En développant un modèle de reconnaissance des émotions par la voix (SER, pour Speech Emotion Recognition), je n’ai pas choisi la voie la plus simple pour me familiariser avec les modèles de deep learning et l’intégration de la couche de traitement “audio” dans une approche multimodale. Pourquoi ? Parce que, comparée à des domaines comme la reconnaissance faciale, la précision des modèles basés sur la voix reste souvent bien en deçà. Par exemple, après l’entraînement sur le dataset RAVDESS, mon modèle atteint une précision de seulement 64 %, ce qui est relativement faible.
De plus, l’analyse de la matrice de confusion (du modèle entrainé) révèle que certaines émotions auraient probablement dû être regroupées pour améliorer la précision du modèle.
Les catégories “neutral” et “calm” (sur les fichier audio), par exemple, sont particulièrement difficiles à distinguer et pourraient être fusionnées pour simplifier la classification.
Nous approfondirons ce point dans un prochain article.
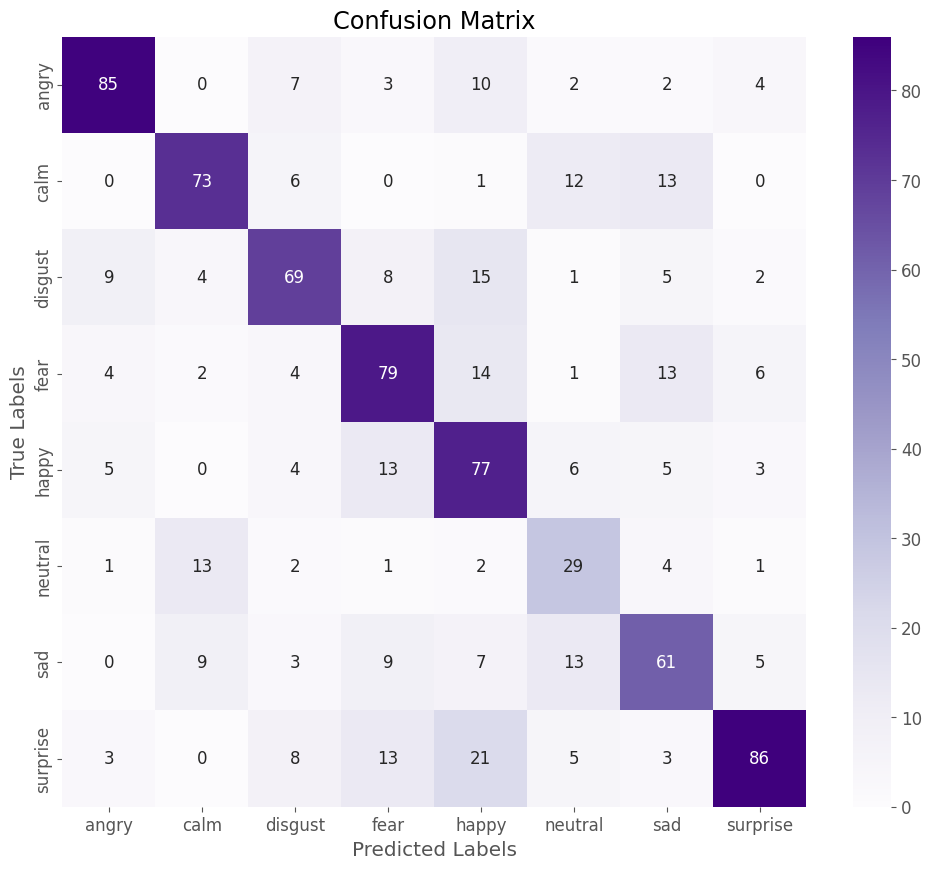
L’objectif principal ici est de confronter le modèle à l’épreuve des faits ! Mais soyons honnêtes : le modèle n’est pas particulièrement discriminant.
L’émotion “neutre” domine largement les prédictions, ce qui reflète la précision limitée du modèle, évaluée à 64 %.
Dans cet article, nous allons nous concentrer sur la mise en pratique et le test du modèle, en allant au-delà des simples métriques pour analyser son comportement sur une vidéo réelle.
