Dans cet article, nous allons explorer l’utilisation de l’algorithme K-Means pour effectuer des clusters à partir d’analyses textuelles.
Une fois vos données préparées, vous pourrez tester l’algorithme et interpréter les résultats à l’aide de diverses visualisations.
K-Means est un algorithme de clustering non supervisé largement utilisé pour partitionner un ensemble de données en groupes distincts. C’est l’une des méthodes les plus simples pour réaliser du clustering, bien que d’autres approches non supervisées, comme BERTopic combiné avec HDBSCAN, offrent également des alternatives (plus) performantes.
L’objectif principal de K-Means est de minimiser la variance intra-cluster (les distances entre les points de données et leur centroïde respectif) tout en maximisant la distance inter-cluster (les distances entre différents centroïdes).
Voici une vidéo en français qui explique de manière claire et détaillée les étapes du test K-means.
K-Means et la transformation des données textuelles
Les données textuelles sont généralement considérées comme des données non structurées comme des documents, des articles, des phrases ou paragraphes, et des segments de texte plus courts, ainsi que des mots.
Pour appliquer K-Means à des données textuelles, il est essentiel de convertir ces données en vecteurs numériques.
Les sentence embeddings (Embeddings de phrases de notre corpus d’articles de presse) , comme ceux fournis par les modèles BERT, Camembert, all-MiniLM-L6-v2, transforment des phrases ou des documents entiers en vecteurs.
Ces modèles capturent le contexte de manière approfondie, rendant les analyses de texte plus riches et pertinentes.
from sentence_transformers import SentenceTransformer
# Initialiser SentenceTransformer pour créer des embeddings
sentence_model = SentenceTransformer("all-MiniLM-L6-v2")
# Générer les embeddings pour chaque article
embeddings = sentence_model.encode(df['content'].tolist())
Dans le script, la bibliothèque utilisée « SentenceTransformer », est spécialement conçue pour travailler avec des « Sentence Embeddings ». Ce choix est essentiel car il permet de traiter des unités de texte plus larges que les simples mots. En ce qui concerne le modèle, nous utiliserons dans ce script « all-MiniLM-L6-v2 ».
Ce modèle très rapide n’est pas le plus optimal contrairement à « Camembert (INRIA) » qui est spécialisé dans la langue française.
Mais ce modèle à la particularité d’être très rapide. J’ai réalisé des tests avec le modèle Camembert sur le même corpus de 1 026 articles issus du site Europresse avec mon Mac M2. La puissance de calcul nécessaire pour utiliser Camembert est à prendre en considération.
Avec Camembert, l’analyse prend plusieurs minutes et le Mac montre des signes de difficulté… (température).
L’évolution du script permettra à l’utilisateur de choisir entre les deux modèles, mais pour le moment, restons simples avec all-MiniLM-L6-v2, qui est multilingue.
Lors du processus d’encodage, chaque article est considéré comme une unité distincte, confirmant ainsi que les embeddings créés sont basés sur les phrases ou les documents entiers plutôt que sur des mots individuels.
Cette approche est avantageuse pour les analyses textuelles où le contexte global des phrases doit être pris en compte.
Les bibliothèques utilisées pour le script
Pour utiliser le script d’analyse textuelle avec K-Means, vous devez installer plusieurs bibliothèques Python.
- Tout d’abord, Streamlit est essentiel pour créer l’application web interactive, tandis que Pandas est utilisé pour la manipulation et l’analyse des données.
- Scikit-learn est nécessaire pour l’implémentation de l’algorithme de clustering K-Means et pour le calcul des similarités entre clusters.
- SentenceTransformers est utilisé pour générer des embeddings de phrases, facilitant ainsi le clustering des documents textuels.
- Matplotlib et Seaborn sont indispensables pour la création de graphiques et la visualisation des résultats. Pour générer des nuages de mots, vous aurez besoin de WordCloud.
Requests est utilisé pour récupérer le contenu textuel depuis des URL(option non développé dans ce script). Initialement, j’avais prévu d’importer les données directement depuis une URL, mais ce projet s’est avéré un peu ambitieux ! Pour l’instant, cette fonctionnalité n’est pas encore développée.- NLTK est utilisé pour le traitement du langage naturel, notamment pour gérer les stop words en français.
- UMAP est nécessaire pour réduire la dimensionnalité des données et visualiser les clusters en 2D ou 3D.
- Enfin, Plotly est utilisé pour créer des visualisations interactives, et Kaleido permet d’exporter ces visualisations sous forme de fichiers image.
Vous pouvez installer ces bibliothèques en utilisant la commande suivante :
pip install streamlit pandas scikit-learn sentence-transformers matplotlib seaborn wordcloud requests nltk umap-learn plotly kaleido
Comprendre l’algorithme K-Means
K-Means est une méthode de clustering non supervisée qui vise à partitionner "n" (dans notre cas « n » articles de presse) observations en "k" clusters dans lesquels chaque observation appartient au cluster avec la moyenne la plus proche (le centroïde du cluster).
Le processus se déroule en plusieurs étapes :
- Initialisation : Choix aléatoire de
"k"points comme centroïdes initiaux. - Assignation : Chaque point (document) est affecté au cluster dont le centroïde est le plus proche.
- Mise à jour : Le centroïde de chaque cluster est recalculé comme étant le centre (moyenne) de tous les points assignés à ce cluster.
- Itération : Les étapes d’affectation et de mise à jour sont répétées jusqu’à ce que la position des centroïdes ne change plus significativement, indiquant que les clusters sont stables.

Chaque cluster représente un groupe d’articles qui sont similaires entre eux selon les caractéristiques extraites lors de la vectorisation.
Cela peut refléter une proximité thématique (des articles traitant de sujets similaires) ou lexicale (des articles utilisant un style ou un vocabulaire similaire).
Le script python
Le script est en version 1.0. J’ai testé et vérifié le script à partir d’un corpus de 1 026 articles provenant d’Europresse.
Chaque article commence par une première ligne avec ****, qui n’est pas prise en compte lors de l’analyse, mais qui sert à démarquer chaque article.
Pourquoi une première ligne étoilée ?
Parce que le corpus est formaté avec le script qui prépare les données pour un passage dans le logiciel IRAMUTEQ. (Vous pouvez vous référer aux trois scripts permettant de préparer les données pour IRAMUTEQ)
Promis ! dans la prochaine version du script, j’intégrerai un processus de formatage, ce qui évitera de lancer le script dédié à la préparation des données pour IRAMUTEQ.

Pour exécuter le script, c’est très simple : dans votre environnement Python, après avoir copié le code source et installé les bibliothèques nécessaires, il vous suffit de lancer la commande suivante : streamlit run main.py
Préparation des données
La préparation des données implique de sélectionner votre corpus (fichier texte .txt), de l’importer, puis de choisir un répertoire où les résultats du test seront enregistrés.

Analyse des données
Au delà du nombre de cluster (k) que vous allez pouvoir paramétrer, vous pourrez également modifier, les paramètres de vectorisation pour minimiser le bruit tout en capturant les termes les plus pertinents.
Le paramètre Min DF est réglé à 0,1, (par défaut) ce qui signifie que les termes doivent apparaître dans au moins 10% des documents pour être pris en compte. Cela permet d’éliminer les termes trop rares.
