

Calcul sans la normalisation L1 – L2
tfidf_vectorizer = TfidfVectorizer(norm=None, use_idf=True)
norm=None
- Objectif : Le paramètre
normspécifie la méthode de normalisation des vecteurs de caractéristiques. None: En spécifiantnorm=None, vous indiquez àTfidfVectorizerde ne pas normaliser les vecteurs de sortie. Cela signifie que les scores TF × IDF calculés resteront dans leur forme brute, sans ajustement basé sur la longueur du vecteur.
use_idf=True
- Objectif : Le paramètre
use_idfcontrôle si l’Inverse Document Frequency (IDF) doit être utilisé dans le calcul des scores TF × IDF. True: En définissantuse_idf=True, vous activez le calcul de l’IDF pour chaque terme.
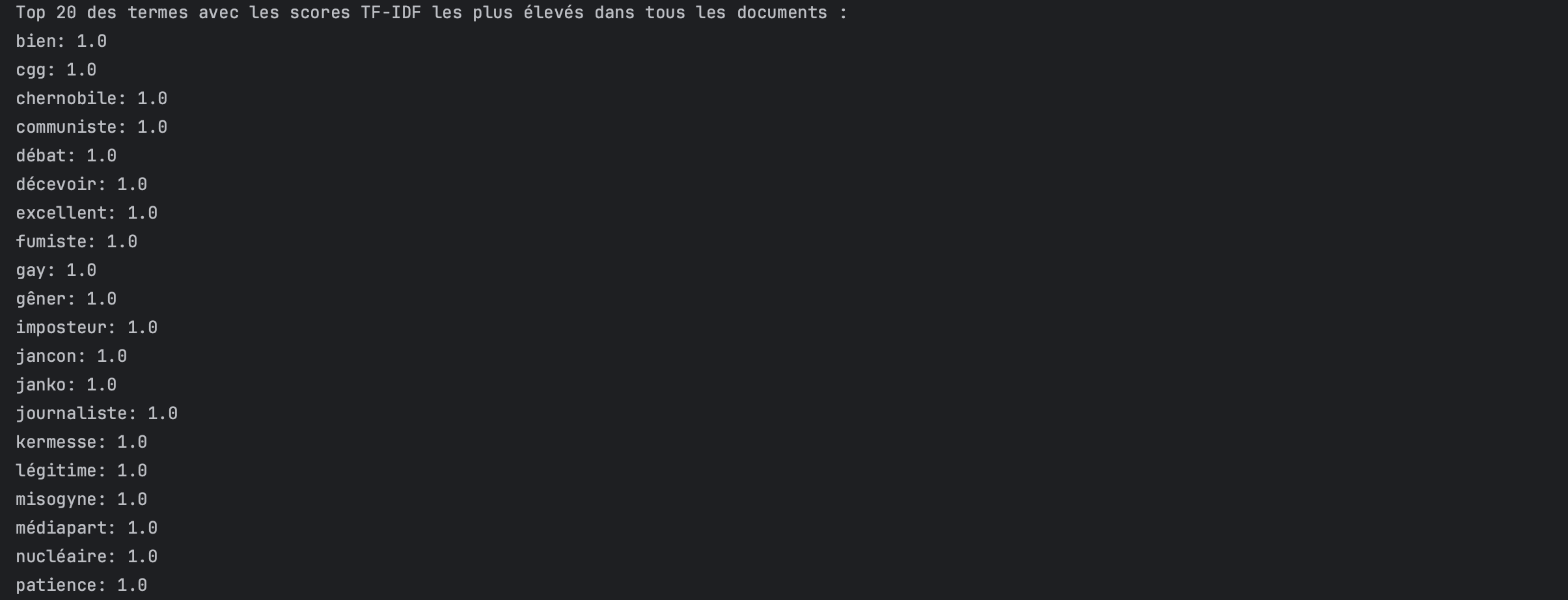
Ainsi, si vous constatez que les termes affichant les scores TF × IDF les plus élevés sont nombreux à obtenir un score de 1, il est judicieux d’expérimenter les deux méthodes.
La présence d’un ou deux termes arborant ce type de score (=1) n’est pas nécessairement problématique. Toutefois, si une vingtaine de termes sont affectés par ce phénomène, alors l’approche sans normalisation s’avère être la plus pertinente.
Nuage de mots clés
Je vais brièvement aborder le sujet du nuage de mots clés, résultant d’une méthode traditionnelle basée sur la fréquence des termes au sein du corpus.
Dans cette approche, chaque message est intégré dans un corpus global. Sans grande surprise, nous constatons que les termes qui apparaissent le plus fréquemment sont des mots de remplissage ou des mots génériques qui, malheureusement, n’offrent guère d’insight. Ces mots ne contribuent pas significativement à la compréhension ou à l’extraction d’informations pertinentes du corpus.

