Dans le domaine des Sciences Humaines, le numérique offre de nouvelles opportunités en matière de collecte et d’analyse de données. En effet, au-delà des méthodes traditionnelles telles que l’entretien, le questionnaire, l’observation…, il est désormais possible d’exploiter des données issues de formats multimédias intégrant simultanément l’image, le son et le texte.
Il devient alors possible non seulement de retranscrire le texte, mais également d’analyser l’audio et les images, permettant ainsi une approche d’analyse que l’on pourrait qualifier de multimodale. J’entends par cette approche multimodale la possibilité de synchroniser ou superposer les pistes image / texte / audio.
Cette approche, un peu à la manière de l’anthropologue Gregory Bateson, permettrait d’explorer si le discours est en phase avec la communication non verbale, notamment les émotions faciales. En quelque sorte, la scène de l’enfant avec sa mère dans une rue de Bali, retranscrite grâce à la chronophotographie et à l’observation participante, est une première forme d’approche multimodale.
Dans cet article, je vais donc me focaliser sur un script qui permet d’effectuer une analyse des émotions à partir des visages — Face Emotion Recognition (FER). Nous sommes donc toujours dans une approche unimodale (?) et nous nous concentrons sur un algorithme pré-entraîné qui permet de “prédire” (c’est le terme employé en IA) les émotions à partir d’images.

L’approche repose sur une classification des émotions prédéfinie par la librairie FER-2013, qui répertorie 7 émotions principales : Angry (Colère), Disgust (Dégoût), Fear (Peur), Happy (Joie), Sad (Tristesse), Surprise (Surprise), Neutral (Neutre).
Cet article présente donc une première approche (un premier script), en se concentrant sur l’analyse des émotions à travers l’image, dans une démarche expérimentale visant à tester la pertinence de cette méthode.


L’avantage de ce script est qu’il ne nécessite pas un processus d’entraînement laborieux consistant à annoter manuellement les images avec les émotions correspondantes. Cela reste toutefois possible ! C’est le propre de l’IA “d’entraîner” un modèle en créant des annotations, labels, catégories ou classes (appelez cela comme vous voulez…).
Dans le cadre de la création d’un jeu de données pour la détection d’images et des émotions, vous pouvez vous appuyer sur l’interface Roboflow (non testée).
Les algorithmes de l’IA au service de la méthodologie SHS
Une problématique intéressante dans le champ des Sciences Humaines est celle de l’intégration des processus de traitement automatique du langage naturel (NLP) dans l’analyse textuelle. En effet, ces outils permettent d’ajouter une dimension supplémentaire aux traitements “classiques”, tels que l’analyse factorielle des correspondances (AFC) ou la méthode de classification hiérarchique descendante (CHD) de Max Reinert, couramment utilisée dans le logiciel IRaMuTEQ.
Un autre axe important est l’expérimentation avec des algorithmes d’apprentissage non supervisé, dans une perspective exploratoire et de construction de clusters (La notion de “cluster” fait référence aux algorithmes d’apprentissage non-supervisé), en exploitant des techniques issues du data mining. Par exemple, k-means, bien que classique, reste pertinent, mais c’est surtout l’algorithme LDA (Latent Dirichlet Allocation) qui se distingue par son efficacité pour reconstruire des clusters.
J’ai testé l’algorithme Latent Dirichlet Allocation sur un corpus de plus de 1000 articles Europresse “non nettoyé” et j’ai constaté qu’il parvenait à créer des clusters tout en isolant ceux qui étaient sans lien direct avec le thème de ma recherche (souvent des morceaux d’articles présents dans les éditoriaux), alors qu’un traitement manuel aurait probablement exclu ces articles (considéré comme hors sujet). LDA, quant à lui, les isole parfaitement.
Le troisième enjeu consiste à exploiter les supports numériques émergeant (YouTube, TikTok…) pour réaliser une approche “multimodale”, “synchronisée”, en superposant les pistes audio, texte et image dans une analyse plus globale.
Données d’entrainement du Dataset FER – 2013
Voici quelques détails sur cet ensemble de données : FER – Facial Emotion Recognition- 2013 a été entrainé avec environ 35 000 images. Cet ensemble de données comporte 7 catégories d’émotions : colère, dégoût, peur, joie, tristesse, surprise, et neutre. Les images sont réparties en ensembles d’entraînement (80%) et de test (20%°) pour l’apprentissage et l’évaluation du modèle.
On retrouve 7 catégories d’émotions et si vous souhaitez affiner ou entraîner le modèle, c’est possible ! L’émotion “neutre” me laisse perplexe… mais à défaut, je vais me servir du modèle pré-entraîné pour tester la méthode et élaborer le script.
Il est important de noter que le modèle associe des scores à chaque émotion. Ainsi, sauf dans des cas d’expressions très “forcées” ou “caricaturales”, vous n’obtiendrez pas un score unique pour une seule émotion. Cependant, il est possible de “trancher” en relevant le score le plus élevé pour définir l’émotion dominante. (La librairie DeepFace, que j’aborderai dans un prochain article, propose cette fonctionnalité nativement).
