
En développant un script d’analyse des émotions avec le modèle FER2013 (Facial Emotion Recognition), une question s’est posée dès le départ : est-il vraiment nécessaire d’extraire et d’analyser toutes les images constituant une seconde de vidéo (soit 25 frames), ou peut-on se contenter d’une image par seconde pour accélérer le processus ?
Action ! Retour sur les bases du cinéma
Une seconde de vidéo étant composée de 25 images (frames), extraire chacune des « frames » pour les analyser demande des ressources considérables, surtout pour des vidéos longues.
Pour cette raison, dans mon précédent script où je teste le modèle FER-2013, j’ai d’abord opté pour une méthode plus simple : limiter l’extraction à une seule image par seconde (1 fps). C’était un premier test !
Dans cet article, je vais comparer les résultats de l’analyse des émotions entre l’extraction d’une image par seconde (1 fps) et l’extraction complète des 25 images par seconde (25 fps) constituant une seconde de vidéo.
Vous êtes impatient de tester ?! Le script est disponible sur mon compte GitHub.
Il est développé avec une interface Streamlit, donc à part installer les bibliothèques nécessaires et faire attention à bien installer FFmpeg (surtout pour les utilisateurs Mac), il vous suffira ensuite de lancer la commande suivante dans votre environnement Python : streamlit run main.py.