Même corpus avec la normalisation L2
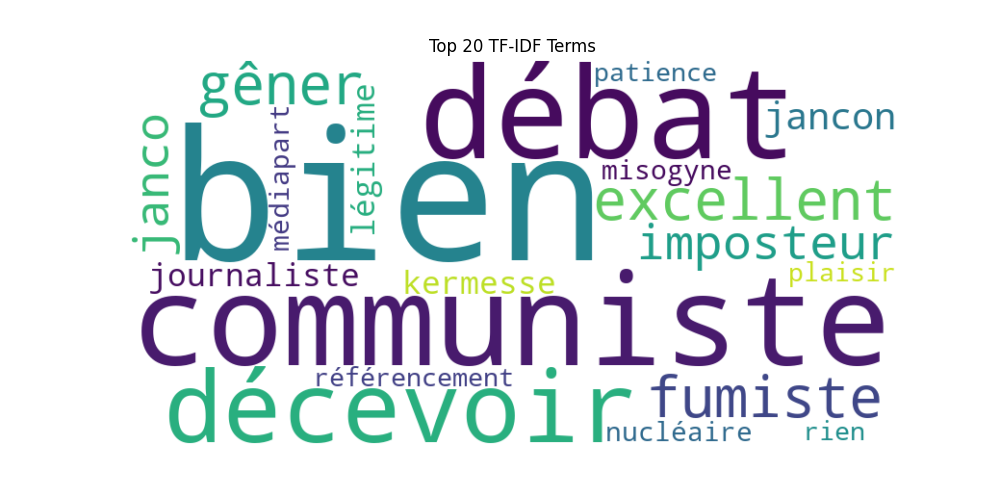
Même corpus sans la normalisation L2
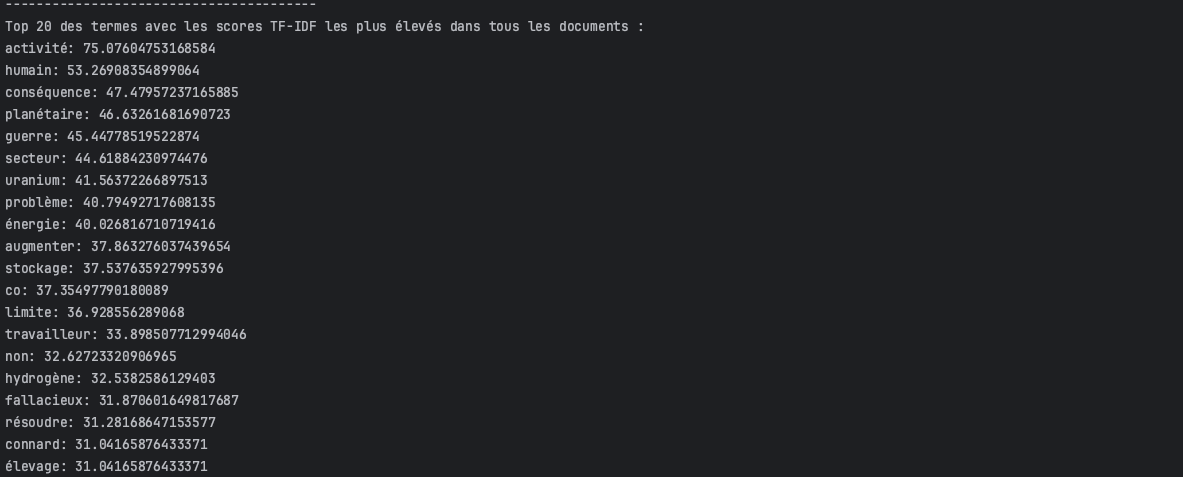
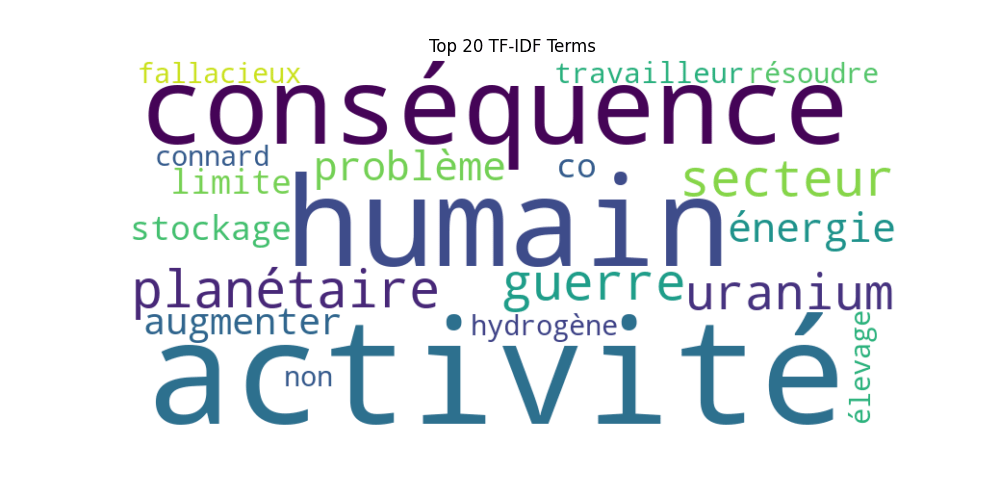
Ici, les termes se concentrent sur le cœur du débat, à savoir la « production d’énergie nucléaire » et ses implications pour l’homme et la planète
Ainsi, la méthode du test TF × IDF révèle un autre insight qu’avec la méthode avec la normalisation (L2).
