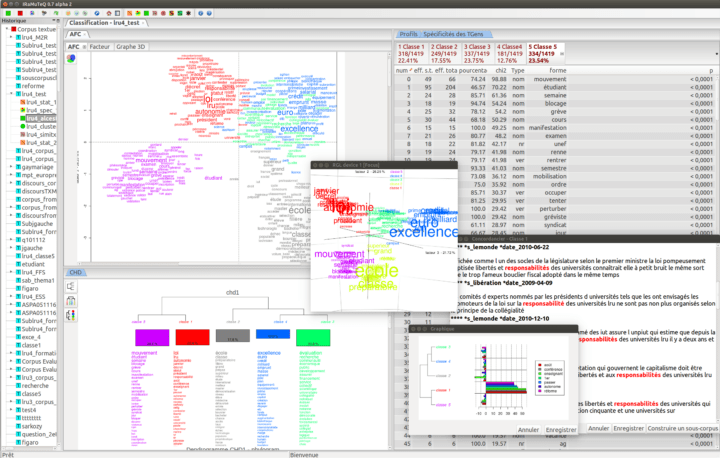
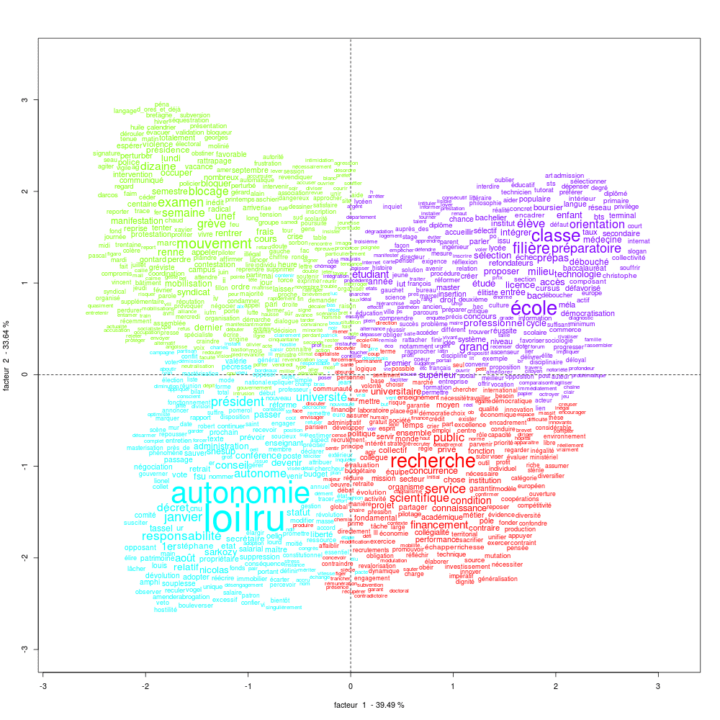
Voici la partie 2, consacrée à l’application du test TF × IDF suite à l’extraction d’environ 1725 messages depuis YouTube et au prétraitement du corpus. L’analyse des commentaires YouTube est judicieuse puisque chaque commentaire est considéré comme un document distinct. Cependant, le langage employé dans ces commentaires ne facilite pas toujours le prétraitement des...