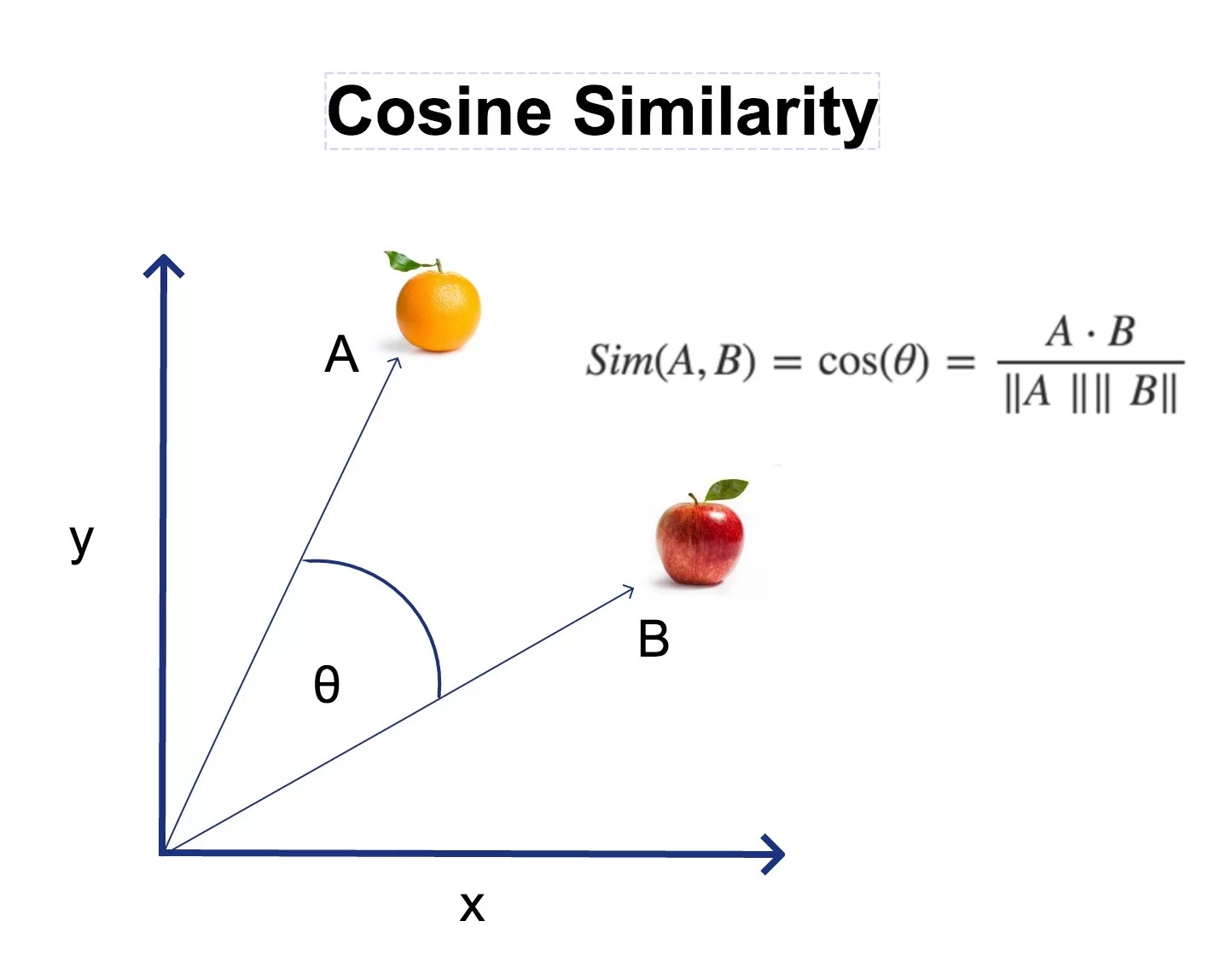
Parmi les nombreuses approches utilisées dans le traitement du langage naturel (NLP – Natural Language Processing), la mesure de la similarité cosinus permet de comparer des mots en fonction de leur proximité dans un espace vectoriel.
Le script ci-dessous a été conçu avec un corpus test, issu d’articles récupérés via Europresse et formaté pour être compatible avec le logiciel IRaMuTEQ. Par conséquent, il inclut une série de prétraitements spécifiques, notamment la structuration des articles à l’aide de balises d’identification (**** *variable1 *variable2). Il est important de noter que ce script ne vise pas à démontrer quoi que ce soit. Son objectif est d’explorer une méthode couramment utilisée par les moteurs de recherche pour le classement des documents sur Internet.
