
Lorsqu’on parle des LLM (Large Language Models) comme BERT, on pense souvent à leur utilisation dans des chatbots ou des systèmes d’IA conversationnelle. L’objectif classique est alors d’entraîner ces modèles à générer des réponses optimales en ajustant les probabilités de succession des mots pour maximiser la cohérence des phrases.
Ici, nous exploitons un “Large Language Model (LLM)” non pas dans une logique de génération de texte comme on le ferait avec ChatGPT, mais pour mener une analyse textuelle, en s’appuyant sur un test de similarité cosinus. Cette approche avait déjà été explorée dans un article précédent avec la librairie SpaCy, mais les résultats obtenus étaient insatisfaisants.
Le script de l’article complet ICI
Avec SpaCy, la projection vectorielle des mots donnait un résultat très technique, où les relations entre les termes semblaient rigides et peu nuancées. Le réseau de mots généré se composait de nœuds et d’arêtes dont les connexions paraissaient dénuées de subtilité sémantique. En d’autres termes, SpaCy identifie des relations entre les mots, mais peine à en révéler les nuances contextuelles et les (éventuelles) ambiguïtés.
Dans cette étude, nous analysons le même corpus, qui traite de “l’injonction thérapeutique pour des personnes radicalisées” (Je résume…). Lors de la lecture, on perçoit immédiatement une ambiguïté lexicale forte autour des termes comme “État”, “soins”, “psychiatrie”, “attentat”, “radicalisation”, “injonction”… Ce corpus est particulièrement intéressant car il met en lumière ce que Michel Foucault décrivait dans son ouvrage “Le pouvoir psychiatrique” : à savoir que la psychiatrie, au-delà de son rôle dans le soin aux patients, (serait) aussi un outil de contrôle politique au service de l’État.
Lorsqu’on traite du traitement automatique du langage naturel (TALN = NLP), la manière dont les mots sont représentés joue un rôle fondamental. SpaCy et CamemBERT utilisent deux approches différentes pour projeter les mots dans un espace vectoriel.
Comment SpaCy traite-t-il le texte ?
SpaCy repose sur des “vecteurs statiques”. Cela signifie qu’un mot est toujours associé au même vecteur, peu importe le contexte. Par exemple, le mot avocat aura une représentation unique, qu’il désigne un fruit ou un métier.
SpaCy n’utilise pas de self-attention mais repose sur une analyse linguistique classique.
- Tokenisation : Découpage du texte en mots.
- POS-tagging : Assignation des catégories grammaticales (NOUN, VERB, ADJ… cf. la doc SpaCy).
- Lemmatisation : Réduction des mots à leur forme de base (“mange” = “manger”).
- Dépendances syntaxiques : Détection des relations entre mots (sujet, verbe, complément…).
Exemple d’analyse avec SpaCy avec la phrase : “L’avocat plaide au tribunal avant de manger un avocat.“
L' → l' (DET) → det avocat → avocat (NOUN) → nsubj plaide → plaider (VERB) → ROOT au → à (ADP) → case tribunal → tribunal (NOUN) → obj manger → manger (VERB) → advcl avocat → avocat (NOUN) → obj
Comprendre le mécanisme d’attention de BERT
BERT utilise un mécanisme d’auto-attention (Self-Attention) pour analyser tous les mots en même temps et établir leurs connexions.
On pourrait dire que chaque mot (token) “regarde” tous les autres mots de la phrase pour ajuster sa signification. Chaque connexion est pondérée : BERT attribue un score d’attention indiquant l’importance d’un mot pour un autre. Les mots sont ainsi représentés en fonction de leur contexte.
def encoder_textes(textes):
inputs = tokenizer(textes, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs, output_attentions=True) # Active l'output des scores d'attention
return outputs.attentions # Renvoie directement les scores d'attention
Ainsi, le mot avocat sera compris différemment selon qu’il apparaisse dans “je mange un avocat” ou “mon avocat plaide ma cause”.