Attention ! Le script est actuellement opérationnel pour l’analyse d’une (seule) seconde de vidéo. Il évoluera en simplifiant certaines fonctions et en généralisant les calculs sur plusieurs secondes de vidéo.
Rappelons, que l’œil humain ne perçoit pas les 25 frames (25 fps) qui composent une seconde de vidéo ; il voit une image fluide, rendue possible par l’enregistrement vidéo à 25 fps.
Pour créer l’illusion du mouvement au cinéma (et en vidéo), on utilise des images fixes qui défilent rapidement. La norme aujourd’hui en Europe respecte une cadence de 24/25 images par seconde (i/s). Or, la majorité des films à l’époque étaient tournés (et projetés) en 16 ou 18 images par seconde.
Pendant la période du cinéma muet, il n’existait pas de norme concernant la cadence de prise de vue. Les caméras n’étaient pas encore équipées de moteurs permettant de faire avancer la pellicule de manière régulière. Le nombre d’images par seconde dépendait donc de la régularité et de la vitesse à laquelle l’opérateur actionnait la manivelle, à la fois lors de la prise de vue et lors de la projection.
La vidéo de référence pour le test
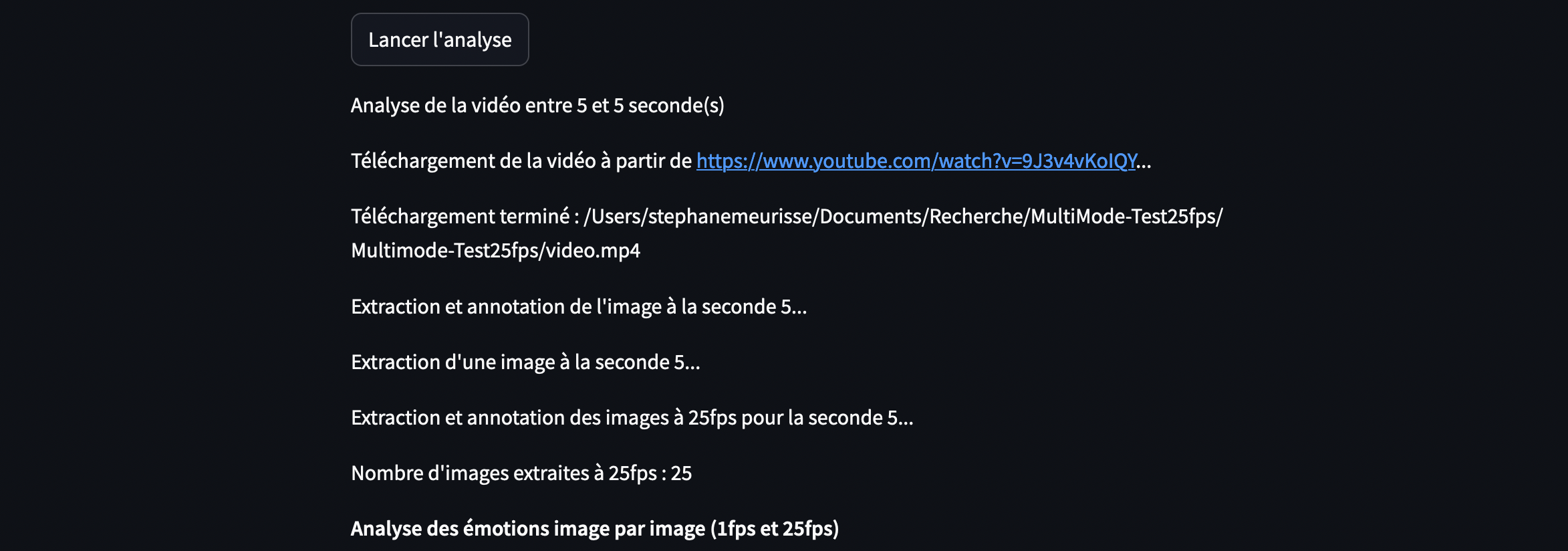
La vidéo est similaire au script précédent : il s’agit de 120 secondes d’un discours d’Emmanuel Macron sur le thème du harcèlement. Le script permettra d’extraire la seconde de votre choix pour l’analyser. Il comparera ensuite les scores des émotions obtenus à partir d’une exportation à 25 fps et à 1 fps.