Le paramètre Max DF est fixé à 0,95, ce qui exclut les termes présents dans plus de 95% des documents, afin d’éviter les mots trop fréquents qui n’apportent pas de valeur significative à l’analyse.
Ces réglages sont optimisés pour une analyse équilibrée, sans nécessiter de modifications supplémentaires.

Visualisation des clusters
Après avoir exécuté le test K-means, vous obtiendrez plusieurs fichiers qui vous permettront d’analyser en profondeur les résultats.
Tout d’abord, vous disposerez d’un concordancier des phrases constituant les clusters, ce qui vous permettra de voir quelles phrases ont été regroupées ensemble.
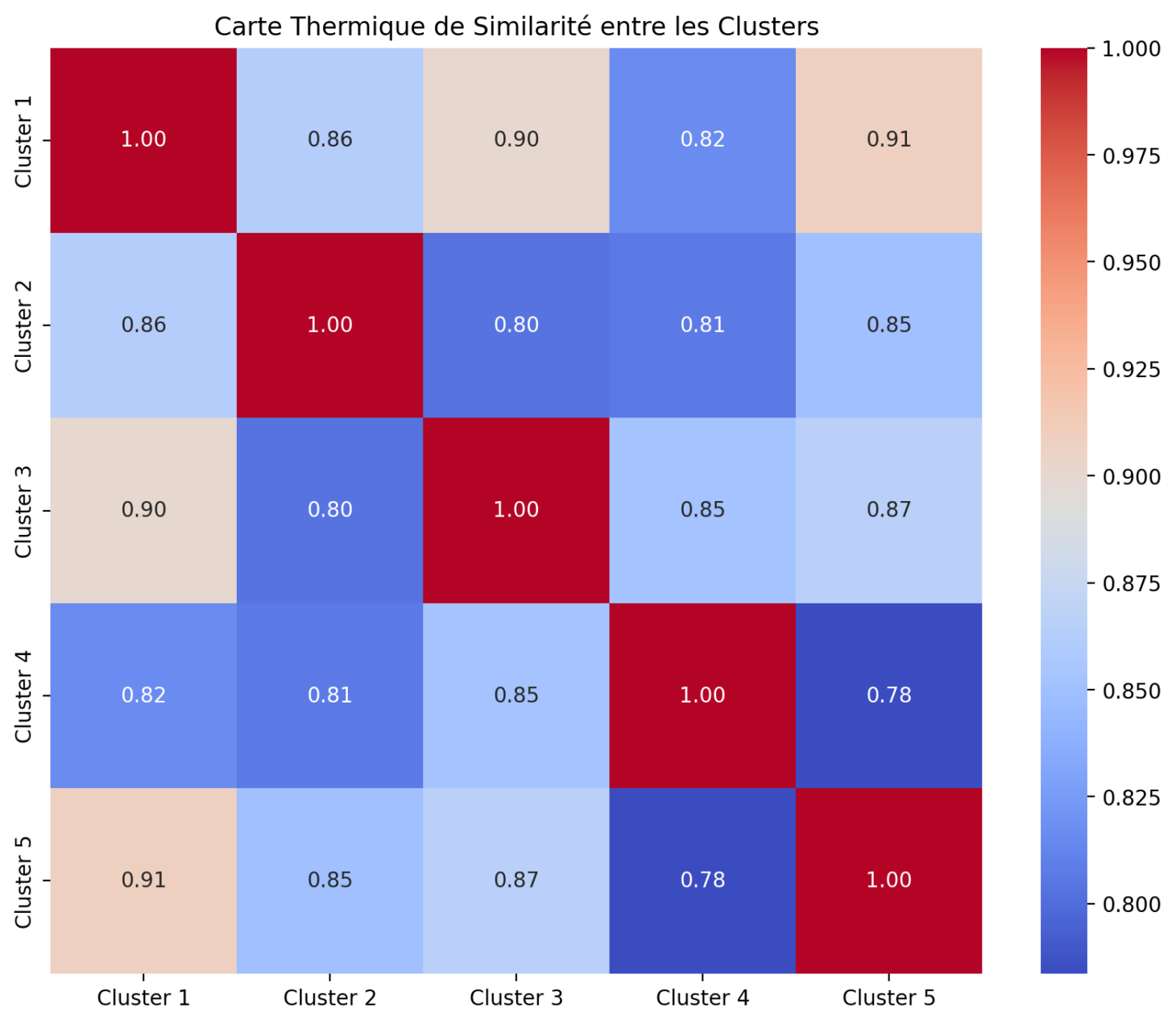
Ensuite, vous aurez accès à une visualisation de la similarité entre les clusters, ainsi qu’à une projection en 2D de ces clusters pour une exploration visuelle plus intuitive.
La similarité cosinus est une mesure utilisée pour évaluer à quel point deux vecteurs sont proches l’un de l’autre dans un espace vectoriel, ce qui, dans notre cas, reflète la similarité sémantique entre les clusters.
Une valeur de similarité cosinus de 1 indique que les vecteurs sont identiques, tandis qu’une valeur de 0 signifie qu’ils sont orthogonaux, donc complètement différents.
En complément, des nuages de mots sont générés pour chaque cluster, illustrant les termes les plus fréquents de chaque groupe.
Ces nuages de mots permettent de visualiser rapidement les thématiques principales de chaque cluster, en mettant en avant les mots qui définissent le mieux le contenu des groupes.
