X est devenu le repaire de la désinformation… Alors que Facebook ou Linkedin imposent une API payante pour récupérer leurs posts, il nous reste donc une source – certes également sujette à la désinformation, mais où l’expression demeure spontanée et authentique – celle des commentaires YouTube.
Il faut bien l’avouer : certaines vidéos suscitent une avalanche de réactions !
Merci donc à Google qui, via son API (gratuite jusqu’à un certain quota), permet d’extraire (je n’ose pas dire « scraper ») – les commentaires de YouTube.
J’ai décidé de reprendre ce script et de le développer sur Streamlit Cloud pour le rendre accessible en « no-code » !
Vous pouvez le tester en local en intégrant le code source ci-dessous ou directement sur le cloud de Streamlit grâce à cette URL :
https://scraper-commentaires-youtube.streamlit.app/
Les librairies à installer
Si vous exécutez le script en local, il vous faudra installer les librairies requises.
En revanche, en accédant à l’URL https://scraper-commentaires-youtube.streamlit.app/, vous bénéficiez d’une solution entièrement « no-code », sans installation préalable.
Notez cependant que l’application sur Streamlit Cloud peut nécessiter quelques secondes d’attente lors de votre connexion, car elle est souvent en veille et se réactive automatiquement.
pip install streamlit google-api-python-client
Vérification du nombre de commentaires extraits
Contrairement à certaines techniques de scraping qui nécessitent de faire défiler la page pour charger dynamiquement le contenu, notre script n’a pas besoin de simuler ce comportement.
Attention toutefois à bien vérifier le nombre de commentaires extraits. Il est possible que le décompte ne corresponde pas toujours à celui affiché par YouTube.

La différence peut s’expliquer par plusieurs facteurs. Bien que YouTube affiche un nombre total de commentaires, l’API ne renvoie que ceux qui sont publiquement accessibles et non modérés.
Certains commentaires, notamment ceux qui ont été signalés ou supprimés pour modération, ne sont donc pas inclus dans l’extraction.

Par conséquent, vérifiez régulièrement que le nombre de commentaires extraits correspond bien au nombre indiqué sur YouTube.
Exécution du code source
Vous pouvez l’exécuter depuis votre éditeur de code (à condition d’avoir installé les librairies requises et d’avoir généré une clé API Google YouTube) ou bien lancer directement l’application depuis l’url : https://scraper-commentaires-youtube.streamlit.app/ .
import re
import streamlit as st
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from datetime import datetime
# Titre et explication de l'application
st.title("Interface de scraping de commentaires YouTube")
st.markdown(
"Cette application permet de scraper les commentaires d'une vidéo YouTube. "
"Vous devez renseigner votre clé API Google, l'URL de la vidéo, et choisir les options de nettoyage du texte. "
"Plus d'infos : [codeandcortex.fr](https://codeandcortex.fr)."
)
# Champs de saisie pour les paramètres
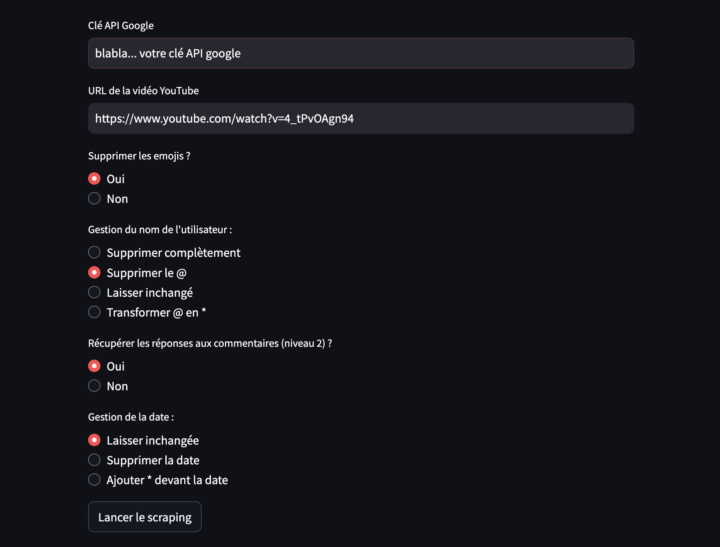
api_key = st.text_input("Clé API Google", placeholder="Entrez votre clé API YouTube ici")
url_video = st.text_input("URL de la vidéo YouTube", placeholder="https://youtube.com/shorts/...")