Même si l’approche utilisant la normalisation L2 offre des perspectives plus séduisantes, d’un point de vue méthodologique et compte tenu de la nature du corpus (à savoir, des commentaires YouTube), l’application du test TF-IDF sans normalisation apparaît comme la plus objective.
Le script le voici, le voilà !
# pip install nltk
# pip install WordCloud
# pip install spacy
# python -m spacy download fr_core_news_lg
# pip install scikit-learn
import re
import spacy
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# Chargement du modèle français de SpaCy
nlp = spacy.load('fr_core_news_lg') # ou 'en_core_web_sm' pour l'anglais
# Récupération et extension des stopwords par défaut de SpaCy
spacy_stopwords = set(nlp.Defaults.stop_words)
custom_stopwords = ['cgg'] # Votre liste personnalisée de mots à exclure séparé par une virgule
spacy_stopwords.update(custom_stopwords) # Étendre avec la liste personnalisée
# Fonction pour lemmatiser le texte et retirer les stopwords
def lemmatize_and_remove_stopwords(text, nlp, stopwords):
doc = nlp(text)
lemmatized_text = " ".join([token.lemma_ for token in doc if token.text.lower() not in stopwords and not token.is_punct])
return lemmatized_text
# Chargement et préparation du fichier texte
file_path = '/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/youtube_jancovici_SR_nettoyer3.txt'
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# Assurez-vous que le contenu n'a pas de lignes vides superflues
content = re.sub(r'\n+', '\n', content).strip()
# Séparation des documents dans le corpus avec '#'
messages = content.split('\n#')
print(f"Nombre initial de messages divisés : {len(messages)}")
# Application de la lemmatisation et de la suppression des stopwords sur chaque document
corpus_lemmatized_and_cleaned = [lemmatize_and_remove_stopwords(msg, nlp, spacy_stopwords) for msg in messages if msg.strip()]
print(f"Nombre de documents après traitement : {len(corpus_lemmatized_and_cleaned)}")
###### Exportation au format csv du corpus lemmatisé / stopword
# Conversion du corpus nettoyé en DataFrame pour l'exportation
df_corpus_cleaned = pd.DataFrame(corpus_lemmatized_and_cleaned, columns=['Document Text'])
# Spécification du chemin vers le fichier CSV de sortie
csv_output_path = '/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/corpus_lemmatised_and_cleaned.csv'
# Exportation du DataFrame vers le fichier CSV
df_corpus_cleaned.to_csv(csv_output_path, index_label='Document Number')
print(f"Le corpus lemmatisé et nettoyé a été exporté dans le fichier: {csv_output_path}")
######
######
# Lecture du fichier CSV contenant le corpus lemmatisé et nettoyé
df_corpus_cleaned = pd.read_csv(csv_output_path)
# Extraction du corpus à partir de la colonne 'Document Text'
corpus_from_csv = df_corpus_cleaned['Document Text'].tolist()
######
### Choix du calcul des scores TF-IDF ###
# option - Choix du calcul des scores TF-IDF avec normalisation L2 (commentez / décommentez les 2 lignes)
# tfidf_vectorizer = TfidfVectorizer(norm='l2', use_idf=True)
# tfidf_matrix_from_csv = tfidf_vectorizer.fit_transform(corpus_from_csv)
# Option - calcul TF*IDF sans normalisation L2 (commentez / décommentez les 2 lignes)
tfidf_vectorizer = TfidfVectorizer(norm=None, use_idf=True)
tfidf_matrix_from_csv = tfidf_vectorizer.fit_transform(corpus_from_csv)
### Fin choix du calcul avec vs sans normalisation ###
# Obtention des noms des mots après l'ajustement du vectoriseur
feature_names_from_csv = tfidf_vectorizer.get_feature_names_out()
# Création d'un DataFrame pour les scores TF-IDF obtenus à partir du fichier CSV
tfidf_df_from_csv = pd.DataFrame(tfidf_matrix_from_csv.toarray(), columns=feature_names_from_csv)
# Application de fit_transform sur votre corpus pour générer la matrice TF-IDF
tfidf_matrix = tfidf_vectorizer.fit_transform(corpus_from_csv)
# Création d'un DataFrame pour feature_names
feature_names = tfidf_vectorizer.get_feature_names_out()
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names)
# Ajout d'informations supplémentaires
tfidf_df['Document Number'] = range(1, len(tfidf_df) + 1)