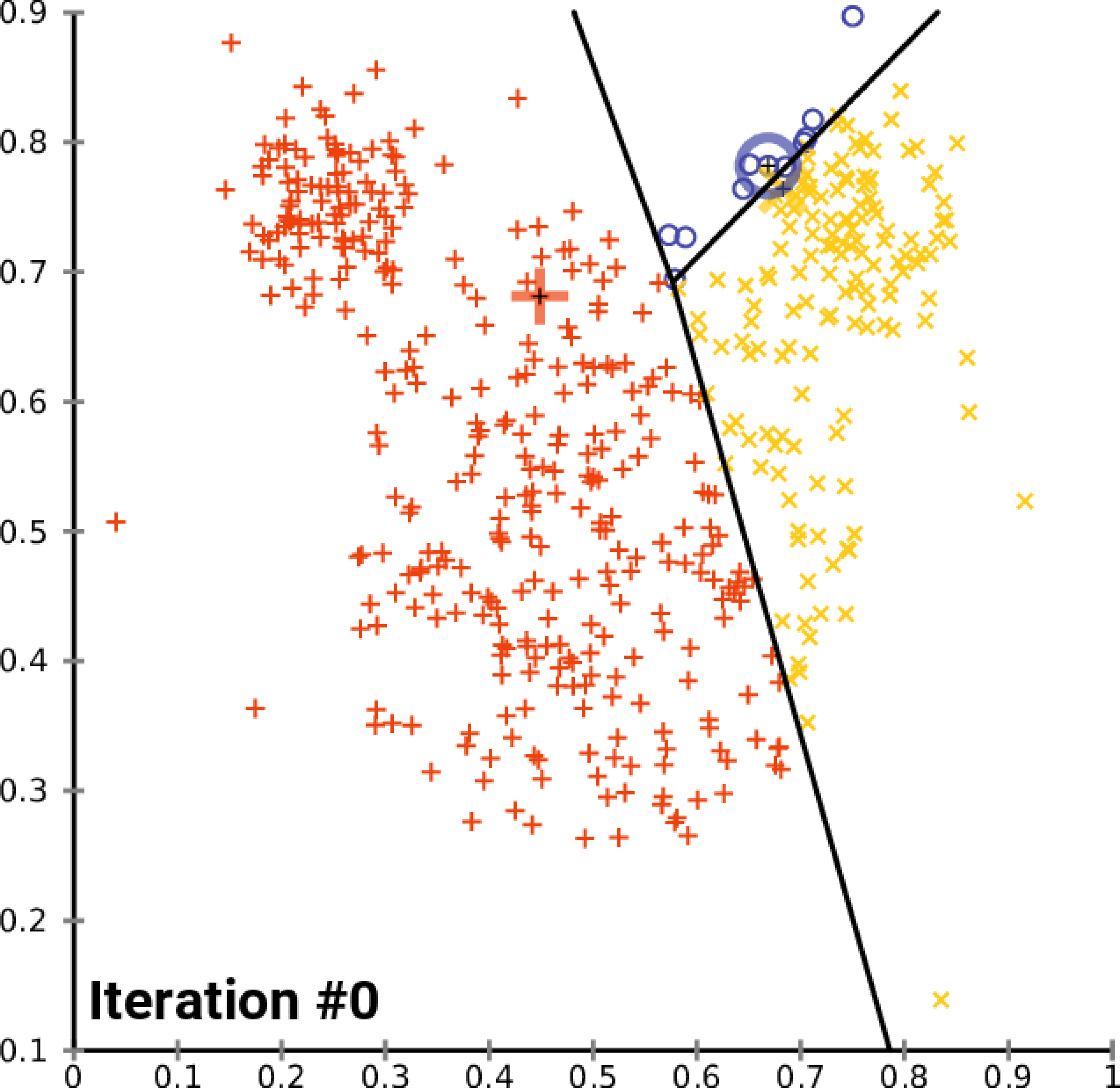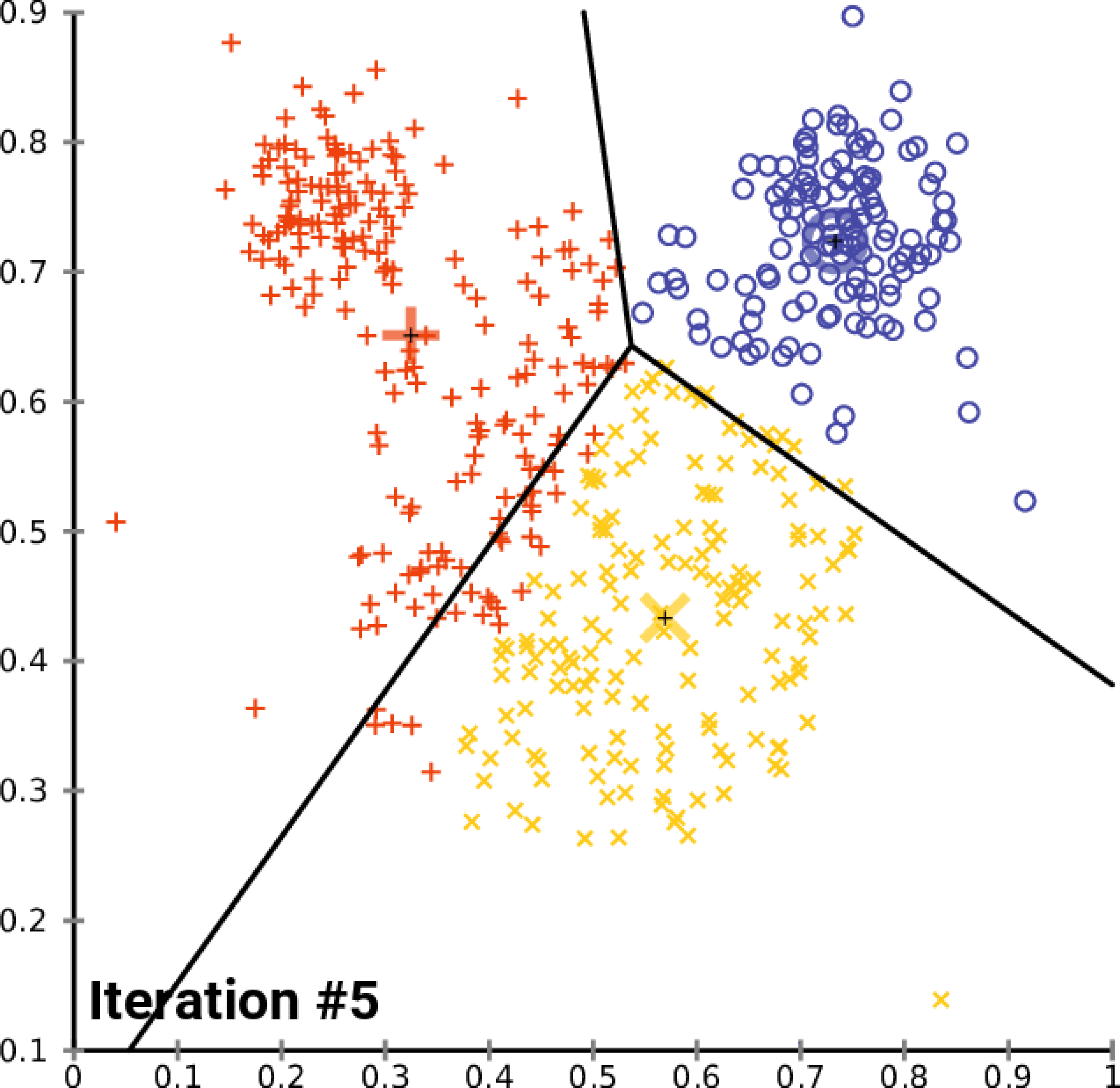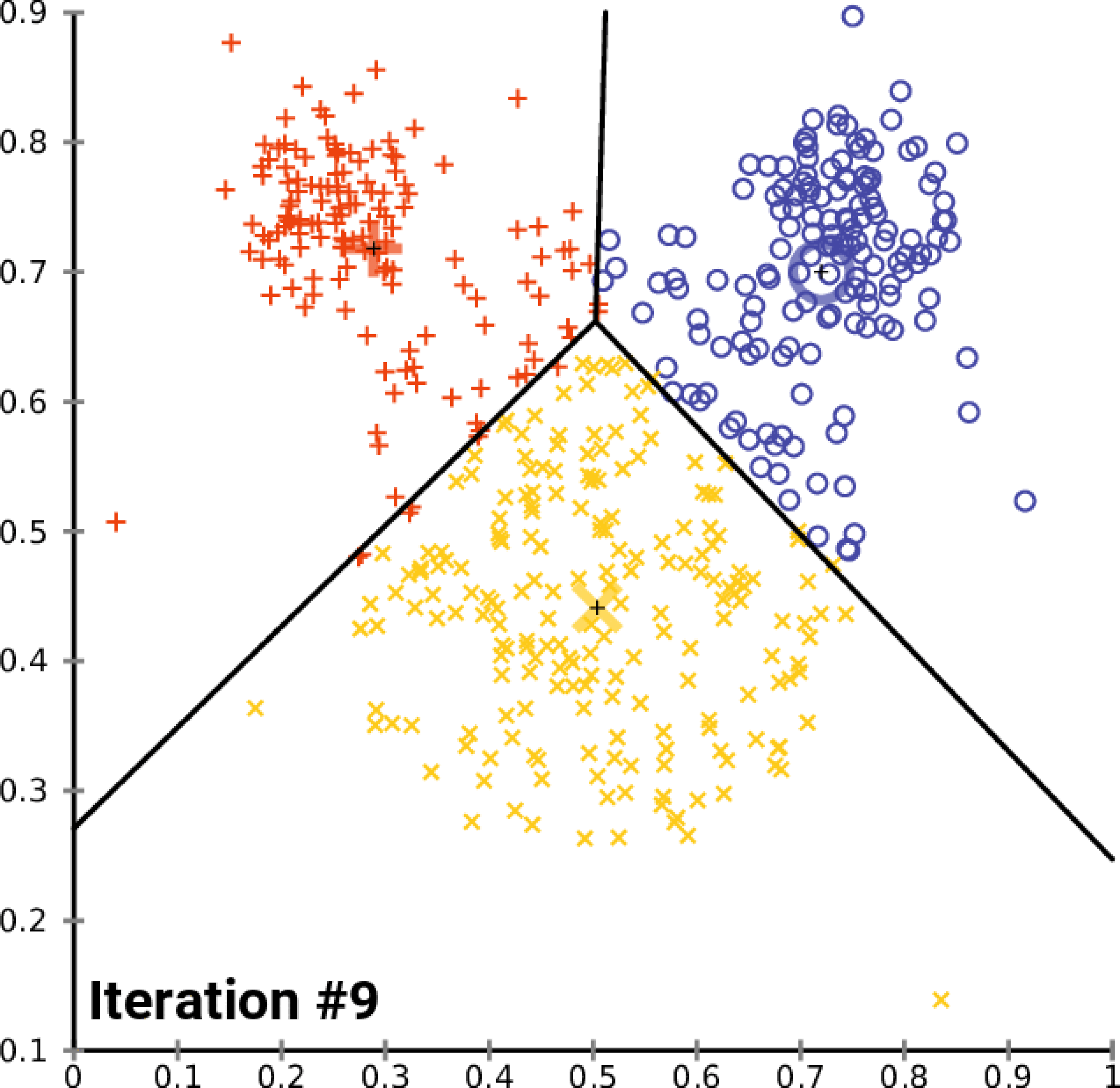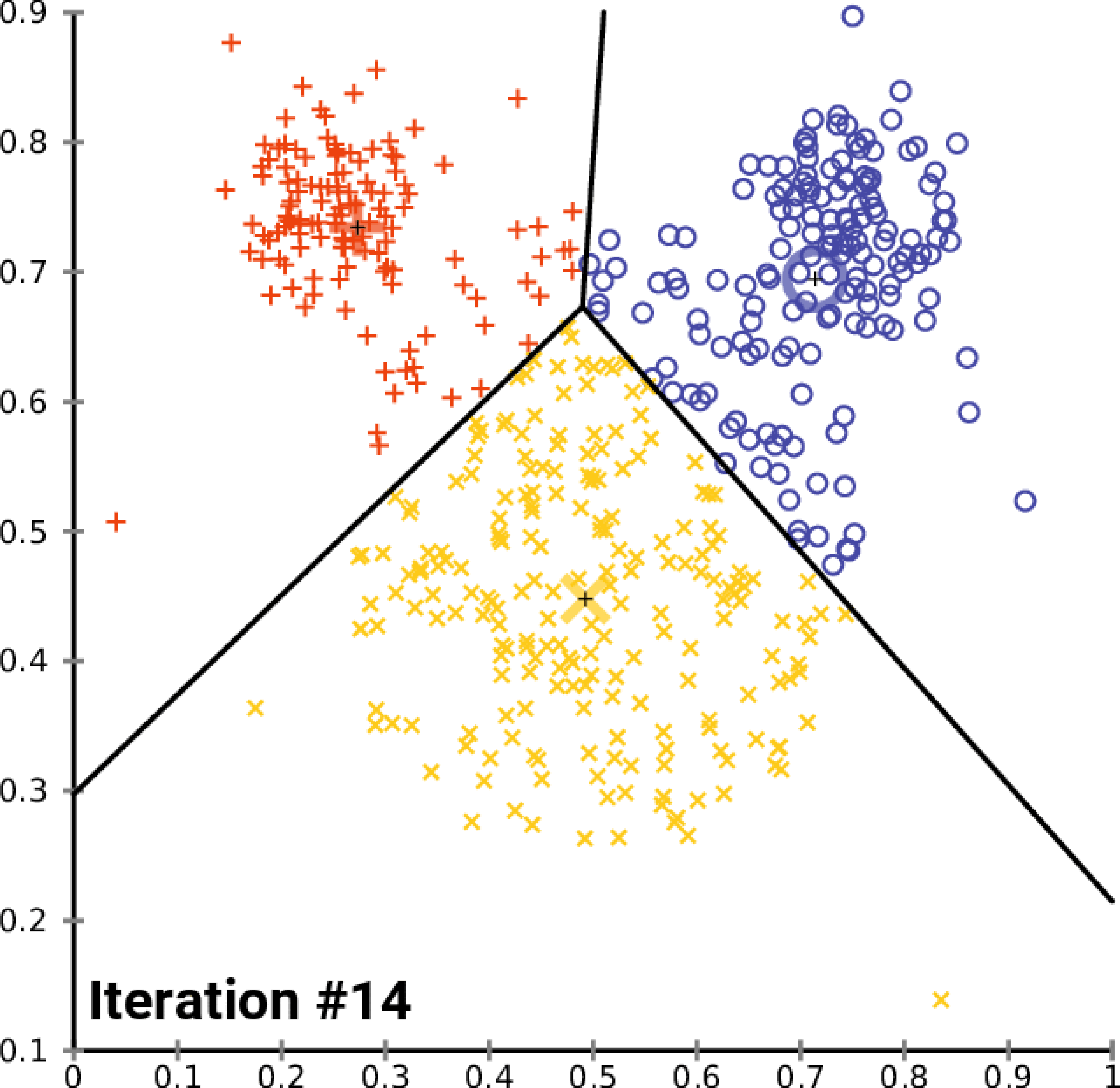
La visualisation des clusters sur un graphique en deux dimensions permet d’interpréter les résultats de manière intuitive.
Chaque point du graphique représente un élément du corpus, comme une phrase ou un document, et les points sont regroupés par couleur ou forme en fonction de leur appartenance à un cluster.
Les deux axes du graphique sont issus de techniques de réduction de dimensionnalité, telles que t-SNE ou UMAP, qui projettent les données dans un espace 2D tout en conservant les relations de similarité entre les points. Cette représentation visuelle est essentielle pour identifier les regroupements et les distinctions entre les clusters, ainsi que pour repérer les éventuels chevauchements (outliers).
