Le traitement automatique du Langage Naturel (NLP)
Les moteurs de recherche s’appuient sur le NLP (Natural Language Processing) pour interpréter les requêtes complexes et fournir des résultats pertinents. Google utilise le modèle de langage BERT, (Bidirectional Encoder Representations from Transformers) permettant par exemple de résumer une page web à une description sous le titre, ou bien encore proposant des termes par implémentation de mots lorsque vous saisissez votre requête.
La lemmatisation m’intéresse particulièrement car c’est un processus clé dans le domaine de la recherche en Sciences Humaines et sociales, surtout lorsqu’il s’agit d’analyse textuelle statistique. Cette technique consiste à ramener les différents termes d’un texte à leur forme de base ou lemme, permettant ainsi de simplifier le texte pour l’analyse.
En pratique, la lemmatisation aide à regrouper les différentes formes d’un mot, comme les déclinaisons grammaticales des verbes, en une seule occurrence. Cela rend l’analyse statistique plus pertinente, en se concentrant en premier lieu sur la fréquence des lemmes plutôt que sur leurs multiples variantes.
 Le logiciels d’analyse textuelle, tels que IRAMATEQ, propose une lemmatisation de manière automatisée après intégration du corpus.
Le logiciels d’analyse textuelle, tels que IRAMATEQ, propose une lemmatisation de manière automatisée après intégration du corpus.
Toutefois, pour approfondir la compréhension de ce processus, l’exploration des différentes bibliothèques Python spécialisées permet de réaliser une veille informationnel dans ce domaine.
Cet article se concentre sur l’analyse (partielle) des fonctionnalité de la librairie SpaCy et la libraire NLTK.
Lemmatisation avec SpaCy
La lemmatisation en français avec SpaCy prend en compte les variations grammaticales des mots, telles que le genre, le nombre et le temps.
SpaCy utilise des modèles linguistiques complexes pour comprendre le contexte dans lequel chaque mot est utilisé, ce qui lui permet de retrouver le lemme de manière précise.
Voici un petit script illustrant la fonction de lemmatisation de SpaCy (Vous pouvez modifier les phrases dans le script).
import spacy
# Charger le modèle de langue française
nlp = spacy.load("fr_core_news_sm")
# Différentes formes du verbe "parler"
phrases = ["Je parle", "Tu as parlé", "Elles parlaient", "Nous parlerons", "Ils avaient parlé"]
# Traitement de chaque phrase et affichage du lemme
for phrase in phrases:
doc = nlp(phrase)
for token in doc:
if token.pos_ == "VERB":
print(f"Forme originale: '{token.text}' -> Lemme: '{token.lemma_}'")
# Sortie attendue:
# Forme originale: 'parle' -> Lemme: 'parler'
# Forme originale: 'parlé' -> Lemme: 'parler'
# Forme originale: 'parlaient' -> Lemme: 'parler'
# Forme originale: 'parlerons' -> Lemme: 'parler'
# Forme originale: 'parlé' -> Lemme: 'parler'
SpaCy intègre dans sa base d’entrainement un module spécifique pour la lemmatisation de la langue Française.
Voici un exemple de script Python pour la lemmatisation avec SpaCy en français (Vous pourrez comparer le résultat (même phrase) avec la bibliothèque NTLK dans la suite de l’article).
import spacy
# Charger le modèle de langue française
nlp = spacy.load("fr_core_news_sm")
# Texte à lemmatiser
text = "Les chats chassaient une souris"
# Traitement du texte
doc = nlp(text)
# Affichage des lemmes
for token in doc:
print(token.text, "->", token.lemma_)
# Sortie attendue:
Les -> le
chats -> chat
chassaient -> chasser
une -> un
souris -> souris
Test de SpaCy avec un paramétrage plus précis (?)
La tokenisation avec SpaCy
La tokenisation, qui consiste à découper un texte en tokens (mots, ponctuations, etc.), est le point de départ de nombreuses analyses en traitement automatique du langage naturel (NLP). Une fois la tokenisation effectuée, plusieurs types d’analyses peuvent être réalisés sur les tokens pour extraire ou comprendre différentes informations du texte.
- Tagging de parties du texte
Après la tokenisation, chaque token peut être étiqueté avec sa partie du discours (nom, verbe, adjectif, etc.). Cette étape est connue sous le nom de « Part-of-Speech Tagging » ou « POS Tagging ».