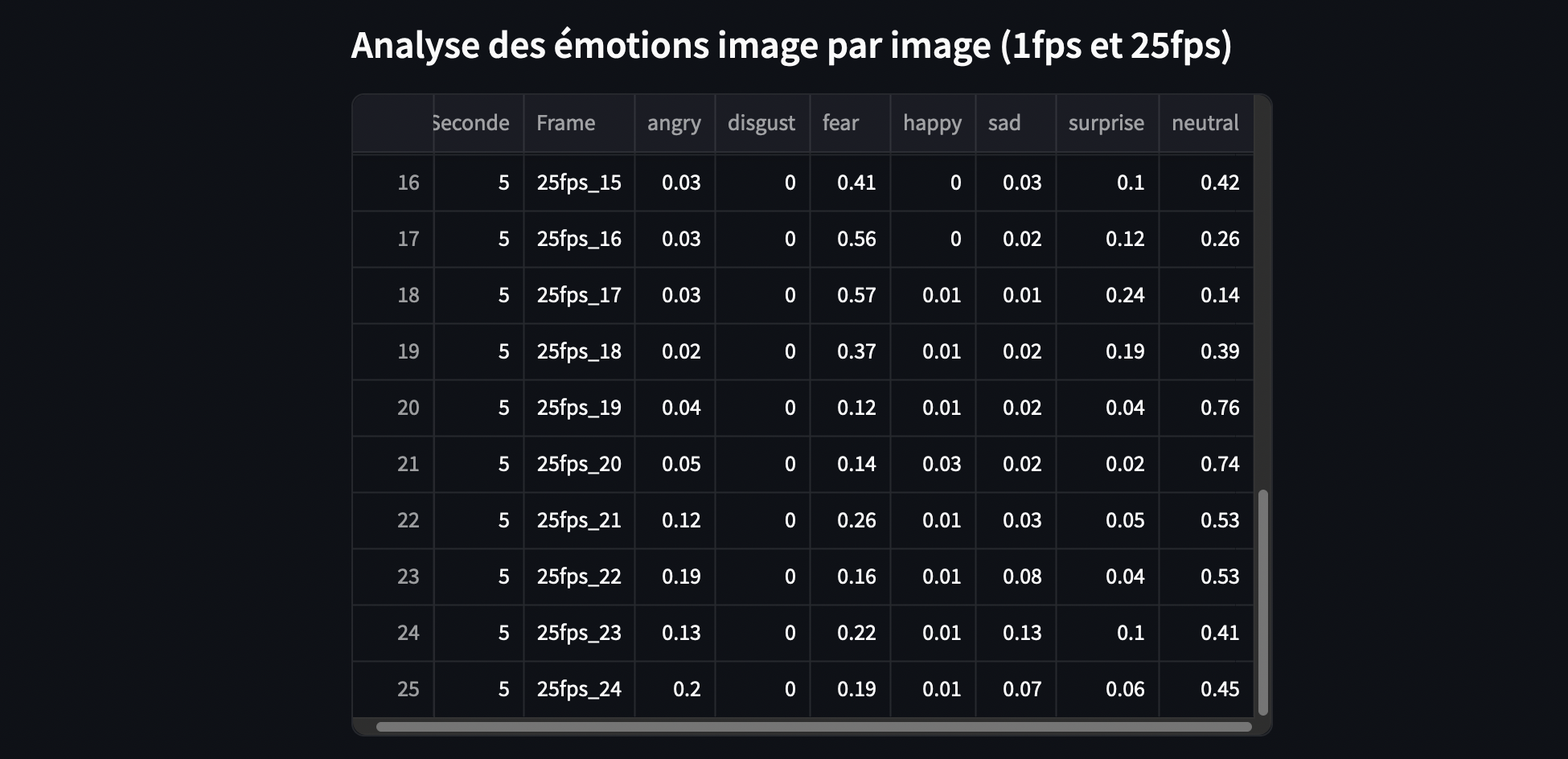
Ci-dessous les images de l’extraction de 1 seconde de vidéo composée de 25 frames.

























Existe-t-il une fonction automatique pour extraire l’émotion dominante dans FER ?
Le modèle FER (Facial Emotion Recognition) renvoie les probabilités associées à six émotions principales. En effet, chaque frame de la vidéo est associée à un ensemble de scores probabilistes pour chaque émotion (6), sans qu’une fonction unique et dédiée ne permette d’identifier automatiquement l’émotion dominante. Le modèle ne fait que renvoyer toutes les émotions avec leurs probabilités.
Sélectionner l’émotion dominante revient alors simplement à choisir celle avec le score le plus élevé parmi celles fournies par la fonction detect_emotions().
La fonction « autodetect » de FER prend la première frame de la séquence de 25 fps et analyse cette frame pour déterminer les émotions en retenant l’émotion avec le score le plus élevé (neutral : 0.65).

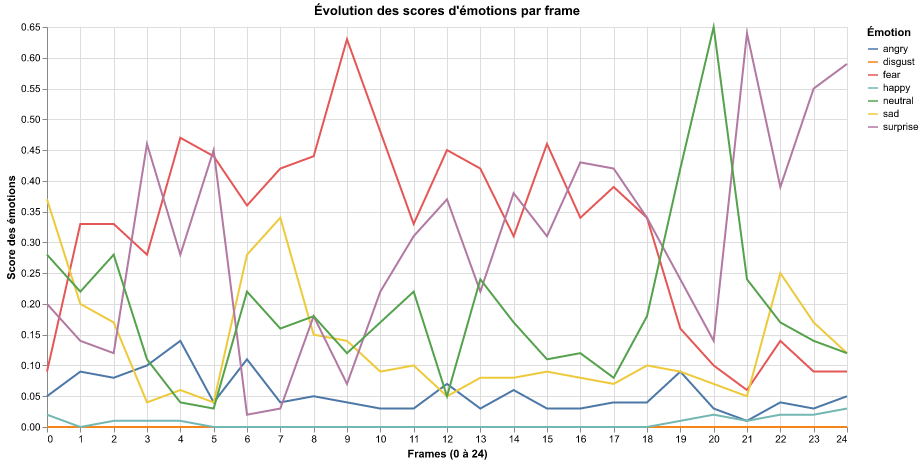
Il semble donc essentiel d’analyser toutes les frames lors de l’analyse pour être le plus précis. L’émotion perçue ne se limite pas à une seule image isolée (1 frame) : elle doit être évaluée sur l’ensemble des frames afin de prendre en compte les variations des scores probabilistes au fil du temps.