option_supprimer_emoji = st.radio("Supprimer les emojis ?", options=["Oui", "Non"], index=0)
option_nom_utilisateur = st.radio(
"Gestion du nom de l'utilisateur :",
options=["Supprimer complètement", "Supprimer le @", "Laisser inchangé", "Transformer @ en *"],
index=1
)
option_recuperer_reponses = st.radio("Récupérer les réponses aux commentaires (niveau 2) ?", options=["Oui", "Non"],
index=0)
option_date = st.radio(
"Gestion de la date :",
options=["Laisser inchangée", "Supprimer la date", "Ajouter * devant la date"],
index=0
)
# Lorsque l'utilisateur clique sur le bouton de lancement
if st.button("Lancer le scraping"):
# Vérification que les champs obligatoires sont remplis
if not api_key or not url_video:
st.error("Veuillez renseigner la clé API et l'URL de la vidéo.")
else:
# Extraction de l'ID de la vidéo à partir de l'URL (compatible YouTube et YouTube Shorts)
match = re.search(r"((?<=[?&]v=)|(?<=/videos/)|(?<=/shorts/))([a-zA-Z0-9_-]+)", url_video)
if not match:
st.error("L'URL de la vidéo ne semble pas valide.")
else:
video_id = match.group(2)
# Initialisation du client YouTube API avec la clé fournie
youtube = build('youtube', 'v3', developerKey=api_key)
# Fonction pour supprimer les emojis si l'option est activée
def supprimer_emojis(texte):
if option_supprimer_emoji == "Oui":
motif_emoji = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symboles et pictogrammes
u"\U0001F680-\U0001F6FF" # transport et symboles de carte
u"\U0001F700-\U0001F77F" # symboles alchimiques
u"\U0001F780-\U0001F7FF" # formes géométriques étendues
u"\U0001F800-\U0001F8FF" # flèches supplémentaires-C
u"\U0001F900-\U0001F9FF" # symboles et pictogrammes supplémentaires
u"\U0001FA00-\U0001FA6F" # symboles d'échecs
u"\U0001FA70-\U0001FAFF" # symboles et pictogrammes étendus-A
u"\U00002702-\U000027B0" # dingbats
u"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE)
return motif_emoji.sub(r'', texte)
else:
return texte
# Fonction pour récupérer les détails de la vidéo
def obtenir_details_video(video_id):
try:
reponse = youtube.videos().list(
part="snippet",
id=video_id
).execute()
except HttpError as e:
st.error(f"Une erreur HTTP {e.resp.status} est survenue:\n{e.content}")
return None, None
if not reponse['items']:
return None, None
details = reponse['items'][0]['snippet']
titre = supprimer_emojis(details['title'])
date_publication = details['publishedAt']
return titre, date_publication
# Fonction pour récupérer le nom de la chaîne YouTube
def recuperer_nom_chaine(video_id):
try:
reponse = youtube.videos().list(
part="snippet",
id=video_id
).execute()
except HttpError as e:
st.error(f"Une erreur HTTP {e.resp.status} est survenue:\n{e.content}")
return None
if not reponse['items']:
return None
nom_chaine = reponse['items'][0]['snippet']['channelTitle']
return nom_chaine
# Fonction pour récupérer les commentaires de la vidéo
def recuperer_commentaires(video_id, max_resultats=100):
commentaires = []
try:
reponse = youtube.commentThreads().list(
part="snippet",
videoId=video_id,
textFormat="plainText",
maxResults=max_resultats,
order="time" # Récupère les commentaires triés par date
).execute()
while reponse:
for item in reponse['items']:
# Récupérer le commentaire de niveau 1
commentaire = item['snippet']['topLevelComment']['snippet']['textDisplay']
commentaire = supprimer_emojis(commentaire).lower() # Nettoyage du texte
auteur = item['snippet']['topLevelComment']['snippet']['authorDisplayName']
# Gestion du nom de l'utilisateur
if option_nom_utilisateur == "Supprimer complètement":
auteur = ""
elif option_nom_utilisateur == "Supprimer le @":
auteur = auteur.replace("@", "")
elif option_nom_utilisateur == "Transformer @ en *":
auteur = auteur.replace("@", "*")