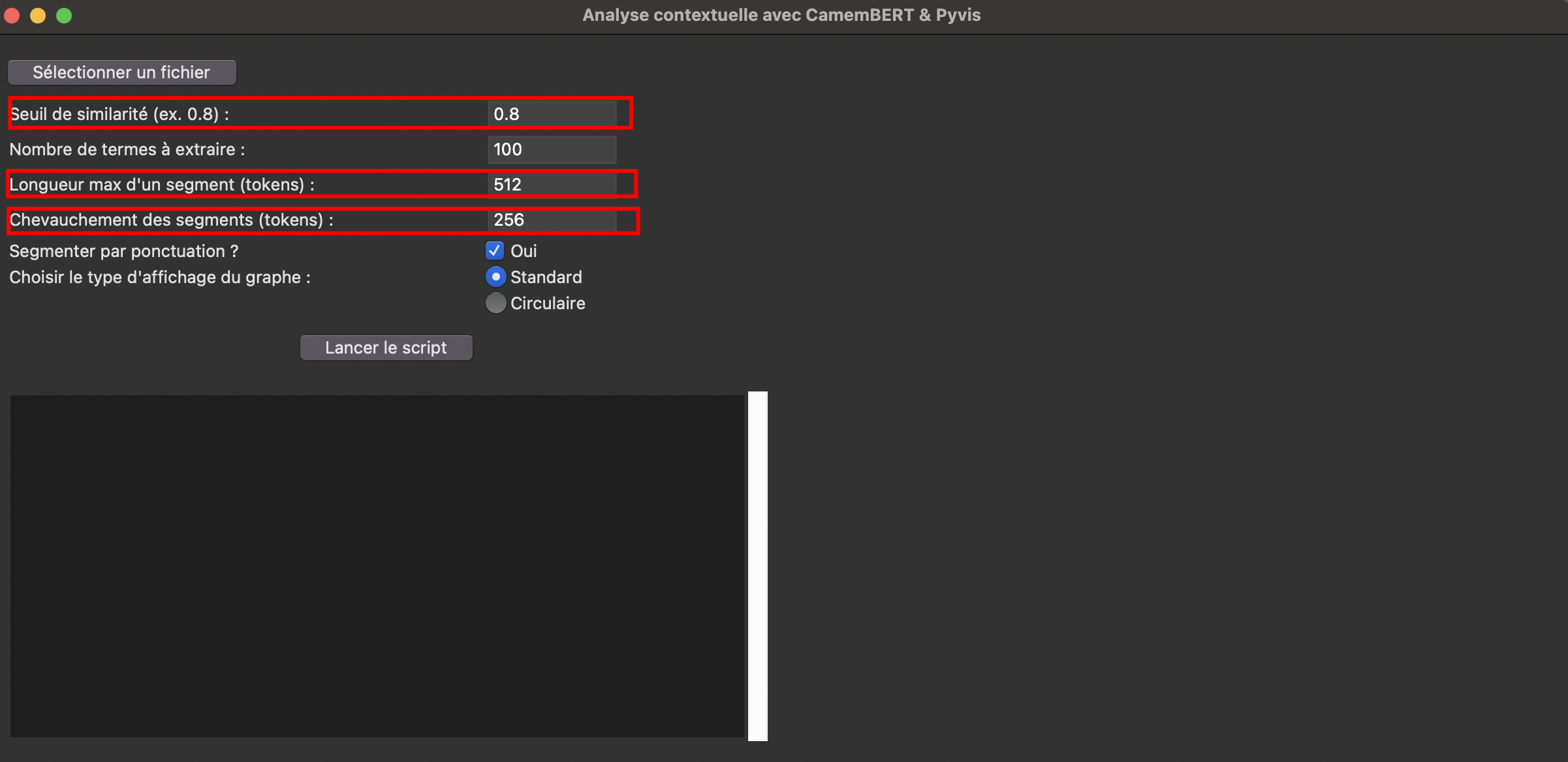
Fonctionnalités du script
Je ne vais pas rentrer dans la description du code python mais plutôt dans l’explication des principaux paramètres.