Faut-il toujours télécharger la vidéo YouTube et extraire les images ?
A ce jour je n’ai pas trouvé de système d’analyse en live (sauf dans le cas de la captation par webcam). Donc.. oui, pour une vidéo YouTube, il est nécessaire de télécharger la vidéo et d’extraire les frames si vous souhaitez analyser chaque image avec FER.
et sa fonction detect_emotions().
Pour les vidéos en streaming (flux direct, ex : webcam), FER travaille directement sur le flux d’images. Mais pour avoir testé le rendu n’est pas franchement exploitable.
Imposer au script d’extraire 25 fps
La fonction du script extraire_images_25fps_ffmpeg est conçue pour extraire 25 images dans une seconde de vidéo.
# Fonction pour extraire 25 images dans une seconde en utilisant FFmpeg
def extraire_images_25fps_ffmpeg(video_path, repertoire, seconde):
images_extraites = []
for frame in range(25):
image_path = os.path.join(repertoire, f"image_25fps_{seconde}_{frame}.jpg")
if os.path.exists(image_path):
images_extraites.append(image_path)
continue
time = seconde + frame * (1 / 25) # Calcul du temps pour chaque image (chaque image à 1/25 de seconde)
cmd = ['ffmpeg', '-ss', str(time), '-i', video_path, '-frames:v', '1', '-q:v', '2', image_path]
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if result.returncode != 0:
st.write(f"Erreur FFmpeg à {time} seconde : {result.stderr.decode('utf-8')}")
break
images_extraites.append(image_path)
st.write(f"Nombre d'images extraites à 25fps : {len(images_extraites)}")
return images_extraites
Explication du calcul pour extraire les 25 images par seconde (25 fps) :
time = seconde + frame * (1 / 25) # Calcul du temps pour chaque image (chaque image à 1/25 de seconde)
- seconde : C’est le point de départ dans la vidéo à partir duquel vous souhaitez extraire les images. Par exemple, si vous voulez commencer à partir de la 5e seconde, il faut définir dans l’interface « 5 ».

- frame : C’est l’index de l’image que vous voulez extraire dans cette seconde (la seconde « 5 » dans notre exemple). Le script va parcourir les images de 0 à 24 (donc 25 images au total) pour capturer chaque « frame » de cette seconde.
- (1 / 25) : Cela correspond à l’intervalle de temps entre deux images successives dans une vidéo à 25 images par seconde. Chaque image est donc espacée de 1/25 de seconde, soit 0,04 seconde.
- seconde + frame * (1 / 25) : Cette formule calcule le moment précis dans la vidéo auquel chaque image doit être extraite, en ajoutant l’intervalle (0,04 seconde) pour chaque frame.
Voici la décomposition :
- Pour la première image (quand
frame = 0),time = seconde + 0 * (1 / 25) = seconde - Pour la deuxième image (quand
frame = 1),time = seconde + 1 * (1 / 25) = seconde + 0.04(soit 1/25ème de seconde après la seconde spécifiée). - Pour la troisième image (quand
frame = 2),time = seconde + 2 * (1 / 25) = seconde + 0.08 - et ainsi de suite jusqu’à la frame 24
Voici les résultats des calculs pour extraire 25 images à partir de la 5e seconde de la vidéo :
-
- frame = 0, l’image sera extraite à 5.00 secondes.
- frame = 1, l’image sera extraite à 5.04 secondes.
- frame = 2, l’image sera extraite à 5.08 secondes.
- frame = 3, l’image sera extraite à 5.12 secondes.
- frame = 4, l’image sera extraite à 5.16 secondes.
- frame = 5, l’image sera extraite à 5.20 secondes.
- frame = 6, l’image sera extraite à 5.24 secondes.
- frame = 7, l’image sera extraite à 5.28 secondes.