Dans cet article, nous nous intéressons uniquement à la mise en œuvre technique de ce test, sans prétention d’interprétation ou de validation théorique des résultats obtenus.
Le test de similarité cosinus permet de mesurer la proximité lexicale entre les mots d’un texte donné. Il représente une perspective de fouille de texte permettant d’explorer des relations entre les termes les plus fréquents d’un corpus.
Test d’indépendance vs similarité lexicale
Un test d’indépendance en statistiques vise à déterminer si deux variables sont liées ou non. Par exemple, le test du Khi2 est souvent utilisé pour vérifier si deux catégories de données sont indépendantes dans un échantillon. En revanche, le test de similarité cosinus n’évalue pas l’indépendance statistique des mots mais mesure leur proximité dans un espace vectoriel. La similarité cosinus, évalue l’angle entre deux vecteurs représentant des mots. Plus cet angle est petit, plus les mots sont jugés “similaires”, par extension on peut dire qu’ils appartiennent à un même univers lexical.
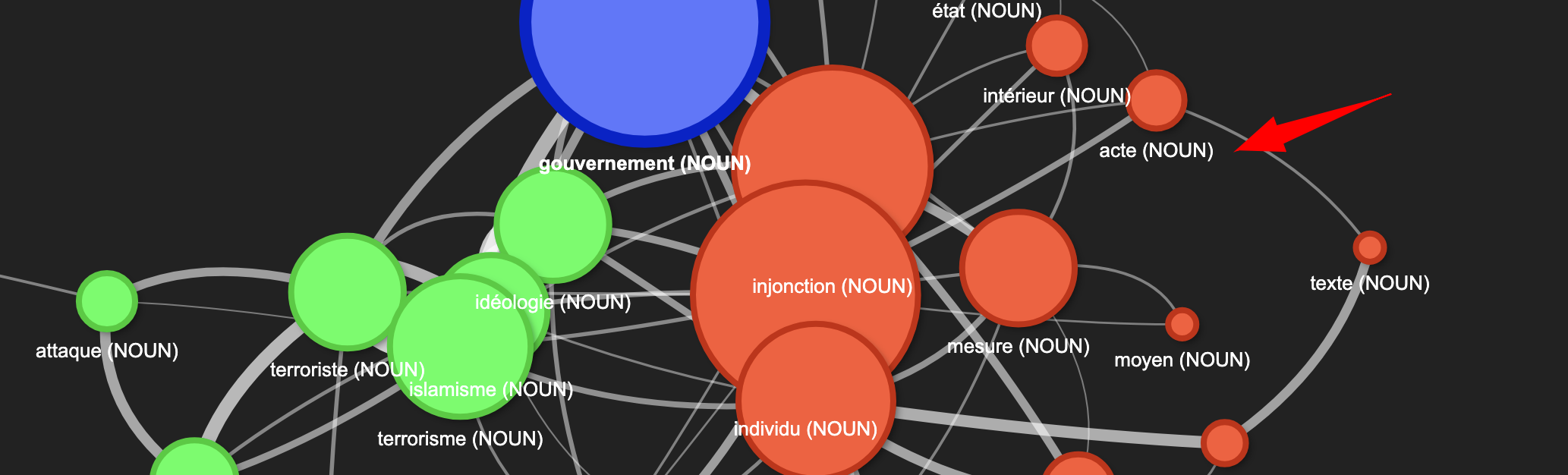
Autre point de discussion, la librairie SpaCy amène une certaine ambiguïté dans la reconnaissance de certains mots qui peuvent être à la fois des noms et des verbes. Par exemple, le terme “pouvoir” peut poser problème dans notre cas.
Notre corpus est composé d’articles de presse traitant à la fois du terrorisme et de la question de la prise en charge des patients fichés “S” ayant commis un passage à l’acte. Ces articles s’inscrivent dans un contexte marqué par la déclaration très polémique de Gérald Darmanin, affirmant “qu’il y a eu un ratage psychiatrique” après qu’un patient suivi en soins psychiatriques ait été impliqué dans un acte violent.
Pourquoi le mot “pouvoir” pose problème ? Si on se réfère à l’ouvrage “Le pouvoir psychiatrique” de Michel Foucault (Cours du Collège de France), ici le “pouvoir” désigne un concept théorique et institutionnel. Ainsi selon l’approche historique la psychiatrie (serait) au service du pouvoir. Mais ici SpaCy pourrait l’interpréter comme le verbe “pouvoir”. Cette confusion peut entraîner de gros biais dans l’analyse.