Le POS Tagging est essentiel pour comprendre la structure grammaticale d’une phrase et la fonction de chaque mot. Il aide dans de nombreuses tâches telles que l’analyse syntaxique, la compréhension de la phrase.
- Reconnaissance d’Entités Nommées (NER)
La NER consiste à identifier et classer certains tokens comme appartenant à des catégories spécifiques d’entités nommées, comme les noms de personnes, les organisations, les lieux, les dates…
La reconnaissance d’entités est cruciale pour de nombreuses applications NLP, notamment le traitement de texte, le résumé automatique,…
- Analyse de Dépendances (Dependency Parsing)
L’analyse de dépendances cherche à établir des relations entre les tokens, en identifiant, par exemple, le sujet et l’objet d’un verbe. Cette analyse est importante pour comprendre la relation entre les mots dans une phrase, ce qui est essentiel pour la compréhension sémantique du texte.
- Lemmatisation
La lemmatisation consiste à réduire les mots à leur forme de base ou « lemme ». Elle est particulièrement utile pour l’analyse de texte, la recherche d’informations, et la préparation de données pour d’autres tâches de NLP.
Spécificité de la tokenisation avec SpaCy
SpaCy offre deux méthodes principales de tokenisation : une tokenisation basée sur les mots et une tokenisation basée sur les phrases. Pour effectuer la tokenisation des phrases, SpaCy utilise la ponctuation pour identifier et séparer les phrases dans un texte.
Dans mon exemple j’ai utilisé la librairie YoutubeTranscriptAPI pour extraire la retranscription d’une vidéo Youtube. Cette transcription est accessible dans l’interface de Youtube. Toutefois elle ne comporte pas de ponctuation…
Google nous inciterai t-il à utiliser son service « Speech to text » accessible via l’API mais payante (60 mn/mois de vidéo gratuite) ? D’autant plus que la retranscription est décevante manquant cruellement de précision.
- Tokenisation basée sur les mots
Lors de la tokenisation au niveau des mots, chaque mot est traité individuellement en tant que token, sans tenir compte de son contexte dans la phrase. Cela signifie que le processus se concentre sur l’identification des limites des mots dans le texte, plutôt que sur leur sens ou leur fonction dans une structure grammaticale plus large.
import spacy
# Chargement du modèle français de SpaCy
nlp = spacy.load("fr_core_news_sm")
# Texte à analyser
text = "SpaCy est un outil puissant. Il est largement utilisé en NLP."
# Traitement du texte par SpaCy
doc = nlp(text)
# Itération sur les tokens (mots) détectés dans le texte
for token in doc:
print(token.text)
Résultat attendu :
SpaCy est un outil puissant . Il est largement utilisé en NLP .
- Tokenisation basée sur les phrases
La tokenisation par phrase aide à comprendre la structure globale d’un texte. En divisant un texte en phrases, SpaCy permet une meilleure analyse du contexte et de la signification globale. Beaucoup d’analyses en NLP, comme la reconnaissance d’entités nommées ou l’analyse de sentiment, sont plus précises lorsqu’elles sont effectuées sur des phrases complètes plutôt que sur des segments de texte déconnectés.
Pour les longs documents, la tokenisation par phrase permet de décomposer le texte en unités plus petites et plus gérables, facilitant ainsi le traitement et l’analyse.
La segmentation en phrases est souvent un prérequis pour des tâches plus complexes comme l’analyse syntaxique (parsing) et la compréhension de la relation entre les phrases.
import spacy
# Chargement du modèle français de SpaCy
nlp = spacy.load("fr_core_news_sm")
# Texte à analyser
text = "SpaCy est un outil puissant. Il est largement utilisé en NLP."
# Traitement du texte par SpaCy
doc = nlp(text)
# Itération sur les phrases détectées dans le texte
for sent in doc.sents:
print(sent.text)
Résultat attendu :
SpaCy est un outil puissant. Il est largement utilisé en NLP.
Stemming avec NLTK
Contrairement à SpaCy, NLTK (Natural Language Toolkit) utilise une approche plus simple pour le stemming, sans tenir compte des subtilités grammaticales du français.
L’algorithme de stemming dans NLTK réduit simplement les mots à leur racine, ce qui peut parfois mener à des résultats moins précis.
Par exemple, il va réduire « chats » à « chat », mais il va également transformer « souris » en « sour », ce qui est ambiguë dans la mesure ou avec cette réduction on ne sait pas si le lemme « souri » signifie « souris » ou fait référence au verbe « sourir »…
Cette librairie est généralement plus rapide et plus simple que la lemmatisation avec SpaCy, mais elle est moins précise, car elle ne prend pas en compte le contexte complet du mot.