- frame = 8, l’image sera extraite à 5.32 secondes.
- frame = 9, l’image sera extraite à 5.36 secondes.
- frame = 10, l’image sera extraite à 5.40 secondes.
- frame = 11, l’image sera extraite à 5.44 secondes.
- frame = 12, l’image sera extraite à 5.48 secondes.
- frame = 13, l’image sera extraite à 5.52 secondes.
- frame = 14, l’image sera extraite à 5.56 secondes.
- frame = 15, l’image sera extraite à 5.60 secondes.
- frame = 16, l’image sera extraite à 5.64 secondes.
- frame = 17, l’image sera extraite à 5.68 secondes.
- frame = 18, l’image sera extraite à 5.72 secondes.
- frame = 19, l’image sera extraite à 5.76 secondes.
- frame = 20, l’image sera extraite à 5.80 secondes.
- frame = 21, l’image sera extraite à 5.84 secondes.
- frame = 22, l’image sera extraite à 5.88 secondes.
- frame = 23, l’image sera extraite à 5.92 secondes.
- frame = 24, l’image sera extraite à 5.96 secondes.
Gestion du cache et des répertoires d’images
L’interface Streamlit complique un peu le développement et peut parfois provoquer des bugs…
Vous trouverez l’appel à la fonction de nettoyage de la mémoire cache de Streamlit à plusieurs endroits dans le script.
D’abord, elle est exécutée au démarrage de l’application, lorsque vous lancez la commande streamlit run main.py depuis votre terminal Python.
# Fonction pour vider le cache
def vider_cache():
st.cache_data.clear()
st.write("Cache vidé systématiquement au lancement du script")
# Appeler la fonction de vidage du cache au début du script
vider_cache()
Ensuite, à chaque clic sur « Lancer l’analyse », le cache est à nouveau nettoyé. Cela garantit que le cache est vidé avant chaque nouvelle analyse, évitant ainsi que des valeurs précédemment stockées dans les dictionnaires ne restent en mémoire et faussent les résultats.
De plus, pour éviter tout problème lors du redémarrage (re–lancer l’analyse) d’une nouvelle analyse, les répertoires contenant les images sont supprimés puis recréés automatiquement. Vous pouvez également supprimer manuellement l’ensemble des répertoires/fichiers avant de relancer une analyse.
Les résultats et les différentes mesures
Les « frames » sont extraites ! Maintenant, comment allons-nous comparer la différence entre 1 fps et 25 fps ?
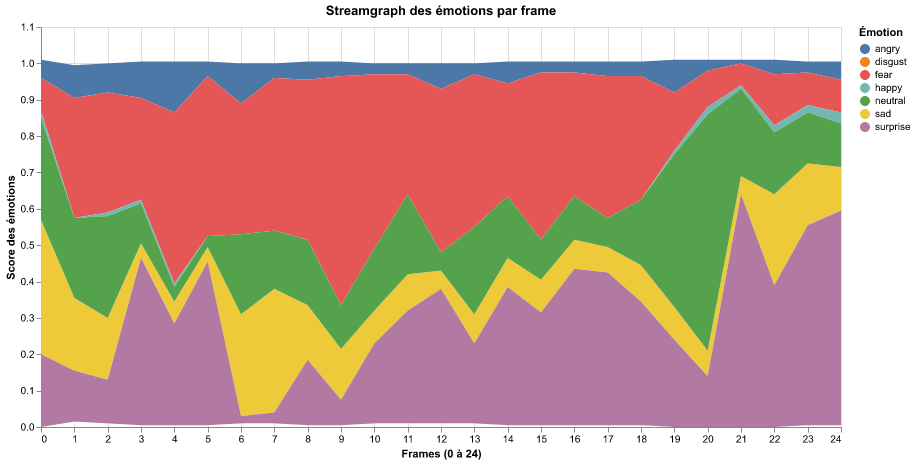
Comme on pouvait s’y attendre, les résultats varient.