Le processus est relativement simple : nous utilisons une vidéo YouTube, en l’occurrence un discours de Donald Trump annonçant sa réélection, en réalisant l’extraction de la piste audio.
Cependant, le véritable défi réside dans la question de la granularité de l’analyse : doit-on considérer la vidéo dans son intégralité et obtenir une prédiction globale d’émotion pour toute la durée ?
Ou doit-on segmenter l’audio pour une analyse plus fine ?
Après quelques tests, et dans le cadre d’une approche multimodale, il m’est apparu pertinent de découper la piste audio en segments synchronisés avec les timestamps du discours/texte. Ces timestamps servent de repères pour segmenter l’audio, permettant ainsi une analyse synchronisée entre les émotions prédites, le texte, (et potentiellement les images).

Bien sûr, avec une précision limitée à 64 %, cet exercice relève davantage d’une exploration méthodologique que d’une analyse fiable des émotions. La question centrale reste donc celle de la granularité, une problématique déjà rencontrée lors de mes tests d’analyse des émotions basées sur les images.
Dans le cadre de l’analyse de l’image/émotion, il semble qu’une synchronisation précise entre l’image, le discours et l’émotion prédite est essentielle.
Cependant, un autre point mérite réflexion : dans les segments où l’orateur ne parle pas, des indices significatifs pourraient émerger, tels qu’un moment de réflexion ou d’introspection – une sorte de “métacognition” (même si ce terme n’est peut-être pas adapté). Ces silences pourraient refléter une stratégie cognitive liée au message à transmettre.
Ainsi, cette réflexion sur la granularité et l’analyse synchrone/asynchrone entre l’image, le discours, la voix et les émotions ouvre des perspectives intéressantes.
Le test sera réalisé à partir de deux vidéos
Le discours de Donald Trump prononcé lors de sa campagne pour la réélection.
Le discours de Kamala Harris annonçant sa défaite aux élections. Cette vidéo présente une qualité audio assez moyenne, en particulier au niveau de la fréquence d’échantillonnage, alors que le modèle est entraîné sur une fréquence standard de 16 kHz (sr=16000).
Dans le script, la fonction librosa.load force la fréquence d’échantillonnage (sample rate) à sr=16000 lorsque les fichiers audio sont chargés. Par conséquent, même si la vidéo source n’est pas encodée à 16000 Hz, le script re-sample l’audio au bon taux.
audio, _ = librosa.load(files[i + j], sr=sr)
Fonctionnement du script
L’intégralité du script est partagé sur Google Colab.
Pour commencer, vous devrez installer les librairies nécessaires.
Avec Google Colab, rappelez-vous que l’installation se fait avec une syntaxe précédée de !.
!pip install librosa tensorflow sklearn moviepy matplotlib seaborn !apt-get install -y ffmpeg !pip install librosa soundfile !pip install yt-dlp==2024.12.3 !apt-get update && apt-get install -y ffmpeg !pip install git+https://github.com/openai/whisper.git
Pour ce script, l’utilisation du CPU par defaut (le plus économique) est généralement suffisante.
Dans un premier temps, vous devez spécifier et ajuster les chemins où seront stockés les segments audio extraits de la vidéo ainsi que les fichiers de résultats.
# Chemins model_path = "/content/drive/MyDrive/DataSet/Ravdess/Modele/emotion_model_RAVDESS-CNN-V4.h5" # ici est le chemin de votre modèle audio_output_path = "/content/drive/MyDrive/DataSet/Ravdess/Modele/Test/concatenation/trump_audio.wav" segments_save_path = "/content/drive/MyDrive/DataSet/Ravdess/Modele/Test/concatenation/segments/" concat_segments_path = "/content/drive/MyDrive/DataSet/Ravdess/Modele/Test/concatenation/concat_segments/" transcription_path = "/content/drive/MyDrive/DataSet/Ravdess/Modele/Test/concatenation/transcription_segments.csv" results_path = "/content/drive/MyDrive/DataSet/Ravdess/Modele/Test/concatenation/resultats_segments.csv" concat_results_path = "/content/drive/MyDrive/DataSet/Ravdess/Modele/Test/concatenation/resultats_concatenation.csv"
De même, vous devez spécifier le chemin vers votre modèle.