Choix de la vidéo pour tester le script
La vidéo d’Emmanuel Macron que j’ai utilisée pour tester mon script n’est peut-être pas la plus pertinente. Cependant, j’ai dû faire face à deux contraintes.
D’une part, il me fallait trouver une vidéo courte. Pour rappel, une vidéo en Europe est enregistrée à 25 images par seconde (30 images/s aux États-Unis et bien plus pour des séquences en ralenti, allant jusqu’à 120 voire 240 images par seconde).
En extrayant une image par seconde de la piste vidéo, cela donne déja beaucoup de données à traiter. Par exemple, pour une vidéo de 120 secondes, cela équivaut déjà à 120 images extraites, ce qui peut vite saturer les capacités de la machine.
De plus, j’ai sélectionné une vidéo où l’orateur est bien visible, seul face à la caméra, afin de faciliter la détection du visage et l’analyse des émotions.
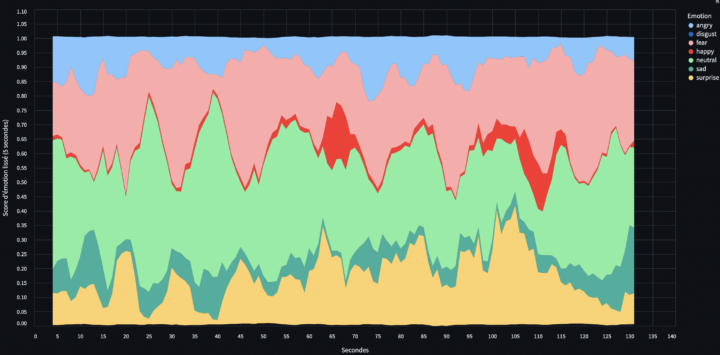
Enfin, dans cette vidéo, vous remarquerez qu’un sous-titrage est présent en bas, ce qui nous permet d’envisager une représentation graphique du script analysant les émotions moyennes sur cinq images successives (c’est-à-dire toutes les 5 secondes, ce qui correspond au temps moyen pour la prononciation d’une phrase dans ce contexte d’évocation).
Des tests seront réalisés ultérieurement afin d’analyser si une extraction plus fine (25 images par seconde) modifie les résultats d’analyse.
L’interface et les résultats
Le script permet, dans un premier temps, d’extraire une vidéo depuis YouTube. Vous pouvez extraire une vidéo classique ou un short. Je vous encourage à sélectionner une vidéo courte où le sujet est bien visible.
Dans un second temps, le script va extraire les images de la vidéo à raison d’une image par seconde.
C’est un bon début 😉 mais pour “capter” des émotions et rester dans la complexité, je regrette un peu ce choix…
Toutefois, le premier graphique (1 image / 1 seconde de vidéo) montre que sur une vidéo de 120 secondes, les résultats semblent difficiles à interpréter.
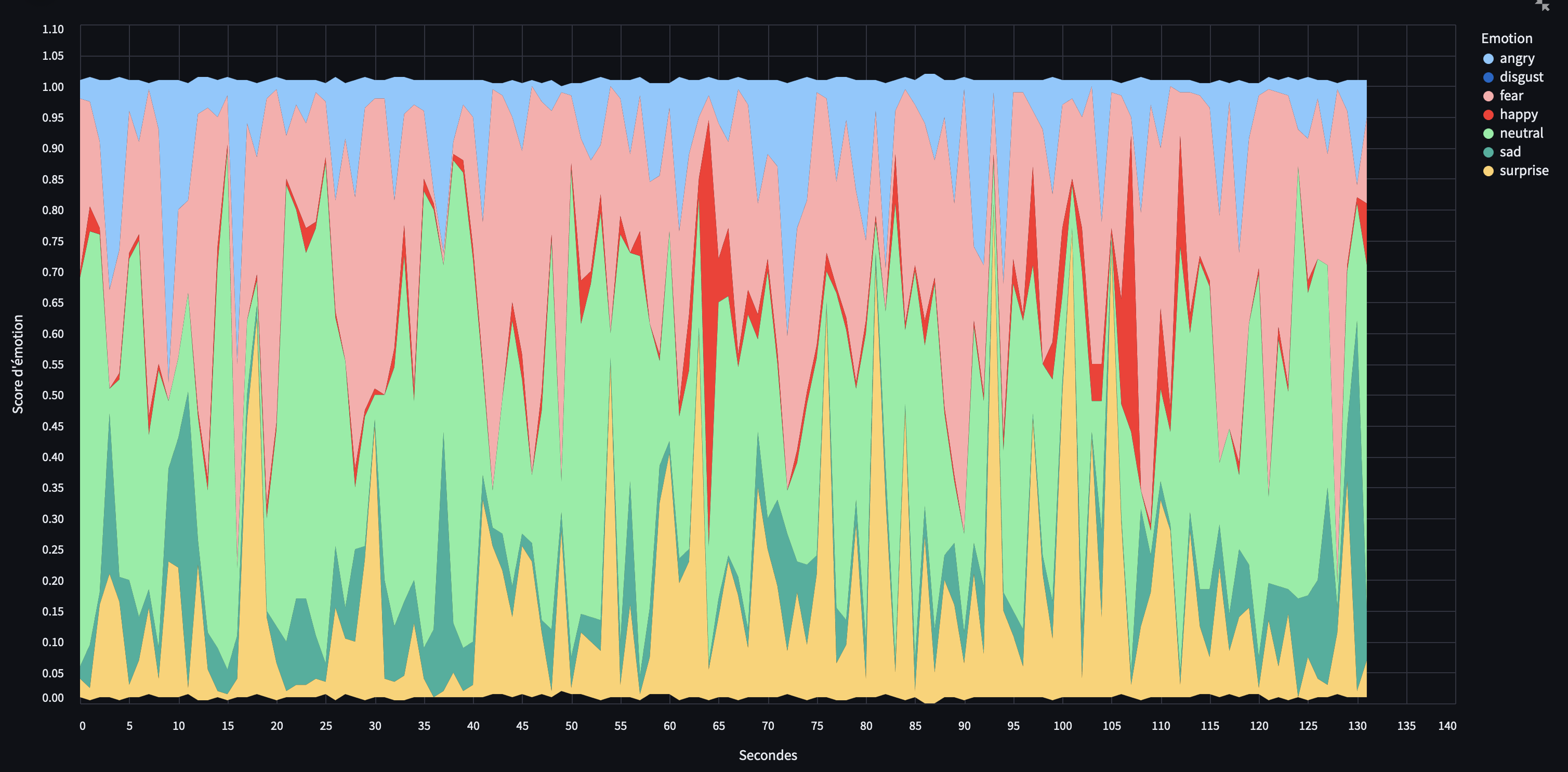
Un lissage des émotions sur 5 secondes permet de rendre le graphique plus lisible et d’en faciliter l’interprétation.
Enfin, vous trouverez les scores des émotions avec le nom de l’image correspondante dans un fichier CSV.

Vous trouverez également les images extraites, annotées avec les scores des émotions. Je précise que le rectangle vert a été volontairement agrandi afin de pouvoir visualiser les scores des émotions, car l’affichage était trop petit dans sa taille d’origine. Le rectangle ne cible en réalité que le visage de l’orateur.
Le code python