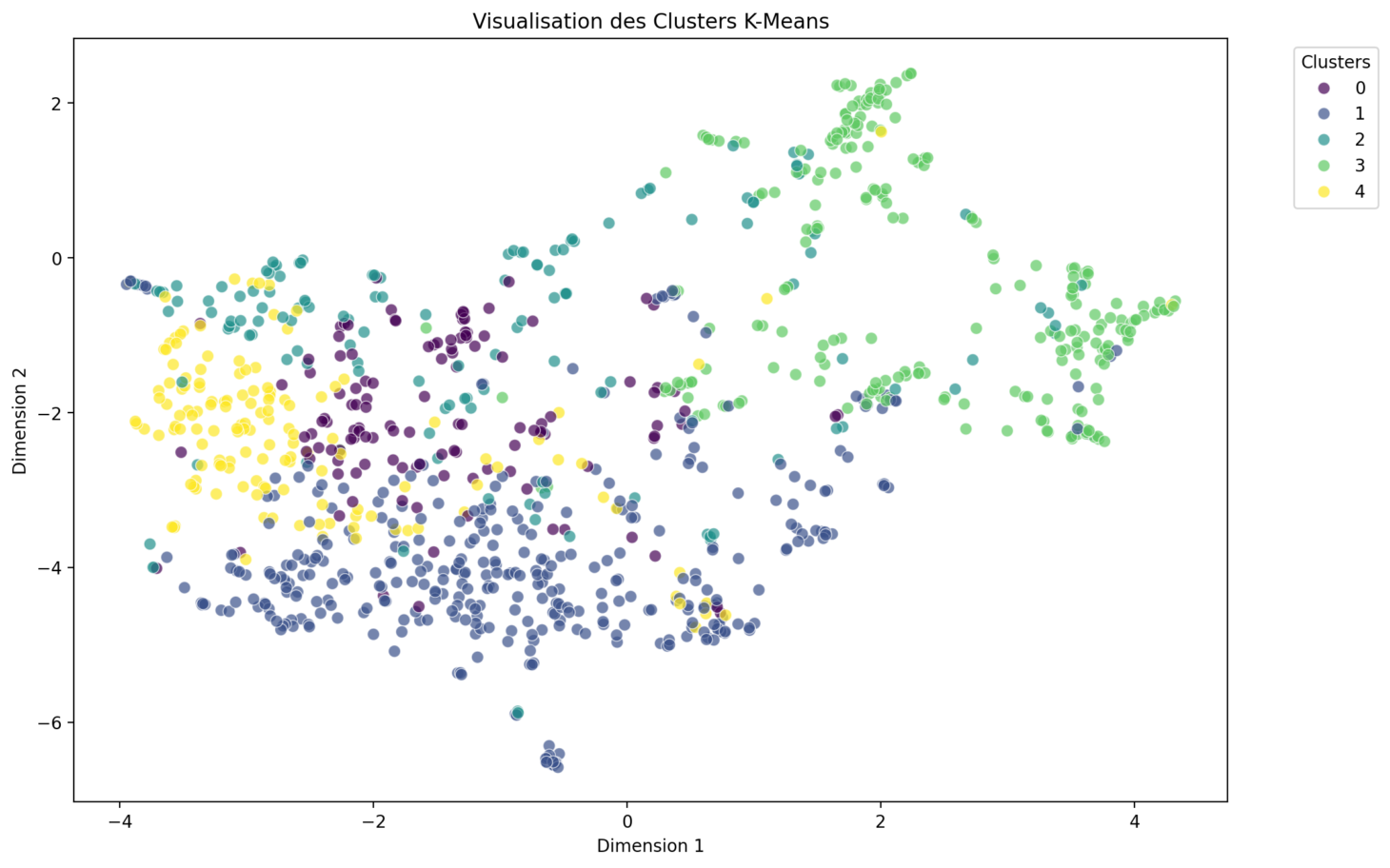
Dans le cadre de notre script, la visualisation des clusters est réalisée en utilisant la technique UMAP (Uniform Manifold Approximation and Projection).
UMAP est ici préférée à t-SNE pour plusieurs raisons pratiques et techniques. Tout d’abord, UMAP est souvent plus rapide à calculer. De plus, UMAP tend à mieux préserver la structure globale des données lors de la réduction de dimensionnalité, tout en maintenant une bonne séparation locale entre les points, ce qui facilite l’interprétation visuelle des clusters.
Cette approche permet ainsi d’obtenir une représentation en deux dimensions à la fois rapide et efficace, qui met en évidence les regroupements des données et les relations de similarité au sein des clusters.
Le code python
# pip install streamlit bertopic scikit-learn matplotlib pandas sentence-transformers nltk seaborn WordCloud
# pip install -U kaleido
# pip install transformers torch -> pour utiliser Camembert
import streamlit as st
import pandas as pd
import re
from sklearn.cluster import KMeans
from sentence_transformers import SentenceTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from io import StringIO, BytesIO
import requests
import nltk
from nltk.corpus import stopwords
from umap import UMAP # Import UMAP for dimensionality reduction
import plotly.express as px # Import plotly for bubble chart visualization
import numpy as np
import os # Pour gérer les opérations sur le système de fichiers
import datetime
# Télécharger le corpus de stop words si nécessaire
nltk.download('stopwords')
# Utiliser les stop words français de NLTK
french_stopwords = stopwords.words('french')
# Fonction pour extraire le contenu des articles
def parse_article(article_text):
lines = article_text.strip().split('\n')
content = '\n'.join(lines[1:]) if len(lines) > 1 else ''
return {'content': content}
# Fonction pour prétraiter le texte
def preprocess_text(text):
text = text.lower()
text = re.sub(r'\s+', ' ', text)
return text
# Fonction pour créer le concordancier
def create_concordance(df, clusters):
concordance_df = pd.DataFrame({
'Document': df['content'],
'Cluster': [f'Cluster {c + 1}' for c in clusters]
})
grouped_concordance = concordance_df.groupby('Cluster')['Document'].apply(lambda x: ' '.join(x)).reset_index()
return grouped_concordance
# Fonction pour télécharger un DataFrame en CSV
def save_csv(dataframe, filename, directory):
"""Enregistre un DataFrame en CSV dans un répertoire donné."""
path = os.path.join(directory, f"{filename}.csv")
dataframe.to_csv(path, index=False, encoding='utf-8')
st.success(f"Enregistré : {path}")
# Fonction pour afficher et télécharger la matrice de similarité cosinus entre les clusters
def display_similarity_matrix(embeddings, cluster_labels, directory):
# Calcul de la similarité entre les clusters
cluster_centers = [embeddings[cluster_labels == i].mean(axis=0) for i in range(max(cluster_labels) + 1)]
similarity_matrix = cosine_similarity(cluster_centers)
cluster_names = [f'Cluster {i + 1}' for i in range(len(cluster_centers))]
similarity_df = pd.DataFrame(similarity_matrix, columns=cluster_names, index=cluster_names)
st.write("Matrice de Similarité Cosinus entre les Clusters")
st.dataframe(similarity_df)
save_csv(similarity_df, "kmeans_cluster_similarity_matrix", directory)
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(similarity_df, cmap='coolwarm', ax=ax, annot=True, fmt=".2f", xticklabels=cluster_names,
yticklabels=cluster_names)
plt.title("Carte Thermique de Similarité entre les Clusters")
plt.savefig(os.path.join(directory, "similarity_heatmap.png"))
st.pyplot(fig)
st.success(f"Graphique enregistré : {os.path.join(directory, 'similarity_heatmap.png')}")
# Fonction pour afficher les nuages de mots pour chaque cluster
def display_wordclouds(df, cluster_labels, directory):
for cluster in set(cluster_labels):
st.subheader(f"Nuage de Mots pour le Topic {cluster + 1}")
cluster_data = df['content'][cluster_labels == cluster]
wordcloud_text = ' '.join(cluster_data)
wordcloud = WordCloud(width=800, height=400, background_color='white',
stopwords=set(french_stopwords)).generate(wordcloud_text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title(f'Topic {cluster + 1}') # Ajouter "Topic n°" au titre
plt.savefig(os.path.join(directory, f"wordcloud_topic_{cluster + 1}.png"))
st.pyplot(plt)
st.success(f"Nuage de mots enregistré : {os.path.join(directory, f'wordcloud_topic_{cluster + 1}.png')}")
# Fonction pour obtenir le texte d'une URL
def get_text_from_url(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
st.error("Impossible de récupérer le texte depuis l'URL.")