Une solution pour éviter ce biais consiste à exclure les verbes (?) de l’analyse ou à filtrer.
Une autre solution (utilisé dans le script) consiste à afficher le POS TAGS (part-of-speech) à coté du terme (entre parenthèse). Malgré tout cela induit certaines limitations, notamment dans la classification des noms propres. Par exemple, “Paris” est ici reconnu comme un nom (NOUN) mais n’est pas identifié comme une entité géographique…
1. Chargement et prétraitement du texte
La première étape consiste à charger le modèle “large = lg” de SpaCy qui intègre des vecteurs sémantiques pour la langue française.
import spacy
nlp = spacy.load("fr_core_news_lg")
Ensuite, nous ouvrons et lisons le fichier texte contenant le corpus à analyser. Ce fichier est “normalisé” avec la conversion du corpus en “minuscules”.
# Charger le texte depuis le fichier et le normaliser
with open("/Users/stephanemeurisse/Documents/Recherche/similarite_cosinus/psychiatrie-darmanin-clean.txt", "r", encoding="utf-8") as f:
texte = f.read().lower().strip() # Passage en minuscule et suppression des espaces inutiles
Le texte est ensuite traité par SpaCy, segmenté en tokens et filtré pour ne conserver que les noms, verbes et noms propres. Nous éliminons également les stopwords et les tokens non alphabétiques pour ne garder que les mots significatifs.
doc = nlp(texte) extracted_terms = [token.lemma_ for token in doc if token.pos_ in ["NOUN", "VERB", "PROPN"] and not token.is_stop and token.is_alpha]
2. Sélection des termes les plus pertinents
Nous calculons la fréquence d’apparition des termes dans le texte, ce qui permet d’identifier les plus significatifs.
from collections import Counter term_frequencies = Counter(extracted_terms)
Parmi ces termes, nous vérifions lesquels possèdent un vecteur SpaCy valide, ce qui garantit qu’ils peuvent être comparés via la similarité cosinus.
valid_terms = {term: nlp(term).vector for term in most_common_terms if nlp(term).vector_norm > 0}
3. Calcul de la similarité cosinus et création du graphe
La similarité entre deux mots est calculée à l’aide de scipy.spatial.distance.cosine, qui retourne la distance cosinus entre deux vecteurs.
from scipy.spatial.distance import cosine
import itertools
import networkx as nx
similarity_threshold = 0.4 # Plus le seuil est bas, plus le graphe sera dense
graph = nx.Graph()
for term1, term2 in itertools.combinations(valid_terms.keys(), 2):
vec1, vec2 = valid_terms[term1], valid_terms[term2]
similarity = 1 - cosine(vec1, vec2)
if similarity >= similarity_threshold:
graph.add_edge(term1, term2, weight=float(similarity))
Nous supprimons ensuite les nœuds isolés, c’est-à-dire les mots qui ne sont pas suffisamment similaires à d’autres pour être connectés dans le graphe.
isolated_nodes = [node for node in graph.nodes() if graph.degree(node) == 0] graph.remove_nodes_from(isolated_nodes)
4. Paramètres : Seuil de similarité cosinus et nombre d’arêtes
Dans le script, l’utilisateur peut ajuster le seuil de similarité cosinus pour modifier le nombre de connexions entre les mots. Cette modification se fait via la variable suivante :
similarity_threshold = 0.4 # Plus le seuil est bas, plus le graphe sera dense
Ce paramètre contrôle le nombre d’arêtes (connexions) dans le graphe. Voici son effet :
- Si le seuil est bas (ex: 0.3 ou 0.2) : plus de mots seront connectés, ce qui crée un graphe plus dense, mais avec des liens parfois moins significatifs.
- Si le seuil est haut (ex: 0.6 ou 0.7) : seules les relations les plus fortes sont conservées, ce qui donne un graphe plus épuré, mais avec moins de connexions.
Si vous souhaitez tester plusieurs valeurs, modifiez la valeur de similarity_threshold et exécutez à nouveau le script.

Le script extrait par défaut trois catégories grammaticales du texte : les noms communs (NOUN), les verbes (VERB) : les noms propres (PROPN).
Mais SpaCy offre également la possibilité d’inclure d’autres catégories grammaticales dans l’analyse, telles que les adjectifs ("ADJ"), les adverbes ("ADV"), les pronoms ("PRON"), les déterminants ("DET"), les prépositions ("ADP"), les conjonctions ("CCONJ", "SCONJ"), les numéraux ("NUM") et les interjections ("INTJ").