Une fois n’est pas coutume, vous devrez aller sur GitHub pour récupérer le code source du script.
Un simple copier-coller et l’installation des librairies dans votre environnement Python vous permettront de lancer le script via la commande suivante :
streamlit run main.py
Enjoy !
Conclusion
Dans ce script, je regrette de ne pas avoir inclus une fonction permettant d’extraire l’émotion dominante, afin d’attribuer non pas un score cumulatif d’émotions à une image, mais de “statuer” sur l’émotion principale. De plus, j’ai choisi d’extraire une image par seconde, ce qui constitue un biais méthodologique. Chaque seconde de vidéo est en réalité composée de 25 images, il serait donc pertinent de tester l’analyse de ces 25 images pour déterminer l’émotion dominante sur une seconde de vidéo. Rassurez-vous, je n’ai pas commis cette erreur dans le prochain script qui utilise la même approche, mais avec la librairie DeepFace 😉
Dernier point : le script, largement fonctionnel et que vous pouvez tester sans écrire une ligne de code grâce à l’interface Streamlit, utilise un dataset pré-entraîné. Cependant, il faut rappeler, au risque de me répéter, que ce modèle n’est pas forcément adapté à toutes les situations ou contextes d’évocation. Il y a nécessité de réentraîner le modèle dans le cadre de la s anté mentale, ou des discours politiques par exemple.
Enfin, ce travail a permis une analyse empirique “inattendue”, où le découpage en images de la vidéo révèle des moments où l’orateur ne s’exprime pas verbalement. Il serait alors intéressant d’analyser ces moments qui figent une émotion ou révèlent une forme de cognition / métacognition (?) dans le discours, préfigurant peut-être les pensées de l’orateur.
Il reste encore du travail à accomplir !
[…] En développant un script d’analyse des émotions avec le modèle FER2013 (Facial Emotion Recognition), une question s’est posée dès le départ : est-il vraiment nécessaire d’extraire et d’analyser toutes les images constituant une seconde de vidéo (soit 25 frames), ou peut-on se contenter d’une image par seconde pour accélérer le processus ? […]
[…] La première version du script était une version préparatoire, conçue pour être opérationnelle …. Les fonctionnalités ont depuis été enrichies pour traiter des vidéos plus longues. […]
[…] être utilisées par exemple pour des analyses comme la détection des émotions faciales, (cf. article 1 – article 2 – article 3). Bon, c’est un petit retour en arrière, mais […]
[…] » de Paul Ekman, souvent peu discriminantes et fréquemment classées comme « neutres » par les modèles, on pourrait exploiter les images issues du flux optique comme filtrage préalable. Ces images […]