Cela fait naturellement référence à l’article sur la construction du modèle. Cependant, si vous préférez éviter une “prise de neurones” 😉 lors de la création d’un modèle de prédiction “Speech Emotion Recognition (SER)“, je mets à disposition le modèle pré-entraîné ICI faisant référence à l’article.
Vous n’avez qu’à le télécharger et l’intégrer dans votre répertoire Google Drive et redéfinir le chemin du modèle dans le script.
# Chemins model_path = "/content/drive/MyDrive/DataSet/Ravdess/Modele/emotion_model_RAVDESS-CNN-V4.h5" # ici est le chemin de votre modèle
Vous n’avez qu’à spécifier les répertoires cibles dans Google drive ou bien le script se chargera de les créer si vous ne l’avez pas fait manuellement.
# Créer les répertoires nécessaires os.makedirs(segments_save_path, exist_ok=True) os.makedirs(concat_segments_path, exist_ok=True)
Enfin, il est nécessaire de spécifier l’URL YouTube de la vidéo à analyser. Le script n’est pas conçu pour fonctionner directement avec un fichier audio au format .wav.
Il est développé pour extraire la piste audio d’une vidéo YouTube, afin de collecter des données “authentiques” issues des réseaux sociaux. Bien qu’il soit envisageable d’adapter ce script à l’analyse de fichiers audio, tels que ceux issus d’entretiens cliniques, ce n’est pas sa finalité initiale.
# Télécharger et extraire l'audio directement
def download_audio(video_url, temp_audio_output_path, audio_output_path):
print("Téléchargement et extraction de l'audio depuis YouTube...")
command = f'yt-dlp -x --audio-format wav -o "{temp_audio_output_path}" "{video_url}"'
os.system(command)
if os.path.exists(temp_audio_output_path):
print(f"Audio extrait avec succès : {temp_audio_output_path}")
shutil.move(temp_audio_output_path, audio_output_path)
print(f"Fichier déplacé : {audio_output_path}")
return True
else:
print(f"Erreur : extraction audio échouée. Chemin attendu : {temp_audio_output_path}")
return False
Analyse des segments basée sur le timestamp textuel
Le script découpe le fichier audio en segments alignés avec les timestamps (horodatage en Français) du texte.
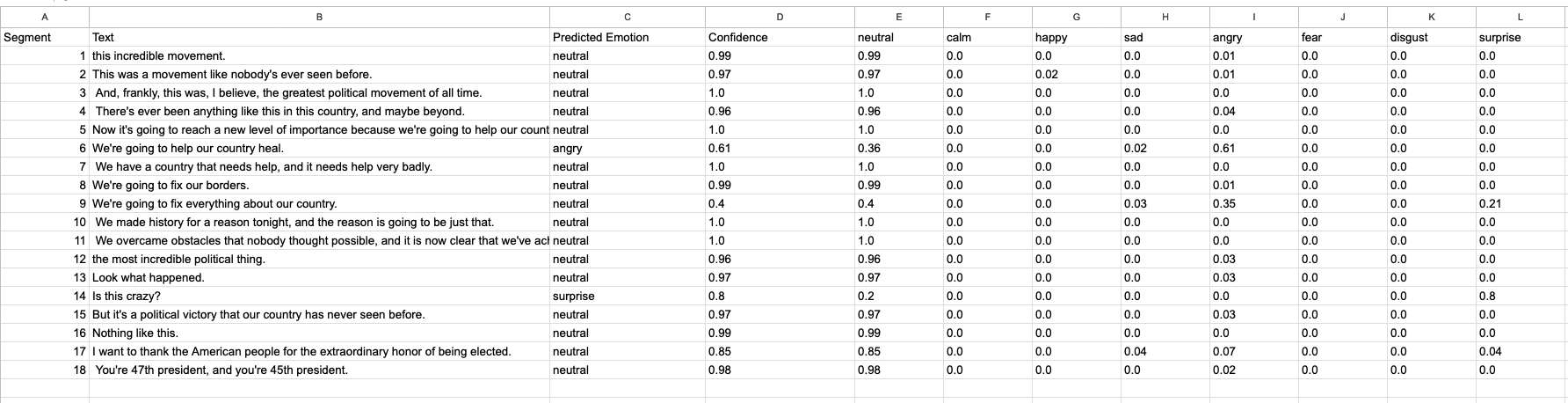
Vous retrouverez les résultats dans un fichier CSV indiquant le numéro de segment, le timestamp, le texte et la prédiction de l’émotion.