# Extraction des termes importants (noms, verbes et noms propres uniquement, sans stopwords) extracted_terms = [token.lemma_ for token in doc if token.pos_ in ["NOUN", "VERB", "PROPN"] and not token.is_stop and token.is_alpha]
5. Détection des communautés lexicales
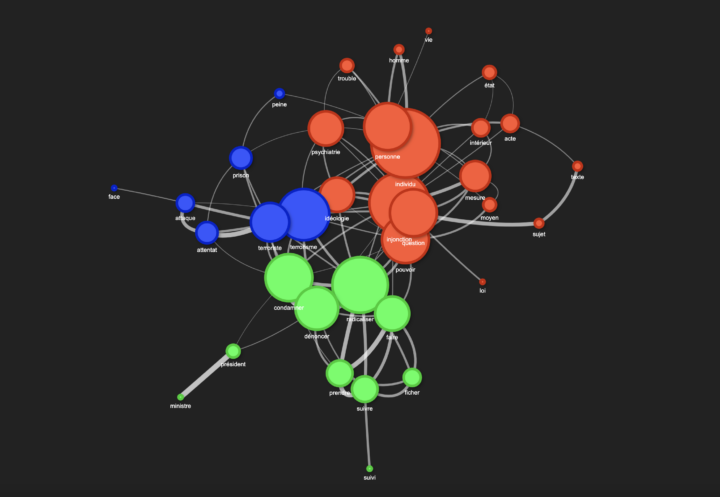
Une fois le graphe construit, nous appliquons un algorithme de détection de communautés basé sur la modularité (greedy modularity), qui regroupe les mots en fonction de leurs connexions.
from networkx.algorithms.community import greedy_modularity_communities communities = list(greedy_modularity_communities(graph))
Chaque communauté de mots est ensuite colorée pour une meilleure visualisation.
def generate_color_palette(n):
colors = ["#FF5733", "#33FF57", "#3357FF", "#FF33A8", "#A833FF", "#33FFF2", "#FF8C00", "#FFD700"]
return [colors[i % len(colors)] for i in range(n)]
community_colors = generate_color_palette(len(communities))
color_map = {}
for i, community in enumerate(communities):
for node in community:
color_map[node] = community_colors[i]
6. Visualisation interactive du graphe
Nous utilisons Pyvis, une bibliothèque permettant de créer des visualisations interactives de graphes, pour afficher les relations lexicales sous forme de réseau.
from pyvis.network import Network net = Network(notebook=False, height="800px", width="100%", bgcolor="#222222", font_color="white", directed=False)
Chaque nœud (mot) est ajouté avec une taille proportionnelle à son degré (nombre de connexions).
for node in graph.nodes():
net.add_node(
node,
size=graph.degree(node) * 5,
title=f"{node}: {term_frequencies.get(node, 0)} occurrences",
label=node,
color=color_map.get(node, "#FFFFFF"),
borderWidth=4,
shadow=True
)
Les liens (arêtes) sont ajoutés avec une transparence proportionnelle à la force de la relation lexicale.
for edge in graph.edges(data=True):
weight = edge[2]['weight']
net.add_edge(edge[0], edge[1], value=weight * 5, color=f"rgba(255, 255, 255, {weight})")
Des bulles de différentes couleurs
Les couleurs des nœuds dans le graphe ne sont pas aléatoires, elles reflètent les communautés détectées à l’aide de l’algorithme de modularité. Une communauté est un groupe de mots qui sont plus connectés entre eux qu’avec le reste du graphe. Cela signifie que les mots d’une même couleur sont jugés lexicalement proches les uns des autres selon la mesure de similarité cosinus.
Enfin, nous générons et sauvegardons le graphe sous forme de fichier HTML interactif.
# Générer et sauvegarder le graphe interactif
net.write_html("graph_similarité_cosinus.html")
print("Graphe de similarité cosinus généré : ouvrez 'graph_similarité_cosinus.html' dans votre navigateur.")
Perspectives
Maintenant que le script permet d’extraire efficacement les termes clés (NOUN, PROPN…), nous pourrons essayer de l’améliorer en intégrant de nouvelles analyses. Tout d’abord, l’application d’un test TF*IDF avant la similarité cosinus permettrait de renforcer la pertinence des mots comparés en éliminant les termes trop fréquents.
Ensuite, un test du Khi² pourrait être utilisé pour déterminer si les connexions observées entre les termes sont statistiquement significatives.
Une analyse des cooccurrences permettrait également de mieux comprendre les relations lexicales dans le corpus. Enfin, l’intégration de la similarité de Jaccard offrirait une autre perspective d’analyse, permettant une comparaison enrichissante avec les autres méthodes.