Sélectionner un fichier .txt
Comme d’habitude dans mes scripts, je commence par un fichier texte encodé au format IRAMUTEQ. Ce format, largement utilisé pour l’analyse de données textuelles, permet une inter-perméabilité des données. Pour tester cette approche, vous pouvez utiliser mon interface Streamlit, qui offre la possibilité de formater un export Europresse au format IRAMUTEQ.
Le dictionnaire de STOPWORDS pourra être enrichi directement dans le script.
Stopwords français (articles, pronoms, conjonctions, adverbes, et quelques mots inforatifs)
STOPWORDS = {
# Articles
"le", "la", "les", "l'", "un", "une", "des", "du", "de", "d'", "au", "aux", "ce", "cet", "cette", "ces",
# Pronoms personnels et relatifs
"je", "tu", "il", "elle", "on", "nous", "vous", "ils", "elles", "me", "moi", "te", "toi", "lui", "eux",
"se", "soi", "leur", "leurs", "y", "en", "qui", "que", "quoi", "dont", "où", "celui", "celle", "ceux", "celles", "ceci", "cela", "ça",
# Conjonctions
"et", "ou", "mais", "donc", "or", "ni", "car", "parce", "puisque", "lorsque", "quand", "si", "comme", "tandis", "alors", "ainsi", "bien", "soit", "afin", "quoique", "pour", "sans", "sauf", "malgré",
# Adverbes courants
"très", "trop", "peu", "beaucoup", "assez", "tellement", "moins", "plus", "aussi", "encore", "déjà",
"souvent", "toujours", "jamais", "parfois", "bientôt", "maintenant", "ici", "là", "ailleurs", "partout",
"dedans", "dehors", "environ", "vite", "lentement", "simplement", "exactement", "précisément", "heureusement",