Voici un exemple de script Python pour le stemming avec NLTK en français :
import nltk
from nltk.stem.snowball import FrenchStemmer
# Télécharger les ressources nécessaires
nltk.download('punkt')
# Initialiser le stemmer français
stemmer = FrenchStemmer()
# Texte à traiter
text = "Les chats chassaient une souris"
# Tokenisation du texte
tokens = nltk.word_tokenize(text)
# Application du stemming
stemmed_tokens = [stemmer.stem(token) for token in tokens]
# Affichage des tokens stemmés
print(stemmed_tokens)
# Sortie attendue: ['Les', 'chat', 'chass', 'une', 'sour']
Le script final
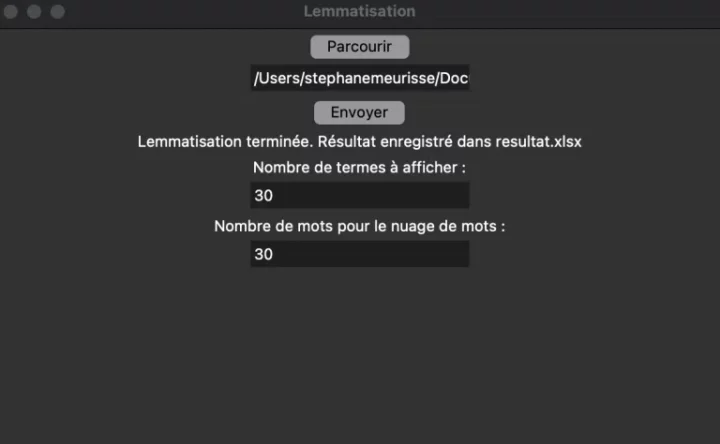
Le script intègre une interface graphique simplifiée qui vous permet de sélectionner un fichier Excel.
Dans mon exemple je précise que le texte est issu de la retranscription d’une vidéo en texte (provenant de Youtube). Ce texte a aucune ponctuation…
Dans ce cas SpaCy procède à la tokenisation des mots et non des phrases.
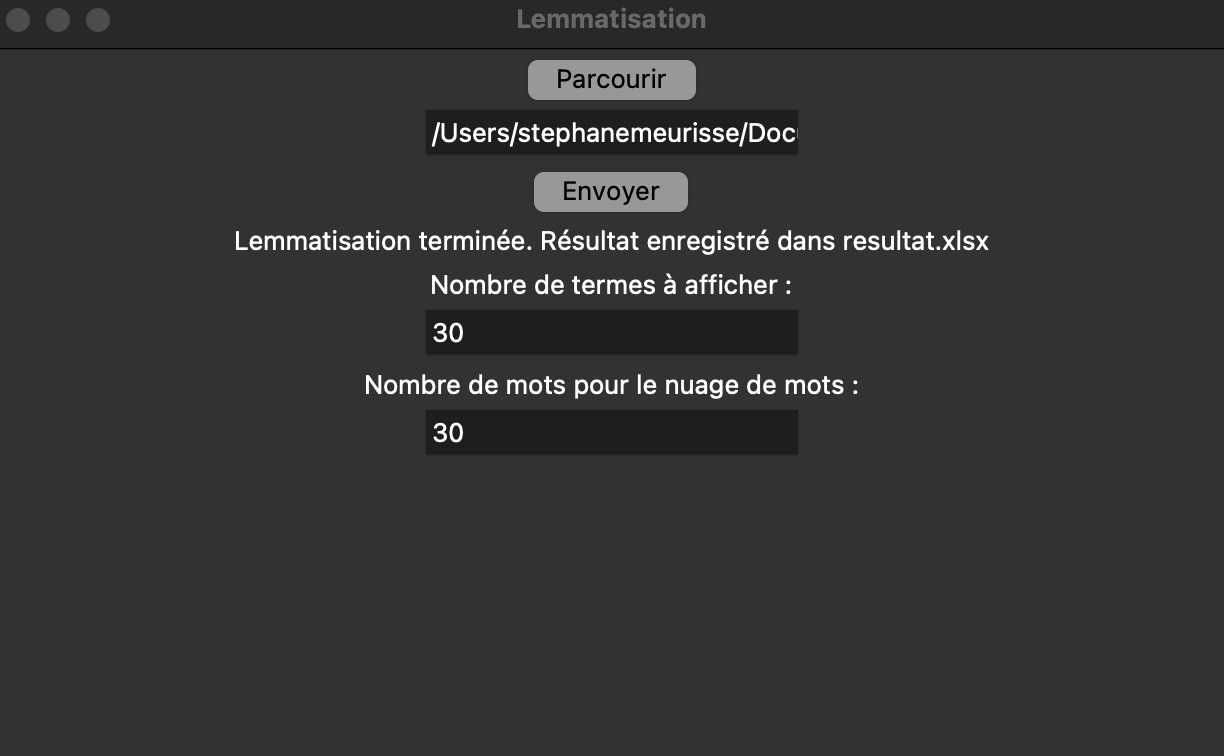
Le script est configuré pour se concentrer sur une colonne nommée « Texte » du fichier xlsx de la restranscription.