Résultat pour l’extraction d’une seule frame (1 fps)
À ce stade, j’ai fait une petite erreur méthodologique (!) en demandant au script d’extraire une image de la seconde analysée. Le script a alors extrait la première frame des 25.
Il aurait été plus pertinent de choisir la 12e ou la 13e frame, plus représentative de la seconde complète.
Pour l’extraction de 1 fps, l’émotion dominante retournée est « neutral » avec une probabilité de 0,62.
La fonction native du script retient la probabilité la plus élevée de toutes les émotions. l’analyse de la première frame (1 fps) donne comme émotion dominante « neutral », tandis que l’analyse complète des 25 fps pour la même seconde indique « peur » (« fear »).

Résultat pour l’approche par la « somme » des 25 fps
Ici, nous avons pris en compte la somme des émotions présentes sur chaque frame, ce qui conduit à un résultat plutôt aberrant, car nous avons additionné des scores de probabilité… Additionner des probabilités n’est pas une méthode appropriée, car ces scores représentent des estimations indépendantes et non cumulatives. Cette mesure n’est pas à retenir même si le résultat obtenu concorde avec la mesure « moyenne » et le « mode ».

Vous pouvez déterminer l’émotion avec le score le plus élevé pour l’analyse d’une seule frame (1 fps), mais pour une séquence de frames, il est préférable de choisir une autre méthode.
Résultat pour l’approche par la « moyenne » des 25 frames
L’approche consistant à prendre la moyenne des scores sur plusieurs frames semble être la méthode la plus cohérente. Quoi qu’il en soit, l’émotion dominante qui ressort ici est la « peur » (« fear -> 0.4128 »).