# Mots informatifs supplémentaires
"même", "avec", "dans", "après", "deux", "sont", "être", "faut", "notre", "peut", "tout", "entre", "avoir", "avait",
"était", "faire", "fait", "depuis", "mois", "tous", "face", "aurait", "avons", "serait", "selon", "ayant"
}
Choix du seuil de similarité cosinus
La similarité cosinus est une mesure comprise entre 0 et 1. De plus, dans l’interface, vous pouvez définir le nombre de termes à extraire. Je vous recommande d’effectuer plusieurs tests, par exemple en retenant les 50 mots les plus fréquents et en appliquant un seuil de similarité élevé (0.9).
Cela permettra d’obtenir un graphique et une restitution des résultats à la fois épurés et lisible.
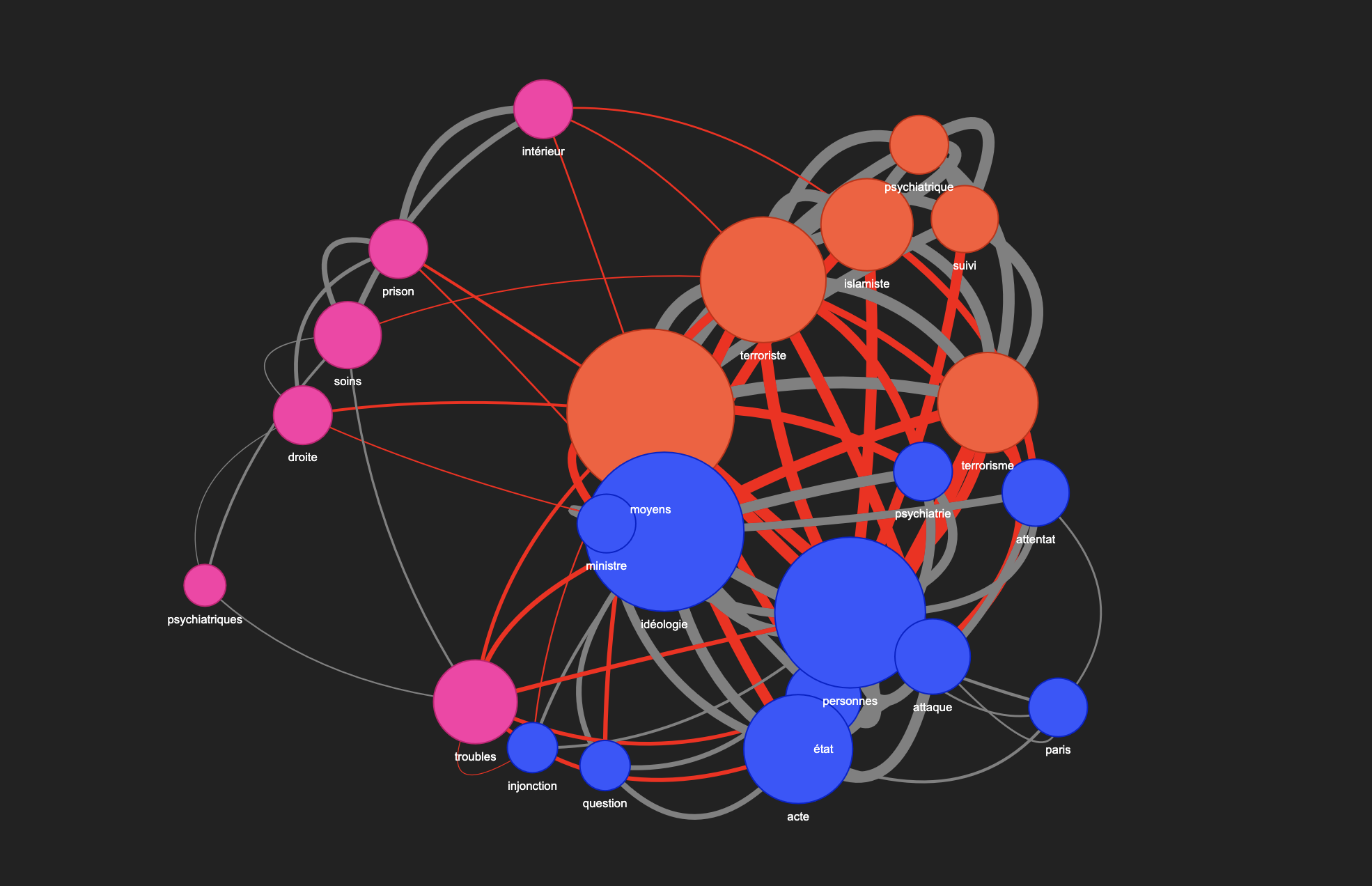
Construction du graphe de relations entre mots
Dans le graphe interactif, les arêtes grises représentent des connexions entre des nœuds appartenant à la même communauté, indiquant ainsi des liens internes cohérents au sein de la même communauté (groupe).
En revanche, les arêtes rouges signalent une connexion entre un nœud d’une communauté et un nœud d’une autre, mettant en lumière des liens inter-communautaires souvent plus rares et pertinents.
De plus, en cliquant sur une arête, l’utilisateur peut voir s’afficher le score de similarité cosinus, qui quantifie la force du lien entre les deux nœuds.
Cette distinction par couleur permet ainsi de visualiser rapidement la structure et les interactions sémantiques dans le corpus.