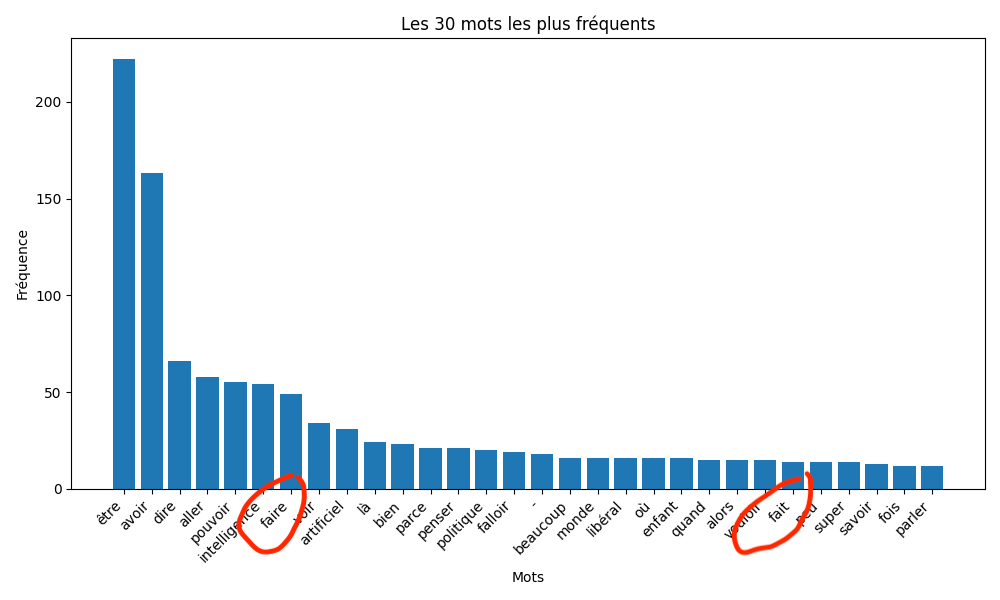
Avant de lancer l’analyse, vous devez définir le nombre de mots à extraire pour créer un graphique basé sur la fréquence des termes les plus récurrents, une étape similaire est requise pour générer un nuage de mots clés.
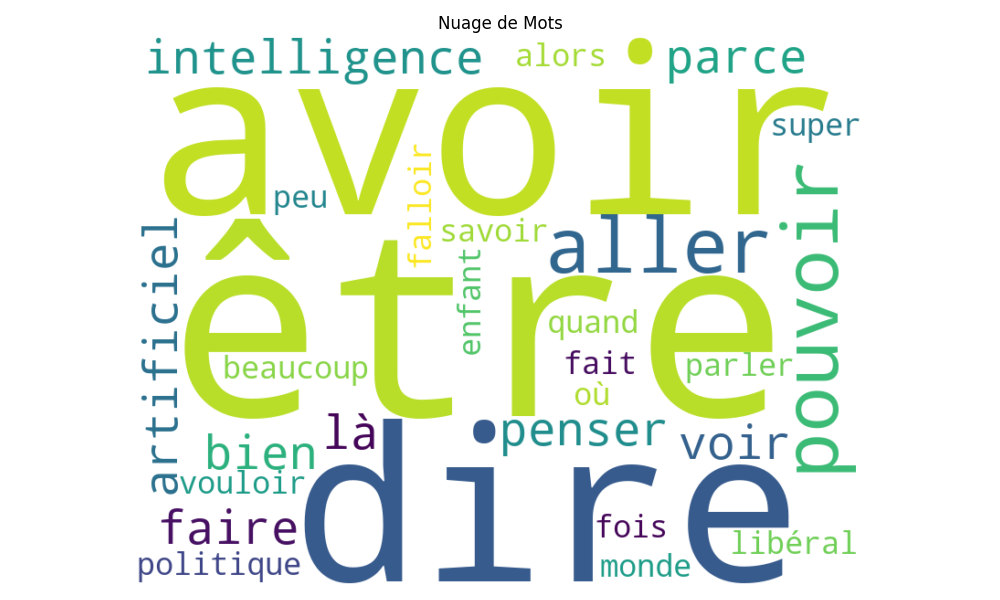
En utilisant la bibliothèque SpaCy en version « small » pour le français, l’analyse produit deux visuels et un fichier Excel nommé « résultats.xlsx » enrichi d’une colonne nommée « texte lemmatisé« , ainsi qu’un fichier « résultat.txt ».
