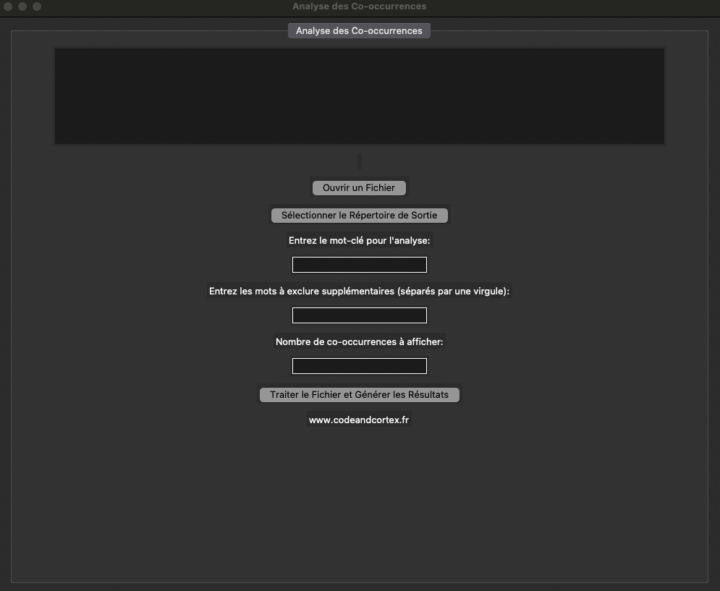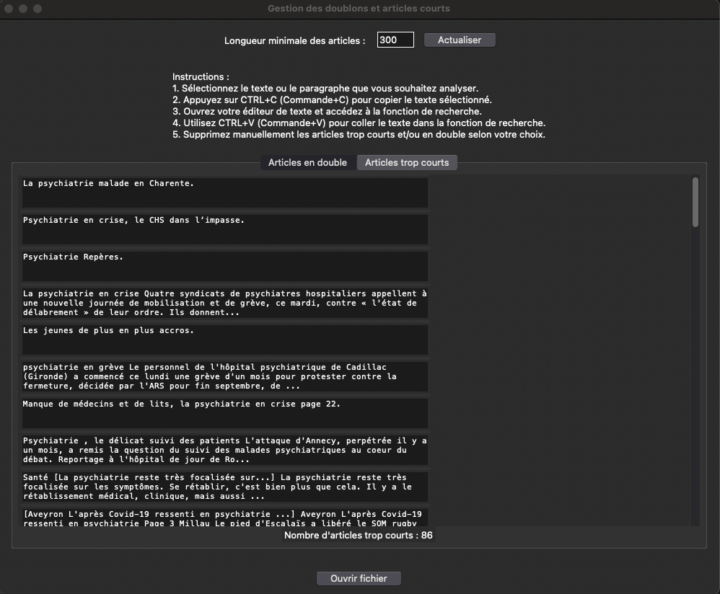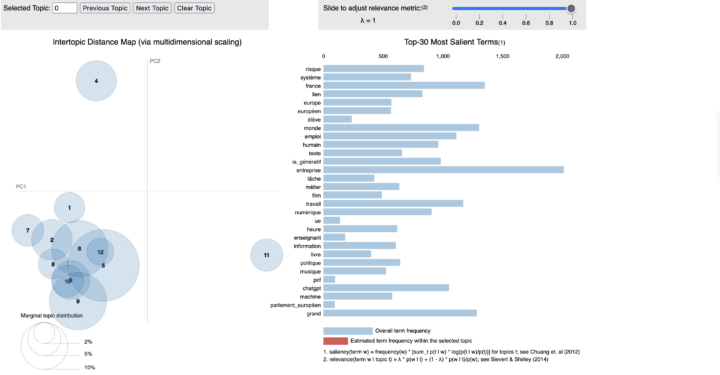
Mon projet « Analyse Textuelle Avancée (ATA) », est maintenant disponible sur GitHub. ATA est une interface conçue pour répondre aux besoins des chercheurs en Sciences Humaines et Sociales et des data scientists, qui travaillent sur des projets d’analyse textuelle. Sans avoir de connaissances en programmation, l’interface vous permet d’exploiter à la fois des...