# Optionnel: Ajouter le texte des documents si présent dans le CSV original
# tfidf_df['Document Text'] = corpus_from_csv
# Identifier le terme avec le score TF-IDF le plus élevé pour chaque document
tfidf_df['Top TF-IDF Term'] = tfidf_df[feature_names].idxmax(axis=1)
# Affichage des scores TF-IDF par document avec filtrage pour les scores > 0
for index, row in tfidf_df.iterrows():
print(f"Document {index + 1} Scores:")
filtered_scores = {term: score for term, score in row[feature_names].items() if score > 0}
for term, score in filtered_scores.items():
print(f"\t{term}: {score}")
print("-" * 40)
# Exportation des scores TF-IDF dans un fichier CSV
csv_path_scores = '/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/resultats_doc_final.csv'
tfidf_df.to_csv(csv_path_scores, index=False)
# Identification et affichage du top 20 des termes avec les scores TF-IDF les plus élevés
top_scores = tfidf_df[feature_names].max().nlargest(20)
print("Top 20 des termes avec les scores TF-IDF les plus élevés dans tous les documents :")
for term, score in top_scores.items():
print(f"{term}: {score}")
# Exportation du top 20 des scores TF-IDF dans un fichier CSV
top_20_terms = pd.DataFrame({'Term': top_scores.index, 'TF-IDF Score': top_scores.values})
csv_path_top_20 = '/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/top_20_terms_final.csv'
top_20_terms.to_csv(csv_path_top_20, index=False)
# Génération et affichage de nuages de mots
def generate_wordcloud(words, title, file_path):
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(words)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title(title)
plt.savefig(file_path)
plt.show()
# Nuage de mots pour tous les termes
generate_wordcloud(dict(zip(feature_names, np.mean(tfidf_matrix.toarray(), axis=0))), "Global TF-IDF", "/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/global_tfidf_final.png")
# Nuage de mots pour le top 20 des termes
generate_wordcloud(top_20_terms.set_index('Term')['TF-IDF Score'].to_dict(), "Top 20 TF-IDF Terms", "/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/top20_tfidf_final.png")
print(f"Les scores TF-IDF pour chaque document ont été sauvegardés dans {csv_path_scores}")
print(f"Les 20 termes les plus importants basés sur les scores TF-IDF ont été sauvegardés dans {csv_path_top_20}")
####### Loi de Zipf à partir des résultats TF-IDF
# Génération de la loi de Zipf
tfidf_sum = np.array(tfidf_matrix.sum(axis=0)).flatten()
sorted_tfidf_sum = np.sort(tfidf_sum)[::-1] # Trier les scores TF-IDF en ordre décroissant
ranks = np.arange(1, len(sorted_tfidf_sum) + 1) # Créer un tableau de rangs
plt.figure(figsize=(10, 6))
plt.loglog(ranks, sorted_tfidf_sum, marker="o")
plt.title("Loi de Zipf - Fréquence des termes vs Rang")
plt.xlabel("Rang du terme")
plt.ylabel("Fréquence (Somme des scores TF-IDF)")
plt.show()
Conclusion et perspectives
L’utilisation du test TF-IDF peut sembler relativement simple avec un petit corpus. Toutefois, dans notre cas, il semble primordial d’explorer les deux méthodes.
Je tiens également à souligner que, malgré un prétraitement automatisé du corpus via un script Python, une révision manuelle pour harmoniser le langage des commentaires s’est avérée nécessaire. J’ai volontairement mis de côté cette étape pour me concentrer sur la viabilité de l’approche. Sans le rechercher, j’ai cumulé la difficulté en choisissant un corpus composé de commentaires YouTube…
La prochaine étape consistera à tester le TF-IDF sur un corpus provenant d’Europresse, ce qui représente une difficulté en moins.
Je me questionne également sur l’applicabilité du test TF-IDF sur des co-occurrences dans le cadre d’une analyse d’un corpus encore plus volumineux, une piste à explorer !
Enfin, une autre perspective intéressante serait de conduire des analyses de similarité à partir de mots vectorisés. Pour cette dernière approche, je devrais probablement me tourner vers Google Colab qui offre les ressources matérielles nécessaires à de tels calculs !
[…] mettant notamment en exergue l’importance des mots moins fréquents de manière similaire à une pondération TF‑IDF. Il n’existe pas de mode d’embedding universellement supérieur, mais le choix de la […]