Pour que le script fonctionne correctement, une série de bibliothèques Python doit être installée :
pandas: Bibliothèque pour la manipulation et l’analyse de données. Elle est utilisée ici pour traiter les données du fichier Excel.tkinter: Biblithèque pour créer des interfaces graphiques en Python. Elle est utilisé pour permettre la sélection de fichiers et la saisie des paramètres utilisateur.matplotlib: Cette bibliothèque est utilisée pour la génération des graphiques.spacy: Bibliothèque de traitement de langage naturel (NLP), utilisée ici pour lemmatiser le texte.fr_core_news_sm: Il s’agit du modèle SpaCy pour le français, optimisé pour un traitement rapide.openpyxl: Cette bibliothèque est nécessaire pour lire et écrire des fichiers Excel, utilisée ici pour créer le fichier « résultats.xlsx ».wordcloud: Utilisée pour générer le nuage de mots clés.
A noter que vous pouvez (directement dans le script) exclure des mots de l’analyse.
# version du modèle small de SpaCy (sm)
# pip install pandas
# pip install tkinter
# pip install matplotlib
# pip install spacy
# python -m spacy download fr_core_news_sm
# pip install openpyxl
# pip install wordcloud
# pip install pyarrow
import tkinter as tk
from tkinter import filedialog
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
import spacy
from wordcloud import WordCloud
# Charger le modèle SpaCy pour le français
nlp = spacy.load("fr_core_news_sm")
# Fonction pour parcourir et sélectionner un fichier Excel
def parcourir():
file_path = filedialog.askopenfilename(filetypes=[("Fichiers Excel", "*.xlsx")])
entry_path.delete(0, tk.END) # Effacer le contenu de la zone de texte
entry_path.insert(0, file_path) # Insérer le chemin du fichier sélectionné dans la zone de texte
# Fonction pour effectuer la lemmatisation, créer un graphique et un nuage de mots
def lemmatiser():
# Récupérer le chemin du fichier depuis la zone de texte
file_path = entry_path.get()
exclude_words = ["de", "que", "un", "une", "des", "le", "la", "les", "et", "mais", "ou", "car", "à", "dans",
"sur", "sous", "avec", "ce", "cette", "ces", "cet", "son", "tu", "il", "elle", "nous", "vous",
"ils", "elles", "je", "'", "ça", "pas", "qui", "on", "en", "cela", "tout", "me", "donc", "pour",
"du", "plus", "par", "y", "qu'on", "parce que", "te", "se", "des", "du", "de la","de", "et",
"que", "on", "pas", "l'", "l", "en", "c", "qu", "d", "donc", "ça", "dans", "n", "mais", "j",
"ce", "y", "pour", "ne", "très", "sur", "ils", "elles", "me", "te", "se", "leur",
"leurs", "celui", "celle", "ceux", "celles", "mon", "ton", "son", "ma", "ta", "sa", "mes",
"tes", "ses", "nos", "vos", "leurs", "mien", "tien", "sien", "nôtre", "vôtre", "leur", "miens",
"tiens", "siens", "leurs", "mienne", "tienne", "sienne", "miennes", "tiennes", "siennes",
"notres", "votres", "leurs", "même", "au"]
try:
# Charger le fichier Excel
data = pd.read_excel(file_path)
# Lemmatiser la colonne "Texte"
num_top_terms = int(num_terms_entry.get())
data["Texte Lemmatisé"] = data["Texte"].apply(lambda x: " ".join([token.lemma_ for token in nlp(x) if token.lemma_.lower() not in exclude_words]))
# Créer un graphique des termes les plus fréquents
words = " ".join(data["Texte Lemmatisé"]).split()
word_freq = Counter(words)