return ""
except Exception as e:
st.error(f"Erreur lors de la récupération du texte depuis l'URL : {str(e)}")
return ""
# Fonction pour afficher la visualisation des clusters en 2D
def display_cluster_visualization(embeddings, labels, directory):
# Réduire les dimensions des embeddings à 2D pour la visualisation
umap_model = UMAP(n_components=2, random_state=42)
reduced_embeddings = umap_model.fit_transform(embeddings)
# Créer un DataFrame pour la visualisation
viz_df = pd.DataFrame({
'x': reduced_embeddings[:, 0],
'y': reduced_embeddings[:, 1],
'Cluster': labels
})
plt.figure(figsize=(12, 8))
sns.scatterplot(data=viz_df, x='x', y='y', hue='Cluster', palette='viridis', s=50, alpha=0.7)
plt.title("Visualisation des Clusters K-Means")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.legend(title='Clusters', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.savefig(os.path.join(directory, "kmeans_cluster_2D.png"))
st.pyplot(plt)
st.success(f"Graphique 2D enregistré : {os.path.join(directory, 'kmeans_cluster_2D.png')}")
# Fonction pour visualiser les centroides des clusters
def display_centroid_visualization(embeddings, cluster_labels, directory):
# Calculer les centroids des clusters
cluster_centers = np.array([embeddings[cluster_labels == i].mean(axis=0) for i in range(max(cluster_labels) + 1)])
# Réduire les dimensions des centroids à 2D pour la visualisation
umap_model = UMAP(n_components=2, random_state=42)
reduced_centroids = umap_model.fit_transform(cluster_centers)
# Créer un DataFrame pour la visualisation
df_centroids = pd.DataFrame({
'x': reduced_centroids[:, 0],
'y': reduced_centroids[:, 1],
'Cluster': range(1, len(cluster_centers) + 1),
'Size': [10] * len(cluster_centers) # La taille des bulles peut être personnalisée
})
fig = px.scatter(
df_centroids, x='x', y='y', size='Size', color='Cluster',
title='Visualisation des Centroides des Clusters',
labels={'x': 'Dimension 1', 'y': 'Dimension 2', 'Cluster': 'Clusters'},
hover_data={'Size': False}
)
fig.update_traces(marker=dict(opacity=0.6))
st.plotly_chart(fig)
fig.write_image(os.path.join(directory, "kmeans_centroid_visualization.png"))
st.success(f"Graphique des centroids enregistré : {os.path.join(directory, 'kmeans_centroid_visualization.png')}")
# Fonction pour visualiser les clusters regroupés en bulles
def display_grouped_bubble_chart(embeddings, cluster_labels, directory):
umap_model = UMAP(n_components=2, random_state=42)
reduced_embeddings = umap_model.fit_transform(embeddings)
df = pd.DataFrame({
'x': reduced_embeddings[:, 0],
'y': reduced_embeddings[:, 1],
'Cluster': cluster_labels
})
# Calculer la taille de chaque bulle en fonction du nombre de points dans chaque cluster
cluster_sizes = df['Cluster'].value_counts().sort_index()
df['Size'] = df['Cluster'].map(cluster_sizes)
fig = px.scatter(
df, x='x', y='y', size='Size', color='Cluster',
hover_data=['Cluster'], opacity=0.6, size_max=50,
title='Visualisation des Clusters Regroupés en Forme de Bulles'
)
fig.update_layout(showlegend=True)
st.plotly_chart(fig)
fig.write_image(os.path.join(directory, "kmeans_grouped_bubble_chart.png"))
st.success(
f"Graphique des bulles regroupées enregistré : {os.path.join(directory, 'kmeans_grouped_bubble_chart.png')}")
# Fonction principale pour l'analyse
def main():
# Titre de l'application
st.set_page_config(page_title="Analyse textuelle avec K-means")
st.title("Analyse textuelle avec K-means")
st.markdown(
"**Version du script : 1.0 - Date : 09-08-2024 - Stéphane Meurisse - [www.codeandcortex.fr](https://www.codeandcortex.fr)**")
# Menu principal
menu_principal = st.sidebar.radio(
"Menu Principal",
["Préparation des Données", "Analyse des Données", "FAQ"]
)
# Initialiser le conteneur de session pour stocker le DataFrame et le nom du fichier
if 'df' not in st.session_state:
st.session_state.df = None
if 'file_name' not in st.session_state:
st.session_state.file_name = None
if 'save_directory' not in st.session_state:
st.session_state.save_directory = None
if menu_principal == "Préparation des Données":
st.sidebar.markdown("### Préparation des Données")
# Sous-menu pour les options de préparation des données
preparation_option = st.sidebar.radio(
"Options de Préparation",
["Uploader un Fichier", "URL"]
)
if preparation_option == "Uploader un Fichier":
st.subheader("Uploader un Fichier")
uploaded_file = st.file_uploader("Téléchargez un fichier texte contenant des articles de presse",
type="txt")
if uploaded_file is not None:
# Stocker le nom du fichier
st.session_state.file_name = uploaded_file.name
stringio = StringIO(uploaded_file.getvalue().decode("utf-8"))
raw_articles = stringio.read().strip().split('****')
articles_data = [parse_article(article) for article in raw_articles if article.strip()]
st.session_state.df = pd.DataFrame(articles_data)
st.session_state.df['content'] = st.session_state.df['content'].apply(preprocess_text)
st.write(st.session_state.df)
st.sidebar.text(f"Fichier chargé : {st.session_state.file_name}")
elif preparation_option == "URL":
st.subheader("URL")
url = st.text_input("Entrez l'URL du texte")
if url:
file_text = get_text_from_url(url)
raw_articles = file_text.strip().split('****')
articles_data = [parse_article(article) for article in raw_articles if article.strip()]
st.session_state.df = pd.DataFrame(articles_data)
st.session_state.df['content'] = st.session_state.df['content'].apply(preprocess_text)
st.write(st.session_state.df)
st.sidebar.text(f"Fichier chargé depuis l'URL")
if st.session_state.df is not None:
# Afficher le nombre total d'articles trouvés
total_articles = len(st.session_state.df)
st.markdown(f"**Nombre d'articles trouvés : {total_articles}**")
# Demander à l'utilisateur de définir un répertoire de sauvegarde
st.subheader("Définir le Répertoire de Sauvegarde")
save_directory = st.text_input("Entrez le chemin du répertoire de sauvegarde",
value=os.path.expanduser("~/Documents/AnalyseTextuelle"))
if st.button("Définir le Répertoire"):
if not os.path.exists(save_directory):
os.makedirs(save_directory)
st.session_state.save_directory = save_directory
st.success(f"Répertoire de sauvegarde défini : {save_directory}")
elif menu_principal == "Analyse des Données":
st.sidebar.markdown("### Analyse des Données")
# Vérification si les données sont chargées
if st.session_state.df is None:
st.error("Veuillez d'abord préparer vos données dans la section précédente.")
return
# Vérification du répertoire de sauvegarde
if st.session_state.save_directory is None:
st.error("Veuillez d'abord définir un répertoire de sauvegarde dans la section de préparation des données.")
return
# Afficher le nom du fichier chargé dans la barre latérale
if st.session_state.file_name:
st.sidebar.text(f"Fichier chargé : {st.session_state.file_name}")
# Utilisation des données préparées
df = st.session_state.df
save_directory = st.session_state.save_directory
st.subheader("KMeans")
st.write("**KMeans**: Algorithme de clustering qui partitionne les données en un nombre fixe de clusters.")