Résultat pour l’approche par le « mode » des 25 fps
Le mode retient l’émotion la plus fréquente. Pour chaque frame, on va chercher l’émotion avec le score le plus élevé.

Dynamique émotionnelle : La variance comme indicateur de cohérence
Si on calcule la variance pour une seule émotion sur l’ensemble des 25 frames, cela peut nous dire à quel point la probabilité de cette émotion varie. Une faible variance pourrait indiquer une stabilité, mais cela ne signifie pas forcément qu’elle est l’émotion « dominante ». Par exemple, si l’émotion « joie » est tout le temps présente avec une faible probabilité, la variance pourrait être faible, mais cela ne fait pas de la « joie » une émotion prédominante dans cette séquence.
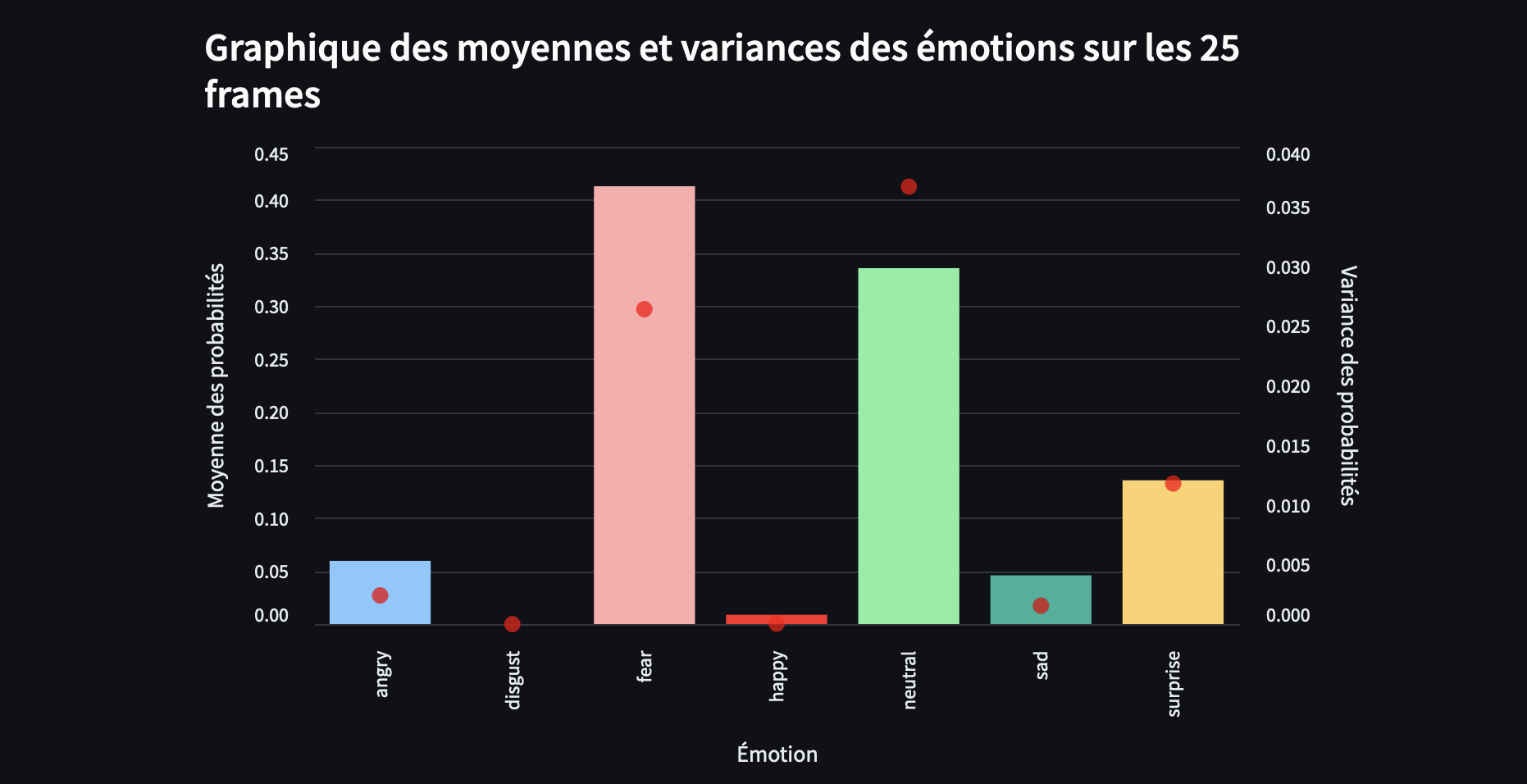
Pour comprendre la dynamique émotionnelle de la seconde entière composée de 25 fps, il est plus pertinent de comparer les variances des différentes émotions entre elles. Cela permet d’observer non seulement quelle émotion a le score le plus élevé en moyenne, mais aussi laquelle varie le moins ou le plus sur la période analysée.
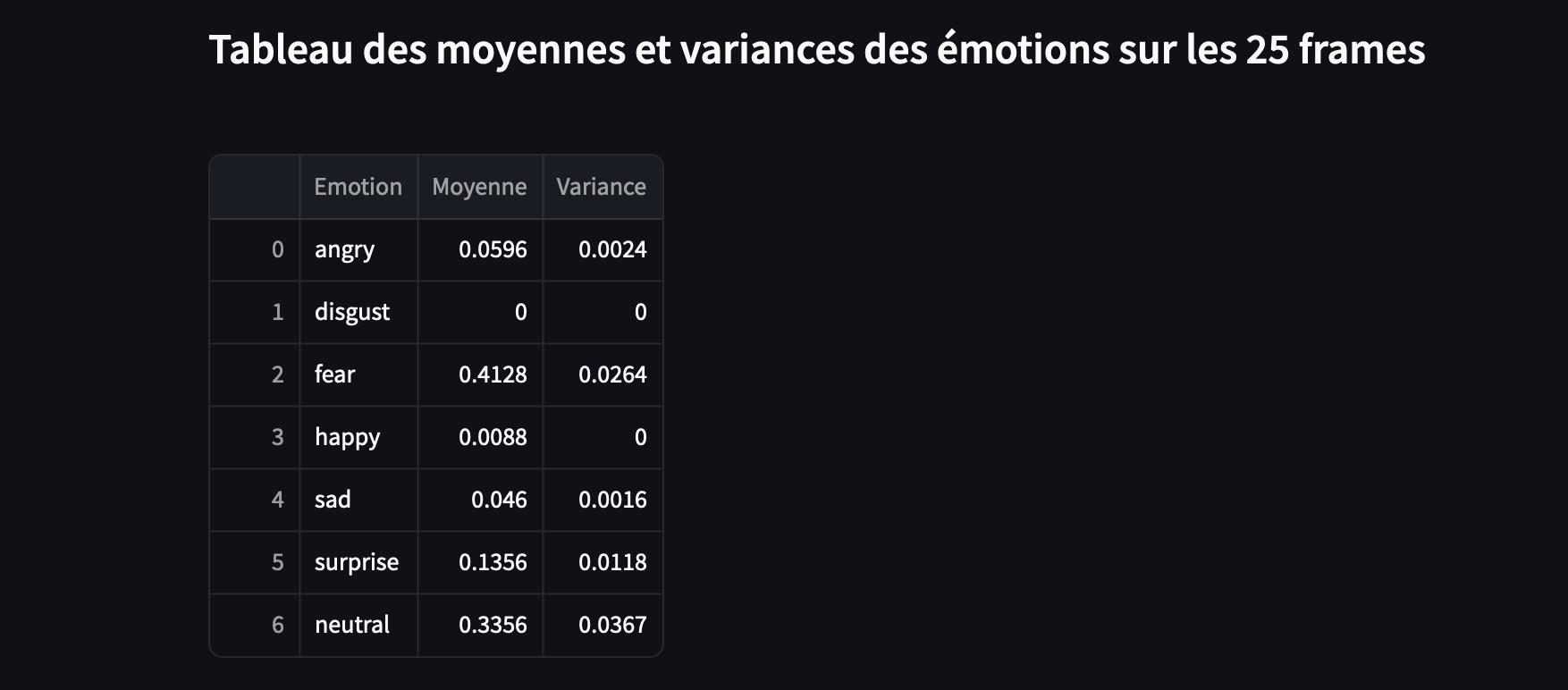
Cela donne un aperçu de la stabilité d’une émotion tout au long de la seconde.
Perspectives
On ne pourra pas se passer de l’extraction des 25 fps. On le voit, ces 25 fps apportent plus de nuances dans la détection des émotions, et il serait dommage de s’en priver. Les trois mesures (somme, moyenne, mode) offrent, dans notre exemple, une analyse similaire de l’émotion. L’approche que je recommande donc est d’utiliser le « vecteur complet des probabilités » pour chaque émotion plutôt que de simplement déterminer l’émotion dominante.