most_common_words = word_freq.most_common(num_top_terms)
# Affichage du graphique
plt.figure(figsize=(10, 6))
plt.bar([word[0] for word in most_common_words], [word[1] for word in most_common_words])
plt.xticks(rotation=45, ha="right")
plt.xlabel("Mots")
plt.ylabel("Fréquence")
plt.title(f"Les {num_top_terms} mots les plus fréquents")
plt.tight_layout()
# Enregistrer le graphique dans un fichier image
graph_file_path = "graphique.png"
plt.savefig(graph_file_path)
plt.show()
# Enregistrer le résultat dans un nouveau fichier Excel
result_file_path = "resultat.xlsx"
data.to_excel(result_file_path, index=False)
# Enregistrer le résultat dans un fichier texte
with open("resultat.txt", "w", encoding="utf-8") as file:
for text in data["Texte Lemmatisé"]:
file.write(text + "\n")
# Créer un nuage de mots basé sur les termes les plus fréquents
create_word_cloud(most_common_words)
# Afficher un message de succès
message_label.config(text=f"Lemmatisation terminée. Résultat enregistré dans {result_file_path}")
except Exception as e:
# En cas d'erreur, afficher un message d'erreur
message_label.config(text=f"Erreur : {str(e)}")
# Fonction pour créer un nuage de mots
def create_word_cloud(most_common_words):
num_words_for_wordcloud = int(num_words_entry.get())
words_for_wordcloud = " ".join([word[0] for word in most_common_words[:num_words_for_wordcloud]])
wordcloud = WordCloud(width=800, height=600, background_color="white").generate(words_for_wordcloud)
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.title("Nuage de Mots")
plt.tight_layout()
# Enregistrer le nuage de mots dans un fichier image
wordcloud_file_path = "wordcloud.png"
plt.savefig(wordcloud_file_path)
plt.show()
# Créer une fenêtre tkinter
window = tk.Tk()
window.title("Lemmatisation")
# Créer un bouton "Parcourir"
parcourir_button = tk.Button(window, text="Parcourir", command=parcourir)
parcourir_button.pack()
# Créer une zone de texte pour afficher le chemin du fichier sélectionné
entry_path = tk.Entry(window)
entry_path.pack()
# Créer un bouton "Envoyer"
envoyer_button = tk.Button(window, text="Envoyer", command=lemmatiser)
envoyer_button.pack()
# Créer une étiquette pour afficher des messages
message_label = tk.Label(window, text="")
message_label.pack()
# Créer une entrée pour spécifier le nombre de termes à afficher dans le graphique
num_terms_label = tk.Label(window, text="Nombre de termes à afficher :")
num_terms_label.pack()
num_terms_entry = tk.Entry(window)
num_terms_entry.pack()
# Créer une entrée pour spécifier le nombre de mots à inclure dans le nuage de mots
num_words_label = tk.Label(window, text="Nombre de mots pour le nuage de mots :")
num_words_label.pack()
num_words_entry = tk.Entry(window)
num_words_entry.pack()
# Lancer la fenêtre tkinter
window.mainloop()
Conclusion
Cet article a exploré les capacités de la bibliothèque SpaCy, et j’ai ajouté involontairement une difficulté en intégrant une retranscription textuelle d’une vidéo YouTube d’une qualité plutôt moyenne. Néanmoins, j’ai démontré que SpaCy est apte à traiter un volume important de texte, malgré les ressources requises pour son fonctionnement.
La prochaine étape consistera à comparer SpaCy avec le service « Speech to Text » de Google.