# Initialiser SentenceTransformer pour créer des embeddings
sentence_model = SentenceTransformer("all-MiniLM-L6-v2")
# Générer les embeddings pour chaque article
embeddings = sentence_model.encode(df['content'].tolist(), show_progress_bar=True)
# Paramètres min_df et max_df ajustables par l'utilisateur
st.sidebar.subheader("Paramètres du Vectorizer")
min_df = st.sidebar.slider("Min DF (fraction minimale de documents)", 0.0, 1.0, 0.01, 0.01)
max_df = st.sidebar.slider("Max DF (fraction maximale de documents)", min_df, 1.0, 0.95, 0.01)
vectorizer_model = CountVectorizer(stop_words=french_stopwords, min_df=min_df, max_df=max_df,
ngram_range=(1, 3))
# Appliquer la méthode du coude pour déterminer le nombre optimal de clusters
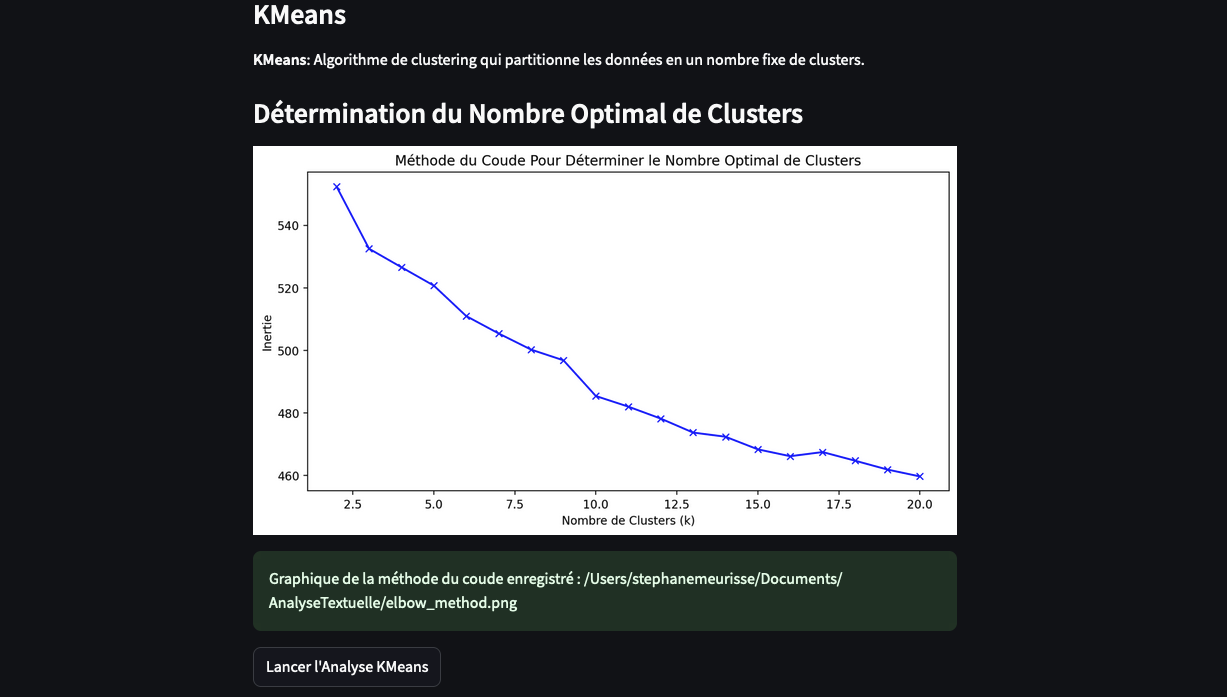
st.subheader("Détermination du Nombre Optimal de Clusters")
inertia = []
K = range(2, 21)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(embeddings)
inertia.append(kmeans.inertia_)
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(K, inertia, 'bx-')
ax.set_xlabel('Nombre de Clusters (k)')
ax.set_ylabel('Inertie')
ax.set_title('Méthode du Coude Pour Déterminer le Nombre Optimal de Clusters')
st.pyplot(fig)
plt.savefig(os.path.join(save_directory, "elbow_method.png"))
st.success(f"Graphique de la méthode du coude enregistré : {os.path.join(save_directory, 'elbow_method.png')}")
# Slider pour permettre à l'utilisateur de choisir le nombre de clusters
n_clusters = st.sidebar.slider("Choisissez le nombre de clusters", 2, 20, 5, 1)
# Bouton pour lancer l'analyse KMeans
if st.button("Lancer l'Analyse KMeans"):
cluster_model = KMeans(n_clusters=n_clusters, random_state=42)
kmeans_labels = cluster_model.fit_predict(embeddings)
unique_clusters = len(set(kmeans_labels))
st.write(f"Clusters KMeans trouvés : {unique_clusters} (regroupés)")
if unique_clusters > 0:
# Visualisation des centroids des clusters
st.subheader("Visualisation des Centroides des Clusters K-Means")
display_centroid_visualization(embeddings, kmeans_labels, save_directory)
# Visualisation des clusters en forme de bulle regroupés
st.subheader("Visualisation des Clusters Regroupés en Forme de Bulles")
display_grouped_bubble_chart(embeddings, kmeans_labels, save_directory)
# Visualisation des clusters en 2D
st.subheader("Visualisation des Clusters en 2D")
display_cluster_visualization(embeddings, kmeans_labels, save_directory)
st.subheader("Carte Thermique de Similarité des Clusters")
display_similarity_matrix(embeddings, kmeans_labels, save_directory)
concordance_kmeans = create_concordance(df, kmeans_labels)
st.subheader("Concordancier KMeans")
st.dataframe(concordance_kmeans)
save_csv(concordance_kmeans, "concordance_kmeans", save_directory)
display_wordclouds(df, kmeans_labels, save_directory)
elif menu_principal == "FAQ":
st.sidebar.markdown("### FAQ")
st.subheader("FAQ : Analyse Textuelle avec K-Means++")
st.markdown("""
### 1. Préparation des Données
Avant d'appliquer l'algorithme K-Means++, il est crucial de préparer correctement vos données. Le script a été conçu pour fonctionner avec des articles provenant de la plateforme **Europresse**, et est compatible avec le logiciel **Iramuteq**. Pour garantir un traitement adéquat, chaque article doit être précédé d'une ligne de démarcation commençant par `****`. Cette structure est essentielle pour que le script puisse identifier et traiter chaque article distinctement.