Cet article prend une forme hybride entre test, démonstration et perspective de mesure. Il constitue une étape dans un projet plus ambitieux autour de l’approche multimodale, telle que la synchronisation de l’analyse de l’image avec celle du texte et de la recherche d’une « mesure ».
De nombreuses étapes et questions restent à aborder. En effet, pour l’instant, nous avons utilisé la librairie FER – 2013 « classique », mais son dataset commence à dater… Il sera donc nécessaire de rédiger un article comparatif des différentes librairies d’analyse des émotions faciales et de leurs datasets avant d’entamer pleinement cette approche multimodale. De plus, une question technique importante portera sur la granularité de la synchronisation entre le texte et l’image. Il s’agira de déterminer à quel niveau de précision cette synchronisation doit être effectuée : doit-elle se faire au niveau du segment de texte, de plusieurs segments de texte, ou bien à une échelle plus fine, comme celle des mots ou des expressions spécifiques ?
[…] « vecteurs émotionnels » à travers des vidéos. Ce script a été testé sur deux discours : le premier, celui d’Emmanuel Macron sur le harcèlement, et le second, une intervention du Premier ministre Michel Barnier (résumé). La deuxième vidéo […]
[…] un affichage des émotions très dynamique, et donc assez difficile à lire à l’écran. Comme vu précédemment, il serait intéressant de moyenner le score des émotions chaque seconde. Dans notre cas, nous allons analyser toutes les trames, au risque de faire chauffer la machine ! Ne […]