# Gestion de la date
date_publication = item['snippet']['topLevelComment']['snippet']['publishedAt']
date_pub = datetime.strptime(date_publication, '%Y-%m-%dT%H:%M:%SZ').date()
if option_date == "Laisser inchangée":
ligne = f'{auteur} - {date_pub}\n{commentaire}\n\n'
elif option_date == "Ajouter * devant la date":
# Suppression du tiret ici
ligne = f'{auteur} *{date_pub}\n{commentaire}\n\n'
elif option_date == "Supprimer la date":
ligne = f'{auteur}\n{commentaire}\n\n'
commentaires.append(ligne)
# Récupérer les réponses aux commentaires (niveau 2) si l'option est activée
if option_recuperer_reponses == "Oui":
try:
reponse_reponses = youtube.comments().list(
part="snippet",
parentId=item['id'],
textFormat="plainText"
).execute()
for rep in reponse_reponses.get('items', []):
commentaire_rep = rep['snippet']['textDisplay']
commentaire_rep = supprimer_emojis(commentaire_rep).lower()
auteur_rep = rep['snippet']['authorDisplayName']
if option_nom_utilisateur == "Supprimer complètement":
auteur_rep = ""
elif option_nom_utilisateur == "Supprimer le @":
auteur_rep = auteur_rep.replace("@", "")
elif option_nom_utilisateur == "Transformer @ en *":
auteur_rep = auteur_rep.replace("@", "*")
date_publication_rep = rep['snippet']['publishedAt']
date_pub_rep = datetime.strptime(date_publication_rep,
'%Y-%m-%dT%H:%M:%SZ').date()
if option_date == "Laisser inchangée":
ligne_rep = f'Reponse : {auteur_rep} - {date_pub_rep}\n{commentaire_rep}\n\n'
elif option_date == "Ajouter * devant la date":
ligne_rep = f'Reponse : {auteur_rep} *{date_pub_rep}\n{commentaire_rep}\n\n'
elif option_date == "Supprimer la date":
ligne_rep = f'Reponse : {auteur_rep}\n{commentaire_rep}\n\n'
commentaires.append(ligne_rep)
except HttpError as e:
st.error(
f"Une erreur HTTP {e.resp.status} est survenue lors de la récupération des réponses:\n{e.content}")
if 'nextPageToken' in reponse:
reponse = youtube.commentThreads().list(
part="snippet",
videoId=video_id,
pageToken=reponse['nextPageToken'],
textFormat="plainText",
maxResults=max_resultats
).execute()
else:
break
except HttpError as e:
st.error(f"Une erreur HTTP {e.resp.status} est survenue:\n{e.content}")
return commentaires
# Fonction pour générer le contenu du fichier texte
def generer_contenu_fichier(titre, date_publication, nom_chaine, commentaires):
contenu = ""
if option_date == "Laisser inchangée":
date_pub = datetime.strptime(date_publication, '%Y-%m-%dT%H:%M:%SZ').date()
contenu += f'Chaîne : {nom_chaine}\nTitre : {titre.strip()} - {date_pub.strftime("%d-%m-%Y")}\n\n'
elif option_date == "Ajouter * devant la date":
date_pub = datetime.strptime(date_publication, '%Y-%m-%dT%H:%M:%SZ').date()
contenu += f'Chaîne : {nom_chaine}\nTitre : {titre.strip()} *{date_pub.strftime("%d-%m-%Y")}\n\n'
elif option_date == "Supprimer la date":
contenu += f'Chaîne : {nom_chaine}\nTitre : {titre.strip()}\n\n'
contenu += "Commentaires:\n\n"
for c in commentaires:
contenu += c
return contenu
# Récupération des détails de la vidéo et du nom de la chaîne
titre_video, date_video = obtenir_details_video(video_id)
nom_chaine = recuperer_nom_chaine(video_id)
if titre_video is None or date_video is None or nom_chaine is None:
st.error("Échec de récupération des détails de la vidéo.")
else:
# Récupération des commentaires de la vidéo
commentaires = recuperer_commentaires(video_id)
contenu_fichier = generer_contenu_fichier(titre_video, date_video, nom_chaine, commentaires)
# Afficher un message de succès et le nombre de commentaires
st.success(f"{len(commentaires)} commentaires ont été enregistrés.")
# Bouton pour télécharger le fichier
st.download_button(
label="Télécharger le fichier",
data=contenu_fichier,
file_name="youtube_comments.txt",
mime="text/plain"
)