- **Format d'entrée :**
- **Fichiers Texte :** Les fichiers doivent être en format texte, avec des articles séparés par `****`.
- **URL :** Vous pouvez également fournir une URL d'où le texte sera extrait.
### 2. Algorithme K-Means++
**K-Means++** est une amélioration de l'algorithme de clustering K-Means standard. Il est utilisé pour partitionner les données en un nombre fixe de groupes, appelés clusters. Voici une explication détaillée de son fonctionnement et de sa mise en œuvre dans votre script.
#### Comment Fonctionne K-Means++ :
- **Initialisation Améliorée :**
- Contrairement à l'initialisation aléatoire de K-Means, K-Means++ choisit les centroïdes initiaux de manière stratégique. Le premier centroïde est sélectionné aléatoirement, et les suivants sont choisis en fonction de leur distance par rapport aux centroïdes déjà sélectionnés, favorisant une répartition plus uniforme.
- **Assignation des Points :**
- Chaque point de données est assigné au cluster avec le centroïde le plus proche, généralement calculé avec la distance euclidienne.
- **Mise à jour des Centroïdes :**
- Pour chaque cluster, le centroïde est recalculé comme la moyenne de tous les points assignés à ce cluster.
- **Convergence :**
- L'algorithme répète les étapes d'assignation et de mise à jour jusqu'à ce que les centroïdes se stabilisent ou qu'un nombre maximal d'itérations soit atteint.
#### Visualisation des Résultats :
- **Centroides et Clusters :**
- Le script génère plusieurs graphiques pour visualiser les clusters et leurs centroïdes :
- **Graphique des Centroides :** Visualisation des positions moyennes des clusters après convergence.
- **Carte Thermique de Similarité :** Visualisation des similarités entre les clusters, basée sur la distance entre les centroïdes.
- **Nuages de Mots :** Mots-clés caractéristiques de chaque cluster, permettant de comprendre le contenu textuel de chaque groupe.
### 3. Bibliothèques Python Utilisées :
- **Scikit-learn :** Pour l'implémentation de K-Means++, le calcul des clusters, et la gestion des données de texte.
- **SentenceTransformers :** Pour générer des embeddings à partir des textes, facilitant leur utilisation dans le clustering.
- **Matplotlib, Seaborn, Plotly :** Pour la création de graphiques et la visualisation des résultats.
- **WordCloud :** Pour la génération de nuages de mots permettant d'interpréter facilement les thèmes des clusters.
### 4. Paramètres de K-Means++ :
- **`n_clusters` (Nombre de Clusters) :**
- **Description :** Indique le nombre de clusters que l'algorithme doit former. L'utilisateur doit déterminer cette valeur à l'avance.
- **Impact :** Un nombre trop élevé peut fragmenter des clusters naturels, tandis qu'un nombre trop bas peut regrouper des données disparates.
- **Détermination :** La méthode du coude est souvent utilisée pour déterminer le nombre optimal de clusters en traçant l'inertie (la somme des distances au carré entre les points et leur centroïde respectif) en fonction du nombre de clusters. Le point où l'inertie commence à diminuer moins rapidement (le coude) est considéré comme optimal.
- **`init` :**
- **Description :** Méthode d'initialisation des centroïdes.
- **Options :** Par défaut, `k-means++` est utilisé pour une meilleure convergence.
- **Impact :** L'initialisation K-Means++ permet d'éviter les mauvaises initialisations qui peuvent conduire à des solutions sous-optimales.
- **`max_iter` :**
- **Description :** Nombre maximal d'itérations pour une exécution de l'algorithme.
- **Impact :** Influence la durée de l'exécution. Un nombre d'itérations trop élevé peut entraîner une perte de temps, mais il est généralement suffisant pour atteindre la convergence.
- **`tol` :**
- **Description :** Tolérance pour la convergence. Détermine à quel point le déplacement des centroïdes doit être petit pour que l'algorithme s'arrête.
- **`random_state` :**
- **Description :** Assure la reproductibilité des résultats en fixant une graine pour la génération aléatoire.
#### Point Négatif : Détermination du Nombre de Clusters
- **Limitation :** Contrairement à des approches comme LDA (Latent Dirichlet Allocation) ou BERTopic, qui peuvent découvrir automatiquement des thèmes ou des topics, K-Means++ nécessite que l'utilisateur spécifie *a priori* le nombre de clusters. Cela peut être un inconvénient si l'utilisateur n'a pas une bonne intuition de la structure des données.
- **Comparaison avec LDA et BERTopic :**
- **LDA :** Identifie automatiquement les sujets dans un corpus textuel, utile pour des explorations sans connaissance préalable.
- **BERTopic :** Utilise des méthodes avancées pour découvrir des topics de manière plus flexible et peut s'adapter aux données sans pré-spécification du nombre de topics.
### 5. Exemples d'Utilisation en Sciences Humaines
- **Analyse Textuelle :**
- **Regroupement de Documents :** Utiliser K-Means++ pour organiser des articles de presse en catégories thématiques, permettant ainsi une meilleure compréhension des sujets traités dans un grand volume de texte.
- **Segmentation des Utilisateurs :** Analyser les comportements ou préférences des utilisateurs en ligne, par exemple, pour regrouper des commentaires ou des avis en clusters distincts.
- **Sciences Humaines :**
- **Études Littéraires :** Clustering de corpus littéraires pour identifier des styles d'écriture ou des thèmes communs dans les œuvres de différents auteurs ou périodes.
- **Analyse Sociologique :** Identifier des groupes d'individus aux comportements ou opinions similaires à partir de données textuelles collectées via des enquêtes ou des réseaux sociaux.
#### Pourquoi Utiliser K-Means++ pour l'Analyse Textuelle ?
- **Simplicité et Efficacité :**
- Facile à comprendre et à implémenter. Idéal pour des tâches nécessitant une première segmentation des données.
- **Adaptabilité :**
- Fonctionne bien sur de grands ensembles de données textuelles, offrant une vue d'ensemble rapide et intuitive des clusters thématiques.
- **Complémentarité :**
- Peut être utilisé en complément d'autres méthodes d'analyse textuelle, comme l'analyse de la fréquence des termes ou les modèles de thématiques, pour affiner la compréhension des données.
### Conclusion
K-Means++ est un algorithme puissant pour la segmentation des données, particulièrement utile dans l'analyse textuelle des sciences humaines. Bien que nécessitant une certaine intuition pour définir le nombre de clusters, ses résultats peuvent révéler des structures cachées dans les données et fournir une base solide pour des analyses plus approfondies.
""")
if __name__ == "__main__":
main()
Conclusion
Cet article décrit la première version du test K-means à l’aide de l’interface Streamlit. Il s’agit de la version 1, qui utilise le modèle all-MiniLM-L6-v2.
Une seconde version sera prochainement disponible, permettant de choisir entre l’utilisation de Camembert et de all-MiniLM-L6-v2.
C’est donc une première version relativement simple, mais elle permettra de corriger les bugs au fur et à mesure de son utilisation.
[…] non-supervisé), en exploitant des techniques issues du data mining. Par exemple, k-means, bien que classique, reste pertinent, mais c’est surtout l’algorithme LDA (Latent Dirichlet […]