Cette approche vise à synchroniser le texte prononcé avec la manière dont il est articulé, afin de prédire l’émotion correspondante.
Analyse des segments audios concaténés
Une seconde approche consiste à utiliser une fenêtre “glissante”, en regroupant trois segments consécutifs (3 = un choix arbitraire). Il aurait été intéressant d’explorer d’autres combinaisons, mais cela reste un test offrant une perspective différente.
Comme pour l’analyse des segments basés sur le timestamp du texte, les résultats de l’analyse des segments “concaténés” sont également enregistrés dans un fichier CSV.

Pour chaque analyse, les segments audio sont découpés en fichiers individuels que vous pouvez réécouter. L’extraction du texte est effectuée à l’aide de la bibliothèque Whisper.
Whisper génère des transcriptions avec des timestamps, ce qui permet de découper l’audio de manière parfaitement alignée avec le texte.
# Concaténer des segments glissants
def concatenate_segments(segments, output_dir, sr=16000):
files = sorted([os.path.join(segments_save_path, f) for f in os.listdir(segments_save_path) if f.endswith('.wav')])
concat_segments = []
for i in range(len(files) - 2): # Combinaisons glissantes par 3
combined_audio = []
combined_text = []
for j in range(3): # Rassembler 3 segments
audio, _ = librosa.load(files[i + j], sr=sr)
combined_audio.extend(audio)
combined_text.append(segments[i + j]["text"])
output_path = os.path.join(output_dir, f"concat_segment_{i+1}.wav")
sf.write(output_path, np.array(combined_audio), sr)
concat_segments.append({
"path": output_path,
"text": " ".join(combined_text)
})
print(f"Segments concaténés sauvegardés dans : {output_dir}")
return concat_segments
Modifier le “pas” pour les combinaisons glissantes
Le “pas” dans la fonction concatenate_segments correspond au nombre de segments utilisés pour chaque concaténation. Voici les lignes à modifier :
for i in range(len(files) - 2): # Combinaisons glissantes par 3
Modifiez 3 pour changer le nombre de segments concaténés. Par exemple, pour concaténer 2 segments, remplacez - 2 par - 1. Ensuite, changez la valeur 3 pour correspondre au nouveau nombre de segments.
Dans notre exemple : 2
for j in range(3): # Rassembler 3 segments
Réflexion
L’analyse des émotions à partir de la voix s’avère être une des “couches” assez complexes à appréhender dans une démarche multimodale.
Cette exploration se voulait avant tout méthodologique, impliquant deux étapes majeures : d’une part, l’entraînement d’un modèle CNN spécifiquement conçu pour la reconnaissance des émotions vocales (Speech Emotion Recognition – SER), et d’autre part, la création d’un script permettant de tester différentes approches d’analyse temporelle de l’audio.
Le point central de cette expérimentation repose sur la question de la granularité. Découper la piste audio en segments synchronisés avec le texte ou concaténer des séquences glissantes offre des perspectives intéressantes. C’est précisément cette granularité qu’il faudra affiner pour avancer vers une véritable analyse multimodale, entre le texte, l’audio et l’image (synchronisée à 25 fps).
L’intégralité du script est partagé sur Google Colab.
[…] s’agit d’interactions ou de débats impliquant plusieurs personnes. On peux également analyser la voix avec des algorithmes de reconnaissance des émotions par l’audio (toutefois ces modèles sont entrainés sur la langue anglaise). Cette synchronisation permet […]
[…] ouvre naturellement la voie à une analyse multimodale plus large. En combinant simultanément le signal audio, le texte transcrit et les images extraites (par exemple, d’une vidéo), il devient possible […]