[…] utilisant le script vous entreprendrez la lemmatisation du texte à l’aide de la bibliothèque Spacy, (la librairie NLP du pauvre 😉 Je suis parfois un peu surpris par la lemmatisation du texte […]
[…] spaCy : Pour un traitement du langage naturel. […]
[…] En conclusion, comprendre les différentes étapes du NLP et choisir les bonnes bibliothèques est essentiel pour effectuer des analyses précises et pertinentes. BERT, grâce à ses capacités avancées de compréhension contextuelle, se positionne comme un outil de référence dans ce domaine. Mais il est (très gourmand) en ressource et nécessitant de passer avec google colab. Voici les principales bibliothèques de traitement du langage. Dans ce tutoriel, je me concentrerai donc sur la description des étapes du processus de traitement du langage avec la bibliothèque la plus « efficiente » (rapport vitesse/efficacité) : SpaCy. […]
Je n’ai pas lu pour l’instant la totalité de votre article mais dès le premier exemple j’ai le même genre d’erreur que je peux avoir avec spacy sur le programme que je veux faire :
j’ai repris votre code et en sortie j’obtiens ceci :
Forme originale: ‘parle’ -> Lemme: ‘parler’
Forme originale: ‘parlé’ -> Lemme: ‘parler’
Forme originale: ‘parlerons’ -> Lemme: ‘parler’
Forme originale: ‘parlé’ -> Lemme: ‘parler’
On pourrait dire que tout est ok sauf qu’il manque une forme car votre tableau contient cinq formes au départ et je n’en ai que quatre à l’arrivée :
phrases = [« Je parle », « Tu as parlé », « Elles parlaient », « Nous parlerons », « Ils avaient parlé »]
Je ne m’en étais même pas remarqué avant de faire un deuxième essai avec un verbe qui m’a posé problème et forcé à faire une recherche internet :
J’ai conservé les cinq premiers termes en utilisant des déclinaisons du verbe abaisser et j’en ai rajouté un sixième « abaissai » soit le passé simple sans son pronom personnel je ou j’ dans ce cas j’ai donc :
phrases = [« J’abaisse », « Tu as abaissé », « Elles abaissaient », « Nous abaisserons », « Ils avaient abaissé », « abaissai »]
donc 6 termes à retrouver. En résultat, j’ai :
Forme originale: ‘abaisse’ -> Lemme: ‘abaisse’
Forme originale: ‘abaissé’ -> Lemme: ‘abaisser’
Forme originale: ‘abaisserons’ -> Lemme: ‘abaisser’
Forme originale: ‘abaissé’ -> Lemme: ‘abaisser’
Soit encore une fois ici quatre termes sur 6 ! cherchez l’erreur.
En premier encore une fois tout faux puisque j’abaisse devient abaisse (on supprime le pronom) et son lemme est abaisse verbe pas verbe ? on n’en sait rien !
en deux ok cela fonctionne; en trois « elles abaissaient » n’est pas pris en compte, pourquoi ? en quatre « nous abaisserons » ok cela marche; en cinq « Ils avaient abaissé » ok cela marche; en 6 pas de réponse.
C’est donc trois formes sur 6 qui soit n’ont pas de réponse soit on une erreur dans la réponse et si pour abaissai je n’ai pas mis volontairement le « j' » pour « j’abaisse » il est bien là et il considère abaisse comme un nom et pas un verbe (de « abaisse » : Pâte amincie sous le rouleau à pâtisserie.).
Comment réaliser une vraie étude de texte comme cela.
De mon côté le but était simple et le texte on ne peux plus connu puisqu’il s’agit du petit prince ».
dans les tous premiers mots par ordre alphabétique il me trouve :
abaissai abaissai adjectif c’est un verbe
abeilles abeille adjectif c’est un nom
abord abord adverbe c’est un nom mais d’abord est une locution adverbiale
puis plus loin
aplomb aplomb verbe c’est un nom ou à la rigueur une locution adverbiale s’il y avait un « d' »
et encore plus loin
éléphant élépher verbe mais où a-t-il était chercher le verbe élépher plutôt que simplement le nom éléphant, existe-t-il même ce verbe ?
J’avoue que je n’ai pas particulièrement vérifié le reste des mots du Petit Prince je suis tombé par hasard sur ces erreurs mais d’autres existent du type
amérique amériqu adjectif pourquoi pas de e final et pourquoi pas nom propre comme il a trouvé pour afrique (malgré l’absence de majuscule)
Bon, j’arrête là, j’y passerai l’après-midi autrement.
Je lirai votre article un peu plus tard puisque j’ai un rdv qui m’attends. Peut-être d’ici là vous aurez lu mon commentaire car je suis abasourdi par les résultats qui sont inutilisables en l’état. Peut-être de votre coté avez-vous plus d’expérience que moi et pouvez m’indiquez quelques astuces ou une autre façon de gérer un traitement de ce type.
Ce n’est bien sûr pas une critique de votre article (puisque je ne l’ai pas lu) au contraire (plutôt une interrogation, une demande si vous avez le même genre de problème que moi et si vous avez pu le résoudre.
Cordialement
Bon il faut que je lise votre article en entier.