Visualisation du graphe – Mode standard
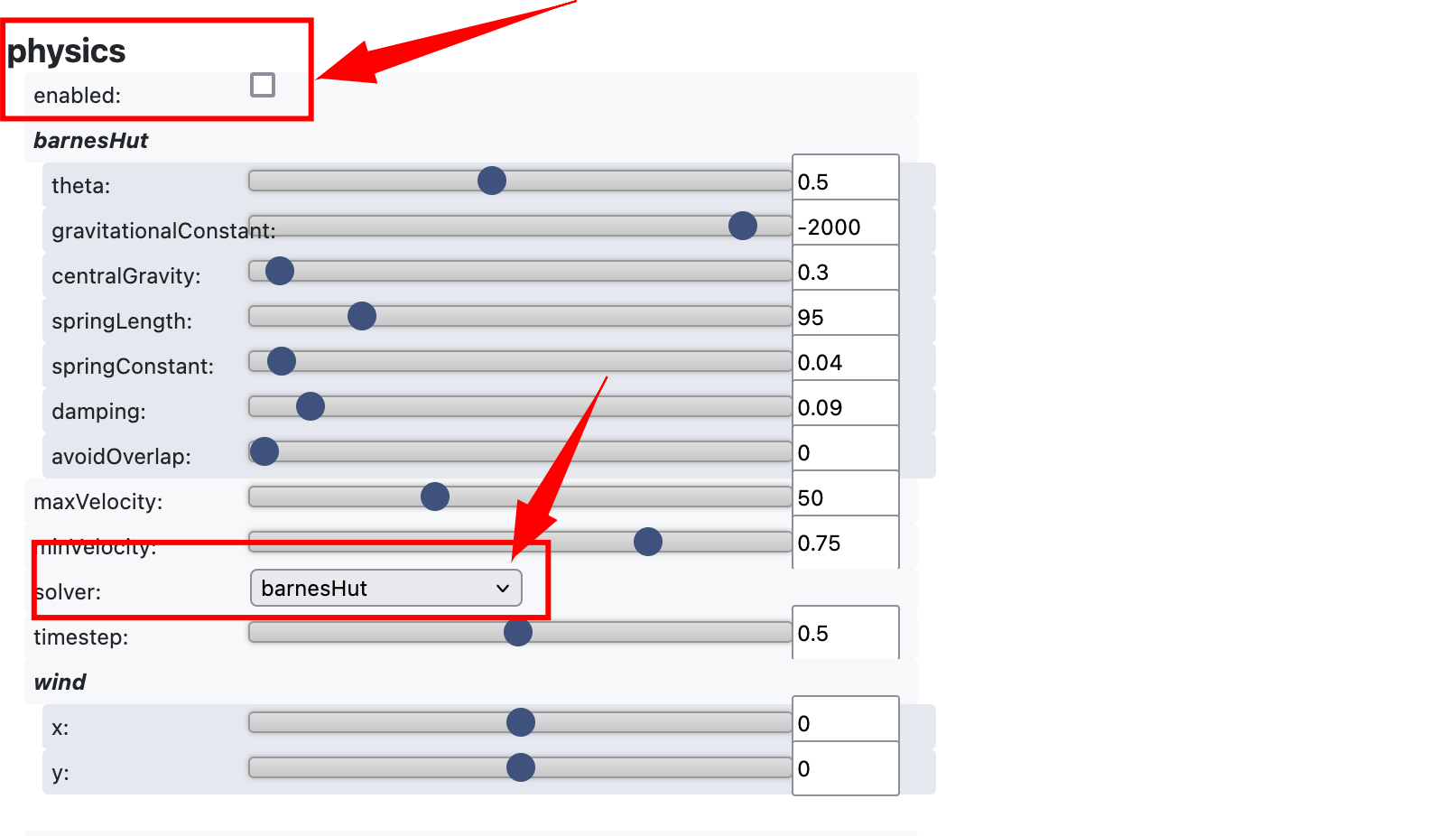
Vous pouvez activer ou désactiver la “physics” dans l’onglet (tout en bas du graphe, il faut scroller). L’option de désactivation de la physics permet de déplacer les nœuds avec la souris sans qu’ils ne reviennent automatiquement au centre. C’est un outil qui améliore la lisibilité, notamment si vous avez choisi de conserver un graphe dense.
Visualisation du graphe – Mode circulaire
Le mode circulaire est particulièrement intéressant pour les graphes peu denses, car il permet de mieux visualiser les relations entre les nœuds appartenant à différentes communautés.

Conclusion
Mon script n’est pas encore totalement satisfaisant.
Si BERT offre une approche plus puissante que SpaCy grâce à sa “tokenisation contextuelle”, sa mise en œuvre reste plus complexe. Par exemple, mon script ne prend en compte que les tokens de moins de 4 caractères, ce qui exclut des termes significatifs comme “RN” pour “Rassemblement National”.
Ce type de limite montre qu’il reste encore des ajustements à faire pour affiner l’analyse et mieux capturer les subtilités des relations lexicales et conceptuelles dans un tel corpus.