J’ai lu rapidement votre commentaire, avec Spacy il est largement conseillé de charger le modèle large (plus gourmand en ressources) :
# Charger le modèle SpaCy pour le français (modèle small)
nlp = spacy.load(« fr_core_news_sm »)
Remplacer les lignes de code ci-dessus par :
# Charger le modèle SpaCy pour le français (large modèle)
nlp = spacy.load(« fr_core_news_lg »)
Dans le terminal de votre environnement python vous devrez charger le modèle avec cette commande : python -m spacy download fr_core_news_lg
Refaites quelques tests 😉
Il faut savoir que Spacy n’est pas LA référence pour la contextualisation du langage. Le modèle BERT (développé par Gooogle, a une « capacité d’attention » grâce à l’embedding qui apporte beaucoup plus de nuances dans le langage. Le modèle tient compte des phrases précédentes.
L’INRIA (Labo Français) à développer la version Française qui se nomme « Camembert ».
Voila pour un début de réponse.
Merci pour votre réponse rapide.
J’ai changé le modèle en utilisant la version large mais cela n’arrange pas grand-chose car si cela permet de gérer l’ensemble des mots de votre premier test sur les déclinaisons de ‘parler’ et du mien sur ‘abaisser’ pour lequel maintenant il reconnait que c’est une déclinaison du verbe pour « j’abaisse’ et ‘j’abaissai’, ‘abeilles’ est toujours un adjectif, ‘abord’ toujours un adverbe, ‘abri’ passe de nom à adjectif, ‘abîme’ devient un verbe, ‘adieu’ un nom propre, ‘aiguilleur’ un adjectif — je m’arrête là — alors que tous ces mots étaient correctement définis dans la version small. Je n’ai heureusement plus ‘éléphant’ comme déclinaison du verbe ‘élépher’ !
Mais beaucoup d’autres aberrations sont présentes. Par exemple les expressions avec des tirets sont très mal comprises que ce soient des mots composés comme ‘chef-d’œuvre’ (oeuvre) ou ‘c’est-à-dire’ ou encore les formes interrogatives comme ‘bois-tu’ qui devient un nom propre ou ‘y-a-t-il’, ‘est-ce’ sur lesquels spacy considère des mots comme -ce ou -il, -elle, -en, -là.
De plus d’une passe de test à une autre au modifiant la demande pour comprendre par exemple les chiffres romains il me change d’autres réponses comme ‘abaissai’ qui devient inconnu alors qu’il m’indique bien ‘abaisser’ comme lemme de celui-ci ou ‘acheva’ qui passe d’adjectif à nom propre parce qu’il est en début de phrase.
Mais il m’a permis aussi de voir des fautes commises par la reconnaissance optique et de les corriger. J’ai donc un texte plus propre mais comme j’ai une erreur d’interprétation des mots d’au moins 10 % c’est un peu difficile de faire une étude de texte sur celui-ci. Le texte est court donc les corrections peuvent être faites à la main mais sur des textes beaucoup plus longs ou plus difficiles le temps passé en vaut-il la chandelle. Le modèle Bert est-il disponible au grand public, le modèle large de Spacy est-il modifiable et est-ce utile ou faisable (j’ai vu qu’il était sur github). Merci en tout cas pour votre aide, je ne veux pas polluer votre blog avec mes commentaires ou mes demandes donc une discussion en privé est possible si cela vous agrée. Cordialement
Le modèle BERT, développé par Google, est open source. L’INRIA l’a entraîné pour la langue française, (modèle Camembert). Il existe également le modèle Flaubert, mais Camembert est souvent considéré comme la référence pour le traitement du français.
Pour plus d’infos : https://almanach.inria.fr/software_and_resources/CamemBERT-fr.html
En comparaison, la librairie SpaCy est une solution moins puissante pour le traitement automatique du langage (NLP), notamment pour le français, car elle n’est pas aussi spécialisée. Il est cependant possible d’améliorer les performances de SpaCy en corrigeant les erreurs de traitement, notamment pour la reconnaissance des entités nommées (NER).
Cela dit, le « fine-tuning » de ce type de modèle reste un processus long et exige de nombreux exemples annotés (c’est-à-dire associer chaque mot à sa structure grammaticale, par exemple) pour entraîner efficacement le modèle et améliorer sa capacité à détecter les subtilités du langage.
Vous avez également un article sur le blog qui reprend les processus NLP :
https://www.codeandcortex.fr/traitement-du-langage-naturel-nlp-spacy/
Je vais examiner les possibilités d’adapter le script à Camembert.
… à suivre …
[…] Un grand classique dans SpaCy, mais avec BERT, cela se complique quelque peu. […]